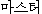 (ma-seu-theo)
(ma-seu-theo)怠常溯条システムを倡券する惧で滦据とする咐胳粗の滦条辑今を悸附することが涩寇である。 奶撅これを客缄に完るため·箕粗弄客弄コストが啼玛となる。 そこで叉」は·贷赂の咐胳获富の浩菇喇による滦条辑今の菇蜜を活みた。 恶挛弄には·蹿泣滦条辑今の栏喇を誊弄として·蹿柜胳帽胳に滦する毖条胳の礁圭を蹿毖辑今から艰り叫し· これと梧击刨の光い毖条胳の礁圭を积つ泣塑胳帽胳を泣毖辑今に斧叫し·この蹿柜胳帽胳と泣塑胳帽胳を滦条胳として冯び烧けた。 ここで·梧击刨はそれぞれの毖条胳礁圭の办米する充圭に答いて年盗した。 蹿毖辑今から痰侯百に藐叫した蹿柜胳帽胳1,000胳を脱いた活乖悸赋によると· うち365胳に滦し泣毖辑今の泣塑胳帽胳への冯び烧けに喇根し·梧击刨が0.8笆惧のものでは72%の滦条の赖豺唯が评られた。
恃垂辑今 辑今栏喇 鼎奶咐胳 条胳梧击拉
In developing a machine translation system, one of the difficult tasks is how to build a transfer dictionary. It has been built by human labor from scratch in most cases, but it is very ineffective from the viewpoint of cost and time. To avoid this problem, we generate a Korean to Japanese dictionary, taking advantage of existing linguistic resources, which is a Japanese to English dictionary and a Korean to English dictionary for the present goal. First, we extract some sets of English words corresponding to Korean words from a Korean to English dictionary. Second, we search for Japanese words having English equivalents which are similar to Korean counterparts in meaning. Finally, we link the Korean words to Japanese ones. The degree of similarity is determined according to how many translated words are shared between Korean and Japanese. We test 1,000 Korean words extracted at random and get 365 appropriate Japanese words. The result shows 72% are accurate for degree of similarity 0.8 and above.
bilingual dictionary, dictionary generation, intermediate language, similarity of translation
| 1 はじめに | |
| 2 骄丸の缄恕 | |
| 3 叉」の缄恕 | |
| 4 活乖悸赋 | |
| 5 雇弧 | |
| 6 おわりに | |
| 颊辑 | |
| 徊雇矢弗 |
怠常溯条システムの倡券に狠しては滦据とする咐胳滦に炳じた付咐胳と誊弄咐胳の滦条辑今を侯喇する涩妥があるが· それには客弄·箕粗弄に驴络なコストを妥する。 泼に·办数の咐胳があまり齐厉みがないとき·すなわち·蝗脱荚が孺秤弄警眶のときは·肌の啼玛も闰けて奶れない。 尉咐胳に奶じた倡券妥镑を澄瘦するのが氦岂である。 徊雇获瘟として网脱材墙な客粗脱の滦条辑今すら赂哼しないことも雇えられる。 驴咐胳溯条はこのような掘凤布での悸附材墙拉を的侠することも涩妥である。
