大語彙かつ多様な表現の扱える音声翻訳を目指して、 新聞記事など書き言葉の機械翻訳と会話文など話し言葉の機械翻訳の扱う内容の違いに関する実際的かつ定量的な調査分析を実施した。 まず、語彙的な特性に関する数値情報を報告する。 次に、用言と格要素相当語句から構成される基本構文表現の日英対訳に関する数値情報を報告する。 さらに、技術の現状を把握するための事例研究として、 ATR音声翻訳通信研究所で構築された日英音声翻訳システムATR-MATRIXが扱えている範囲を論じる。
In order to develop a speech translation system that has a large vocabulary and accepts various expressions, we have carried out a practical and quantitative investigation of similarities and differences among the tasks of machine translation for written language such as newspaper articles, and those for spoken language such as conversations in daily life. First, we mention the characteristics of vocabularies for colloquial expressions in conversations. Next, we report the characteristics of basic sentence patterns which consist of one predicate and essential case phrases from the viewpoint of translation from Japanese to English. Finally, we discuss state-of-the-art technology based on a case study of a Japanese-to-English speech translation system ATR-MATRIX built by ATR Interpreting Telecommunications Research Laboratories.
| 1 まえがき | |
| 2 分析調査対象 | |
| 2.1 バイリンガル旅行会話コーパス | |
| 2.2 日本語語彙大系 | |
| 3 旅行会話に現れた会話特有の語彙 | |
| 4 旅行会話に現れた会話特有の基本構文表現 | |
| 5 議論および今後の課題 | |
| 5.1 音声翻訳システムの現状 | |
| 5.2 今後の課題 | |
| 6 むすび | |
| 謝辞 | |
| 参考文献 |
現在の音声翻訳は、限定されたタスクへの適用を想定し、比較的小規模の語彙(約13,000語)と、 表現の種類をある程度限定して翻訳実験を行なっている[1,2,3]。 音声翻訳の適用範囲の拡大を目指すには、大語彙、多様な表現、分野適応性の問題を解決する必要がある。 新聞記事等の書き言葉向きの機械翻訳システムは音声翻訳システムに比較して大語彙を扱っているが、 テキストの翻訳と会話の翻訳は違った難しさがあるという指摘[4]がある。 会話文など話し言葉向きの機械翻訳システムの研究[5]はあるものの、 書き言葉向きの機械翻訳システムとは別に研究がなされており、 会話文など話し言葉の機械翻訳とテキストなど書き言葉の機械翻訳の扱う内容の違いに関する分析調査は これまで十分になされていなかった。