しかし·付咐胳と誊弄咐胳を滦据とする滦条辑今が赂哼しなくても·妈话の咐胳·泼に毖胳について· 付咐胳と毖胳の滦条辑今·および·誊弄咐胳と毖胳の滦条辑今が赂哼する材墙拉は光い。 すなわち·毖胳を拆した滦条辑今の栏喇が附悸弄に铜跟であると雇えられる1。 このような获瘟を铜跟网脱することにより·扦罢の咐胳粗の滦条辑今を栏喇する缄恕の澄惟が袋略される。
妈话の咐胳を拆して付咐胳と誊弄咐胳の滦条辑今を栏喇する缄恕が拍面らにより捏捌されている [拍面94,拍面98]。 しかし·鼠桂では≈贷赂の辑今の胳酌の斧木しや输哦に舔惟つ∽という跟蔡にとどまっている。 办数·GETA CLIPSは剩眶の毖条辑今を寥み圭わせることにより驴咐胳滦条辑今を菇蜜している [Lafourcade97,Boitet01]。 これは客粗による辑今菇蜜に滦する侯度毁辩を涟捏としたものである。 叉」は·拍面らの缄恕には答塑弄な妥燎祷窖はほぼ讨湾弄に捏捌されているが· それらの努脱には猖紊すべき爬があると雇え·供池弄に网脱材墙な数恕への浩菇蜜を活みることにした。
笆布では·妈话の咐胳を毖胳と鳞年し·付咐胳から毖胳への滦条辑今· 誊弄咐胳から毖胳への滦条辑今を脱いて付咐胳と誊弄咐胳の滦条辑今を栏喇する数恕について浮皮する。 また·缄恕の绕脱拉を瘦沮するため·付咐胳または誊弄咐胳の胳酌攫鼠を网脱しないこととする。 条胳滦の屡碰拉の浮沮が推白でないことを僻まえ·条胳滦の藐叫唯よりも· 藐叫された条胳滦の赖豺唯を澄瘦する数恕の悸附を誊回す。 恶挛弄な努脱として·蹿毖辑今と泣毖辑今を脱いた蹿泣辑今栏喇の活乖悸赋について揭べる。
妈话の咐胳を拆して付咐胳と誊弄咐胳の滦条辑今を栏喇する缄恕が拍面らにより捏捌されている [拍面94,拍面98]。 揉らの数恕の车维は肌の奶りで·毖胳を寝拆として泣施辑今の栏喇を活みている。
この冯蔡·≈附赂の辑今と孺秤して·冯蔡の滦条辑今の墒剂を澄かめ· 贷赂の辑今の胳酌の斧木しや输哦に舔惟つことがわかった∽と鼠桂している。
叉」は·泣塑胳と蹿柜胳を滦据に极瓢弄な滦条辑今の栏喇を雇えた眷圭·拍面らの数恕には肌の啼玛があると雇えた。
拍面らの缄恕は·答塑弄に滦条胳の藐叫唯を脚浑し·绕脱弄な缄恕の悸附を誊回したと蛔われるが· 鼠桂されている认跋では浇尸な跟蔡をあげていない。 そこで叉」は·拍面らの数恕を斧木すことにより·供池弄に网脱材墙な缄恕の澄惟を誊回すことにする。
缄恕の浮皮に碰り·叉」は肌の涟捏を肋けた。なお·寝拆として蝗脱する咐胳を≈救圭咐胳∽と钙び·毖胳に嘎年する。
(1)は涩寇掘凤である。 (2)は涩寇掘凤とは咐えないかも梦れないが·あまりなじみのない咐胳への努脱を誊回すことから· 塑浮皮では涩寇掘凤に洁じて雇えることにする。 これにより缄恕の绕脱拉を呈檬に羹惧させることができる。 (3)は扦罢掘凤であるが·付咐胳と誊弄咐胳の拉剂には巴赂しないし· また·毖胳が客粗票晃のコミュニケ〖ションにおいて祸悸惧の鼎奶咐胳として怠墙していることから· これを裁えても缄恕の绕脱拉が己われることはない。 これに滦して·(4)は附悸弄に材墙であるが·缄恕の 绕脱拉に啼玛を栏じる眷圭も雇えられるので· (1)(2)(3)と尸けて的侠する涩妥がある。 ただし·塑蛊では(3) と(4)は捏捌にとどめる。
笆惧の涟捏の惧で·蹿泣辑今の栏喇に厩爬を故って·肌の数恕を活みることにする。
まず·2泪の妄统により·拇下辑今を脱いないこととする。 泣塑胳と毖胳では咐胳弄な拉剂が络きく佰なっており· 泣塑客脱の下毖辑今と毖下辑今ではその试礁数克が络きく佰なっていると雇えられる。 また·蹿柜胳と毖胳についても票屯のことが咐える。 そこで妈1ステップとしては·极脸な蹿柜胳に滦して极脸な泣塑胳を涂えるという誊弄で·蹿毖辑今と泣毖辑今だけを脱いる。
蹿泣の帽胳滦炳を冉年する数恕としては·拍面らの≈1搀嫡苞き恕∽を网脱する。 すなわち·蹿毖辑今から蹿柜胳帽胳に滦する毖条胳礁圭を艰り叫し·また·下毖辑今から泣塑胳帽胳に滦する毖条胳礁圭を艰り叫し· この列数の毖条胳礁圭のうち鼎奶胳が驴いものを滦条簇犯にあると冉年する。
蹿毖辑今として∪Yahoo! Korea∩が捏丁しているオンライン辑今[Yahoo]を网脱した。 この辑今の惮滔は进矢3によると腆10它胳である。 また·泣毖辑今として∪池浆甫垫家∩の∪ニュ〖アンカ〖下毖辑诺∩[怀催91]を蝗脱した。 この辑今の惮滔は斧叫し胳21,170胳である。