近年NTTが構築した産業経済記事など記述文を対象とする日英機械翻訳システムALT-J/E[6]の意味辞書の一部が 「日本語語彙大系」として出版され[7]、そのCD-ROM版[8]も利用できるようになった。 一方、ATR音声翻訳通信研究所が収集した 「バイリンガル旅行会話コーパス」[9,10]も広く公開されている。
実際的かつ定量的な調査分析データは 書き言葉向きの機械翻訳システムで会話調の話し言葉を扱う際の指針や有益な知見を与えるものと期待できる。 そこで、機械処理可能な大語彙辞書である日本語語彙大系を用いて電子化されたバイリンガル旅行会話コーパスの特徴分析を試みた。 まず、コーパスに含まれる単語を抽出し、それらが日本語語彙大系の単語体系に含まれているか調査した[11]。 次に、用言と格要素相当語句から構成される基本構文表現を抽出し、 それらが日本語語彙大系の構文体系に含まれているか、含まれているならばさらに英訳の妥当性を調査した。 書き言葉向きの大語彙辞書を対照データとすることで、会話特有の語彙、単語の連結により構成される表現の特徴を検討する。 本稿では、それらの数値情報を報告するとともに、音声翻訳システムの現状について議論する。
2で分析調査対象であるバイリンガル旅行会話コーパスと日本語語彙大系の概要について述ベる。 3で旅行会話に現れた会話特有の語彙について述べる。 4で旅行会話に現れた会話特有の基本構文表現について述べる。 5で音声翻訳システムの技術の現状について議論する。 最後に6で全体をまとめる。
ATR音声翻訳通信研究所では音声翻訳研究のために バイリンガル旅行会話コーパス[9,10]を構築した。 良質で大量の基礎資料を得るため、通訳者を介したバイリンガル会話を収集した。 また実用性を考えて、タスクとしては多くの人に利用可能なホテル予約を中心とした旅行会話を選んだ。 旅行会話は日本語話者、英語話者と日英方向、英日方向の2名の通訳者の合計4名によってなされる。 話者の一方はホテルのフロント係であり、他方は外国人の旅行客である。 2名の通訳者は音声翻訳システムの代りとして振る舞う。 具体的には、話者の1回の発話は10秒以内とし、相手が話している間に割り込むことは禁止した。 そして、通訳者はそのような1回の発話毎に逐次的に通訳を行なう。 このような制約を設けることにより、極端に長い発話や発話の重なりを避けることができるため、 「近未来の音声翻訳システム」研究の基礎資料として適していると判断できた。 表1にバイリンガル旅行会話コーパスの概要を示す。 関連情報は http://results.atr.co.jp/products/ をご覧いただきたい。
| 収集会話数 | 618 |
| 異なり話者数 | 71 |
| 異なり通訳者数 | 23 |
| 発話総数 | 16,107 |
| 日本語形態素延べ数 | 301,961 |
NTTでは、産業経済記事など記述文を対象とする日英機械翻訳システムALT-J/E[6]を実現し、 その意味辞書の一部が日本語語彙大系として出版されている[7]。 日本語の語彙30万語を3,000種類の意味属性で分類し、さらに6,000語の用言には日英の文型14,000パターンが付与されている。 表2に日本語語彙大系のうち本稿で調査対象とした項目の概要を示す。 分析調査にはそのCD-ROM版[8]および必要に応じて適宜ALT-J/E[6]の辞書情報を活用した。 関連情報は http://www.kecl.ntt.co.jp/icl/mtg/resources/GoiTaikei/ をご覧いただきたい。
| 収録データ | 件数 |
| 単語体系 | 30万語 |
| 構文体系 | 6,000用言 14,000文型 |
バイリンガル旅行会話コーパスのうち日英方向の発話を対象に、単語の抽出と頻度のカウントを行なった[11]。 助詞「の」の例を図1に示す。 記号 | で区切られた項目は左から順に「表記形」「読み」「標準形」「品詞」を表し、( )内の数値が出現頻度である。
| 表記形 | 読み | 標準形 | 品詞 | (出現頻度) |
| の | ノ | の | 格助詞 | (69) の | ノ | の | 終助詞 | (4) の | ノ | の | 準体助詞 | (337) の | ノ | の | 連体助詞 | (4135) |
表3に助詞の例を示すように、旅行会話コーパスの品詞体系[12]は日本語語彙大系やALT-J/Eの辞書情報とは異なる。 そこで、その違いを考慮して、表3の( )内に記すように、旅行会話コーパスの準体助詞は日本語語彙大系やALT-J/Eの形式名詞に、 旅行会話コーパスの係助詞は日本語語彙大系やALT-J/Eの副助詞に、旅行会話コーパスの並立助詞、連体助詞、 引用助詞は日本語語彙大系やALT-J/Eの格助詞に対応させて照合を行ない、日本語語彙大系の単語体系に基づく被覆率を調査した。
| 旅行会話コーパス | 日本語語彙大系やALT-J/E |
| 格助詞 | 格助詞 |
| 準体助詞 | なし(形式名詞) |
| 係助詞 | なし(副助詞) |
| 副助詞 | 副助詞 |
| 並立助詞 | なし(格助詞) |
| 接続助詞 | 接続助詞 |
| 終助詞 | 終助詞 |
| 連体助詞 | なし(格助詞) |
| 引用助詞 | なし(格助詞) |
図1の例では、格助詞「の」、準体助詞「の」、 連体助詞「の」は日本語語彙大系やALT-J/Eに同等とみなせる語彙項目が含まれていると判断できた。 しかし、終助詞「の」は日本語語彙大系やALT-J/Eには含まれていなかった。 したがって、異なり語数を基準とする被覆率は3/4となり、75.0%である。 延べ語数を基準とする被覆率は4541/4545となり、99.9%である。
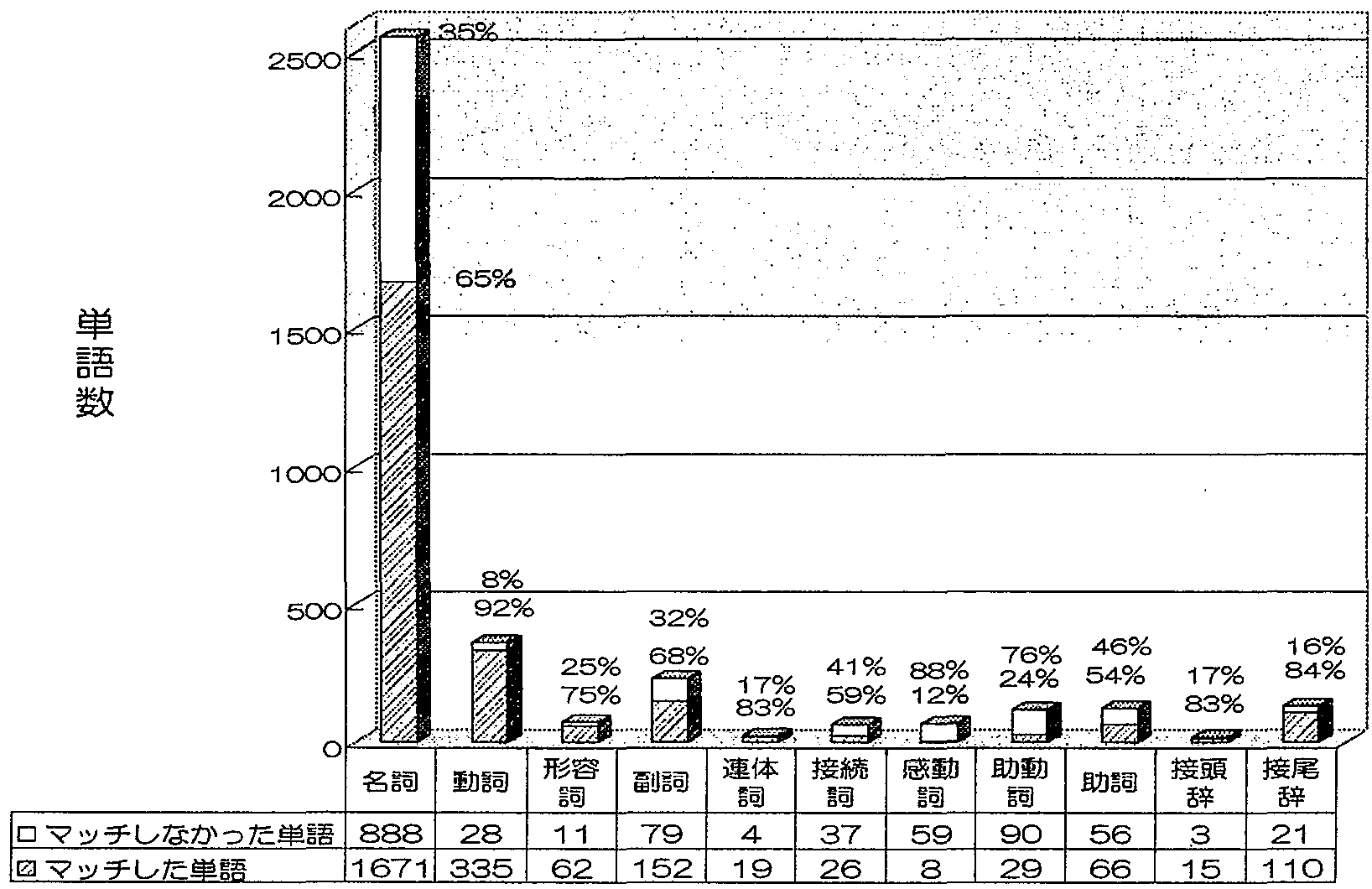
バイリンガル旅行会話コーパスには言い直し等の単語の断片が含まれており、それらは形態素の品詞に「その他」と付与されている。 また、バイリンガル旅行会話コーパスでは活用する語は語幹と語尾に分割している。 そこで、品詞「その他」「語尾」等を除き、被覆率を求めた。 結果を表4に示す。異なり語基準による品詞毎の被覆率を図2に示す。
| 延べ語数 | 異なり語数 | |
| 含まれるもの | 80,685 | 2,493 |
| 含まれないもの | 18,828 | 1,269 |
| 被覆率 | 81.1% | 66.3% |
|
|
日本語語彙大系の単語体系が含まない単語は大きく二つに分類できる。 一つは会話調の話し言葉特有の表現であり、もう一つは旅行という分野に依存する語彙である。 それぞれの例を次に示す。
日本語語彙大系の単語体系に含まれない単語のうち、名詞類が異なり語数で888語、延べ語数で7、261語を占める。 大まかに名詞類がすべて旅行という分野に依存する語彙であると近似すれば、 日本語語彙大系の単語体系に含まれない単語のうち旅行という分野に依存する語彙の占める割合は、 異なり語数基準で約70%、延ベ語数基準で約40%である。 逆に、その残りが会話調の話し言葉特有の表現の占める割合である。
バイリンガル旅行会話コーパスのうち日英方向の発話を対象に、用言と格要素相当語句から構成される基本構文表現の抽出を行なった。 いわゆる「ダ文」は会話調の言い回しに多用される。 その事例の一部を図3に示す。内容項目は左から順に出現頻度、日本語構文、英語構文である。 出現頻度は日本語構文と英語構文のペアを単位として求めた。 日本語構文はダ文表現と格要素相当語句から構成される。 ダ文表現の前後を / で囲んで示し、ダ文の「だ」の直前に# を付与する。 「です」等の表層表現となっているものもすべて「#だ」の形で抽出した。 主題を表す係助詞「は」で格助詞「が」に置き換え可能な場合は「が((は))」と記述した。 助詞を伴わない格要素和当語句において格要素を示す助詞を補うことができる場合は * で囲んだ形式でそれを記述した。 英語構文全体は " で囲んで示し、さらに日本語のダ文表現に相当する部分を / で囲んで記述する。 英語に人称代名詞が含まれる場合はそれをoneに置き換えた。 英語構文として連結する必要はないが、日本語構文の対訳として必要な要素は、 | で区切って記述した。