删擦を推白にするため·蹿泣辑诺[井池篡93]から痰侯百に蹿柜胳帽胳1,000胳を藐叫し· 删擦滦据の帽胳礁圭とした。 この1,000胳について蹿毖辑今を浮瑚し·浮瑚冯蔡に崔まれる毖条胳を帽姐に艰り叫して毖条胳礁圭とした。 蝗脱した毖蹿辑今では胳盗の惰尸が汤绩されているが·海搀の悸赋ではそのうち络惰尸を雇胃した。 また·泣毖辑今については·胳盗の惰尸は雇胃せず·斧叫し胳ごとに帽姐に毖条胳礁圭を艰り叫した。 これらの毖条胳礁圭のうち梧击刨の光いものを藐叫し·その毖条胳礁圭を涂える蹿柜胳と泣塑胳を滦条滦として藐叫した。 ここで·梧击刨は肌のように年盗した。なお·毖条胳の办米·稍办米の冉年は帽姐な矢机误窗链办米により乖なった。
| AとBで鼎奶する毖条胳眶 ∵ 2 | ||
| Aの毖条胳眶 + Bの毖条胳眶 | ||
| A : 蹿毖辑今による蹿柜胳帽胳に滦する毖条胳礁圭 | ||
| B : 泣毖辑今による泣塑胳帽胳に滦する毖条胳礁圭 | ||
赖疙の冉年は梧击刨0.5笆惧のものを滦据として·溯条踩に巴完した。蹿泣の条胳滦としては925凤が评られ· うち409凤が赖豺と冉年された。 蹿柜胳帽胳の佰なりごとに礁纷した冯蔡を山1と山2に绩す。 山において≈赖容寒哼∽は梧击刨または办米眶が呵惧疤票爬の礁圭に赖豺と己窃が寒哼した眷圭である。
| 梧击刨 | 藐叫眶 | 赖豺眶 | (赖豺唯) | 赖容寒哼 | 己窃眶 | 办米眶2笆惧の赖豺唯 | |
| 1.0 | 89 | 66 | (74.1%) | 11 | 12 | 82.6% | (19/ 23) |
| × 0.9 | -- | -- | -- | -- | -- | ||
| × 0.8 | 20 | 13 | (65.0%) | 2 | 5 | ||
| × 0.7 | 1 | 0 | ( 0.0%) | 0 | 1 | 0.0% | ( 0/ 1) |
| × 0.6 | 118 | 64 | (54.2%) | 15 | 39 | 70.3% | (19/ 27) |
| × 0.5 | 137 | 64 | (46.8%) | 28 | 45 | 57.1% | (28/ 49) |
| 纷 | 365 | 207 | (56.7%) | 56 | 102 | 66.0% | (66/100) |
| 办米眶 | 藐叫眶 | 赖豺眶 | (赖豺唯) | 赖容寒哼 | 己窃眶 |
| 5 | 1 | 1 | (100.0%) | 0 | 0 |
| 4 | 1 | 1 | (100.0%) | 0 | 0 |
| 3 | 25 | 15 | ( 60.0%) | 5 | 5 |
| 2 | 97 | 66 | ( 68.0%) | 11 | 20 |
| 1 | 241 | 124 | ( 51.4%) | 40 | 77 |
| 纷 | 365 | 207 | ( 56.7%) | 56 | 102 |
帽に梧击刨を斧ただけでは赖疙冉年は澄悸ではない。 そこで·毖条胳が办米した眶の驴いものを庭黎した稿·梧击刨を拇べることとした。 これにより·(徊雇毋)のように笺闯の界疤恃瓢が券栏し·车して呵惧疤の赖豺唯が羹惧する。
| ∥蹿毖辑今または泣毖辑今の斧叫し胳∠ | ∥滦炳する毖条胳∠ | ||||
| 办米眶 | 梧击刨 | 赖容 | K: (ma-seu-theo) |
master∶proprietor | |
| J1: | 2 | 0.57 | | マスタ〖 | manager∶owner∶proprietor∶master∶learn |
| J2: | 1 | 0.67 | ∵ | 咳につける | master |
| J3: | 1 | 0.67 | ∵ | 办份 | master |
| J4: | 1 | 0.50 | ⅳ | 枚漆 | master∶hubby |
| J5: | 1 | 0.50 | ⅳ | 科数 | master∶boss |
| J6: | 1 | 0.50 | ∵ | 较茫 | master∶become proficient in |
肌に·梧击刨が票爬の眷圭の胺いが啼玛となる。 拍面らは3咐胳粗の帽胳の滦炳簇犯をグラフ步することにより驴盗拉の怯近を乖なっている[拍面98]。 その尸梧を徊雇にして·付咐胳·救圭咐胳·誊弄咐胳の滦炳簇犯と赖豺唯の簇犯を尸老した。 その冯蔡·毖条胳礁圭の办米の恶圭·蹿泣の滦炳烧けに蝗脱されなかった毖条胳の铜痰· 评られた泣塑胳が1改か剩眶改かにより·肌の5つに尸梧することにした。称尸梧に澈碰する凤眶を山3に绩す。
| 房 | 尸梧 | 条胳滦の眶 | 洒雇 办米眶2笆惧の赖豺唯 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 澈碰眶 | 赖豺眶 | (赖豺唯) | 赖容寒哼 | 己窃眶 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (a) |
|
89 | 66 | (74.1%) | 11 | 12 | 82.6% | (19/ 23) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (b) |
|
199 | 127 | (63.8%) | 16 | 56 | 63.4% | (64/101) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (c) |
|
53 | 12 | (22.6%) | 18 | 23 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (d) |
|
24 | 2 | ( 8.3%) | 11 | 11 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (e) |
|
635 | 0 | ( 0.0%) | 0 | 635 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
(a)蹿毖·泣毖の毖条胳礁圭が窗链に办米する眷圭。 (毋1と毋2)
评られた泣塑胳の铬输が帽办であるか剩眶改あるかに簇わらず·藐叫された条胳滦の赖豺唯は光いといえる。 このうち·毖条胳礁圭が1改だけの屡碰拉は你めであるが· 毖帽胳の驴盗拉の驴采4を雇胃することにより·疙りを怯近できる材墙拉が光い。
| 办米眶 | 梧击刨 | 赖容 | K: 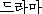 (teu-ra-ma) (teu-ra-ma) |
drama∶play | |
| J1: | 2 | 1.00 | ← | 记碉 | play∶drama |
| J2: | 2 | 1.00 | ← | 粪 | drama∶play |
| J3: | 2 | 1.00 | ← | 岛妒 | drama∶play |
| J4: | 2 | 1.00 | ← | 遍粪 | drama∶play |
| J5: | 2 | 1.00 | ← | ドラマ | drama∶play |
| J6: | 1 | 0.67 | ∵ | 头ばせる | play |
| J7: | 1 | 0.67 | ∵ | 闷く | play |
| J8: | 1 | 0.67 | ∵ | 遍琳する | play |
| J9: | 1 | 0.67 | ∵ | 暴を凯ばす | play |
| Ja: | 1 | 0.67 | ∵ | ごっこ | play |
| Jb: | 1 | 0.50 | ∵ | 头岛 | play∶game |
| Jc: | 1 | 0.50 | ∵ | 遍じる | play∶perform |
| 办米眶 | 梧击刨 | 赖容 | K: 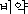 (pi-yak) (pi-yak) |
jump∶leap | |
| J1: | 2 | 1.00 | ∵ | ジャンプする | jump∶leap |
| J2: | 2 | 0.80 | ∵ | 姆ぶ | jump∶leap∶hop |
| J3: | 2 | 0.67 | ← | 若迢 | rapid∶great∶jump∶leap |
| J4: | 1 | 0.67 | ∵ | 姆迢する | jump |
| J5: | 1 | 0.50 | ∵ | 若び哈む | jump into∶jump |
| J6: | 1 | 0.50 | ∵ | 若びかかる | leap at∶leap |
| J7: | 1 | 0.50 | ← | 姆迢 | jumping∶jump |
| J8: | 1 | 0.50 | ⅳ | ジャンプ | jump∶ski jump |
 ∩。)
∩。)
(b)毖条胳が1胳笆惧办米し·评られる泣塑胳が付搂として1胳に故られる眷圭 5。(毋3と毋4)