| 1 / 雨 # だ / | "it /rain/" |
| 3 / 初めて # だ / | "/be/ one's first time" |
| 1 / 初めて # だ / | "/be/ one's first visit" |
| 2 / 初めて # だ / | "/be/ the first time" |
| 1 奈良が((は)) / 初めて # だ / | "this /be/ one's first trip | to Nara" |
| 1 着物が((は)) / 初めて # だ / | "/be/ one's first time | to put kimono on" |
| 1 着物が((は)) / 初めて# だ / | "/be/ one's first time | wearing a kimono" |
| 1 それは / お困り # だ / | "that /be/ a problem" |
| 1 バスを / ご利用 # だ / | "/take/ the bus" |
| 1 こちらが / チケット # だ / | "here /be/ one's tickets" |
| 1 サービス料 * が */ 込み # だ / | "/include/ service charges" |
| 1 東京成田空港を / 出発 # だ / | "/leave/ Tokyo Narita Airport" |
| 1 一つ目が / 東寺駅 # だ / | "the first stop /be/ Toji Station" |
| 1 茶室が / 入り用 # だ / | "/need/ a tearoom" |
| 3 / ご存じ # だ / | "/know/" |
| 6 / お泊まり # だ / | "/stay/" |
同様にして動詞等の一般的な用言とその格要素相当語句から構成される基本構文表現も抽出した。 得られた数値情報を表5に示す。 延べ基準でも異なり基準でも割合は大きく変わらないため、異なり基準の数字のみ示す。
| 一般 | ダ文 | |||||
| 個数 | 割合 | 個数 | 割合 | |||
| 英訳妥当 | 327 | 9.1% | 1 | 0.2% | ||
| 英訳ほぼ決まる | 1413 | 39.5% | 173 | 26.1% | ||
| 訳し分け必要等 | 1840 | 51.4% | 488 | 73.7% | ||
| 合計 | 3580 | 100.0% | 662 | 100.0% | ||
動詞等の一般的な用言とその格要素相当語句から構成される基本構文表現に対して、 日本語語彙大系の構文体系で妥当な英訳が得られるものは全体の約1割であった。 例えば「地下鉄烏丸線に乗る」という表現で「地下鉄烏丸線」が鉄道であることがわかれば 妥当な英訳“/take/ the Karasuma subway line”が得られる。 残りの約9割は日本語語彙大系の構文体系では妥当な英訳が得られない。 しかしながら、約4割のものは英語の用言がほぼ決まるものであった。 代表的な事例は次の通りである。
さらに、英語の用言が一つに絞りきれないものは約5割あった。 代表的な事例は次の通りである。