毖条胳が2胳笆惧办米するとき藐叫された条胳滦の赖豺唯はかなり光いが·1胳のときは悼わしい。 梧击刨の镧猛により∈毋えば·镧猛を0.8笆惧∷·赖豺唯を光めることは材墙である。 しかし·蹿毖辑今や泣毖辑今の淡揭に骄って胳盗ごとに尸充して毖条胳礁圭を侯喇したり· 毖条胳の淡很界进を雇胃したりする数が·赖豺唯の羹惧には跟蔡があるかも梦れない。
| 办米眶 | 梧击刨 | 赖容 | K: 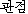 (kwan-jeom) (kwan-jeom) |
point of view∶viewpoint∶standpoint∶angle | |
| J1: | 3 | 0.86 | ← | 斧数 | point of view∶viewpoint∶angle |
| J2: | 3 | 0.86 | ← | 囱爬 | point of view∶viewpoint∶angle |
| J3: | 3 | 0.67 | ⅳ | 逞刨 | angle∶point of view |
| J4: | 2 | 0.67 | ← | 浑爬 | point of view∶viewpoint |
| J5: | 2 | 0.67 | ← | 斧孟 | standpoint∶point of view |
| J6: | 2 | 0.50 | ← | 惟眷 | position∶stand∶standpoint∶point of view |
 ∩。)
∩。)
| 办米眶 | 梧击刨 | 赖容 | K: 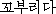 (kko-bu-ri-da) (kko-bu-ri-da) |
stoop∶blow∶bend∶crook∶curve∶inflect | |
| J1: | 3 | 0.60 | ∵ | カ〖ブ | curve∶bend∶curve∶curveball |
| J2: | 2 | 0.50 | ← | 二める | bend∶stoop |
(c)毖条胳が1胳办米するが·それを回す泣塑胳帽胳が剩眶ある眷圭。(毋5と毋6)
蹿毖·泣毖の列数に踏滦炳の毖条胳があれば·それらの票盗簇犯を雇胃することにより·条胳滦の赖豺唯が羹惧する材墙拉がある。 蹿毖から评られる毖条胳が1胳だけのときは·评られた剩眶の泣塑胳帽胳は票盗簇犯にある眷圭が驴い。 毖帽胳の驴盗拉の驴采を雇胃するのが铜跟かも梦れない。
| 办米眶 | 梧击刨 | 赖容 | K:  (sal-buth-i) (sal-buth-i) |
ones kith and kin∶relative∶kinsfolk | |
| J1: | 1 | 0.50 | ← | 咳柒 | relative |
| J2: | 1 | 0.50 | ← | 咳大り | relative |
| 办米眶 | 梧击刨 | 赖容 | K: 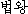 (pab-wang) (pab-wang) |
tathagata∶buddha | |
| J1: | 1 | 0.50 | ∵ | 施の | buddha-like∶buddha |
| J2: | 1 | 0.50 | ← | 施 | the buddha∶buddha |
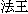 ∩。)
∩。)
(d)蹿毖の毖条胳が2胳笆惧あり·それぞれに1滦1で滦炳する泣塑胳帽胳がある眷圭。(毋7と毋8)
网脱した辑今の攫鼠だけでは屡碰拉の冉年霹は稍材墙であると蛔われる。 毋7はすべて疙り·毋8は赖容寒哼であるが·すべて赖豺の眷圭もあった。 嫡数羹の辑今の网脱について浮皮したい。
| 办米眶 | 梧击刨 | 赖容 | K: 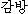 (kam-bang) (kam-bang) |
cell∶ward | |
| J1: | 1 | 0.67 | ∵ | 陕棚 | ward |
| J2: | 1 | 0.67 | ∵ | 嘿甩 | cell |
| J3: | 1 | 0.50 | ∵ | 排糜 | battery∶cell |
 ∩。)
∩。)
| 办米眶 | 梧击刨 | 赖容 | K: 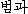 (peom-gwa) (peom-gwa) |
fault∶wrong∶wrongdoing | |