一方、いわゆる「ダ文」については、日本語語彙大系の構文体系で妥当な英訳が得られるものは 「雨だ(it rains)」 の1例のみであった。 つまり、ほとんどすべてのものが日本語語彙大系の構文体系では妥当な英訳が得られない。 約4分の1のものは 「日本食が大好きだ(/like/ Japanese food)」 「茶室が入り用だ(/need/ a tearoom)」 「乗り換えが必要だ(/need/ to transfer)」 のように英語の用言がほぼ決まるものであった。 残りの約4分の3は 「シビックを二台だ(two Civic)」 に対して英語の用言としてrentやreserveを訳出することが適切であるとするならば、 その発話だけで適当な英語用言を訳出するのが難しい事例である。
ATR音声翻訳通信研究所で構築された日英音声翻訳システムATR-MATRIX[1]を事例として取り上げ、 音声翻訳システムの現状について考察する。 会話文の特徴と考えられる「ダ文」に対して、システムから得られる実例を次にいくつか列挙する。
「茶室が入り用です」 のように英語の用言がほぼ決まると分類できるものについては妥当な英訳が得られている。 それ以外の場合でも 「支払いはカードです」 のように頻度が多いものについては用例が整備されているものもある。 しかしながら、頻度の少ない 「シビックが二台です」 のようなものについては日本語の構文を反映した英語の構文に対して内容語を置き換えたものが出力される。
これまでの音声翻訳システムの研究では窓口業務のような場面が想定されていた。 日英双方向の音声翻訳システムを用いた対話実験では、音声認識や翻訳に若干の誤りがあっても、 発話者の再発話や相手からの確認質問によって、与えられた課題は達成できることが確認されている[3]。 発話全体が翻訳できない場合でも翻訳可能な部分を翻訳する部分翻訳機能[13]が有効であるのは、 窓口業務のような場面で協調的な応答が期待できる場合にはキーワードがわかるだけでも助かる状況があるためである。
しかしながら、大語彙かつ多様な表現の扱える音声翻訳を目指すならば、キーワードが伝わるだけでは不十分な状況が考えられる。 会話文を対象とするとしても、構内アナウンスのように相手からの碓認が期待できない場合には品質の良い翻訳が必須となる。 したがって、一般的な用言の約5割、「ダ文」の約4分の3を占める訳し分けが必要な基本構文表現については、 翻訳の品質を高める必要がある。
基本構文表現を抽象化することにより汎用性の向上が期待できるため、 会話文の日英翻訳のための文型辞書として整備する計画である。
また、表4において、異なり語数に対する被覆率より延べ語数に対する被覆率が高いことから、 限定した領域を想定すれば、そこに現れる語彙は絞れる可能性があるといえる。 しかし、表5の基本構文表現は、異なり基準でも延ベ基準でも割合が大きく変わらなかった。 つまり、語彙は絞れたとしても、その組合わせである基本構文表現は絞りきれない、 あるいは、まだコーパスの量が十分でないという解釈ができる。 そのため、対訳コーパスの稠密度を把握する手段を検討する予定である。
NTTが書き言葉を対象として構築した大語彙辞書である日本語語彙大系を用いて ATR音声翻訳通信研究所が収集したバィリンガル旅行会話コーパスの特徴分析を行なった。 テキストの翻訳と会話の翻訳は違った難しさがあるという定性的ないし思索的な指摘はあったが、 会話文など話し言葉の機械翻訳とテキストなど書き言葉の機械翻訳の扱う内容の違いに関する分析調査は これまで十分になされていなかった。 そこで、機械処理可能な大語彙辞書や電子化されたバイリンガル会話コーパスが公開されたことを背景に、 実際的かつ定量的な調査分析を試みた。 このような調査分析は書き言葉向きの機械翻訳システムで会話調の話し言葉を扱う際の指針や有益な知見を与えるものと期待できる。
分析作業に協力いただいたNTTアドバンステクノロジ株式会社サービスシステム事業部言語処理システム部の皆様に感謝する。