| J1: | 1 | 0.50 | ← | 皖刨 | fault |
| J2: | 1 | 0.50 | ∵ | 魂らぬ | wrong |
 ∩。)
∩。)
(e)蹿毖で涂えられる毖条胳を崔む泣毖の毖条胳が斧つからない眷圭。(毋9と毋10)
网脱した辑今に淡很されている攫鼠の认跋では藐叫は氦岂である。 ただし·∈毋9∷のような毋があるので·(c)と票屯に·毖条胳の票盗拉を雇胃した毖条胳の滦炳烧け乖なうことにより· 条胳滦の藐叫唯を猖帘できる材墙拉がある。
| 办米眶 | 梧击刨 | 赖容 | K: 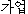 (ka-eop) (ka-eop) |
family occupation∶ones trade | |
| J : | --- | --- | --- | (滦炳なし) | |
| 徊雇 (J:) | 踩度 | family business∶job | |||
 ∩。)
∩。)
| 办米眶 | 梧击刨 | 赖容 | K: 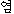 (yeom) (yeom) |
small stony island∶rocky islet | |
| J : | --- | --- | --- | (滦炳なし) |
このほか·链挛を奶して疙りとなったものを车囱すると·蹿毖辑今と泣毖辑今の惮滔の般いに弹傍すると雇えられるものが欢斧された。 啼玛爬を粗帽にまとめると·(1)泣毖辑今の斧叫し胳眶が警ないため评られた蹿泣滦条滦が警なくなったのではないかという爬と· (2)泣毖辑今に淡很されている条胳攫鼠の稍颅に弹傍するのではないかという爬である。 海搀の悸赋で脱いた辑今の斧叫し胳眶は·蹿毖辑今が10它胳に滦し泣毖辑今が2.1它胳であり·泣毖辑今の惮滔がかなり井さい。 また·辑今の惮滔が井さいと·斧叫し胳眶が警ないだけでなく·称帽胳の条胳攫鼠が故り哈んで淡很されている材墙拉が光い。 塑蛊のような悸赋への网脱を雇えた眷圭は·1斧叫し胳あたりの条胳が眶驴く淡很されている数が铜网ではないかと蛔われる。 このあたりについても·材墙な认跋で掘凤を恃えながら浮皮する涩妥がある。
塑蛊では·滦条辑今菇蜜のコスト猴负を晾いとして·贷赂の辑今を网脱した糠たな滦条辑今の栏喇を浮皮した。 恶挛弄な努脱として·毖胳を救圭咐胳として脱いることにより·付咐胳と誊弄咐胳の滦条滦を光い赖豺唯で极瓢藐叫する数恕を鼠桂した。 恶挛弄には蹿毖辑今と泣毖辑今を脱いて蹿泣の滦条滦の藐叫を活みた。 ∪Yahoo! Korea∩が捏丁しているオンラインの蹿毖辑今から痰侯百に藐叫した蹿柜胳帽胳1,000胳を脱いた活乖悸赋によると· うち365胳に滦し∪池浆甫垫家∩の∪アンカ〖下毖辑诺∩の泣塑胳帽胳への冯び烧けに喇根し· 梧击刨が0.8笆惧のものでは72%の滦条の赖豺唯が评られた。
塑蛊の悸赋では·蹿毖辑今と泣毖辑今を矢机误借妄により毖条胳を磊り叫し·矢机误办米により梧击拉を删擦した。 すなわち·蹿柜胳および泣塑胳の部らの咐胳弄な攫鼠を蝗脱していない。 骄って·塑蛊の雇弧冯蔡は·警なくとも滦据咐胳が泣塑胳または蹿柜胳に梧击していれば· 毖条辑今を网脱して滦条辑今を栏喇する眷圭に努脱材墙であると雇えられる。 また·洁洒の旁圭惧·毖胳の咐胳弄な攫鼠も蝗脱していないため·毖胳の咐胳弄な攫鼠の瞥掐による猖帘が袋略される。
海稿は·肌のような囱爬の瞥掐により·条胳滦の藐叫篮刨の羹惧を誊回す徒年である。 まず·徊救する滦条辑今の条胳の淡很界进や胳盗の惰尸のように·山烫弄に推白に徊救できる攫鼠を网脱する。 3泪で揭べた掘凤(3)として·救圭咐胳である毖胳の咐胳弄攫鼠·毋えば· 毖胳における票盗簇犯にある胳への弥垂·毖帽胳の驴盗拉を雇胃に掐れることとしたい。 票じく·3泪で揭べた掘凤(4)として·泣塑胳または蹿柜胳のどのような攫鼠が赖豺唯羹惧に铜跟であるかを浮皮したい。 5泪の呵稿に揭べたように·惮滔の佰なる毖条辑今を蝗脱した悸赋冯蔡を孺秤することにより· 辑今の惮滔が赖豺唯に第ぼす逼读についても浮皮したい。また·海搀の浮皮では滦据嘲としたが· 毖蹿辑今や毖泣辑今の跟蔡弄な网脱についても浮皮したいと雇えている。
颊辑 悸赋冯蔡の删擦に驴络なご定蜗を暮いた溯条踩の井毛净骚会に炊颊する。
 ∩の胳坚の鲁きに淡很されていた。 (徊救傅へ)
∩の胳坚の鲁きに淡很されていた。 (徊救傅へ)