| 概要 | |
| 1 動機と提案の概略 | |
| 2 翻訳機構 | |
| 2.1 原言語換言部 | |
| 2.2 変換部 | |
| 2.3 目的言語換言部 | |
| 3 訳語選択に対する方針 | |
| 4 まとめ | |
| 参考文献 |
単言語処理に処理の重点を移し、原言語と目的言語の双方で換言処理(paraphrasing)を行なうことで 変換処理の貞荷を最小限に抑えた音声翻訳システムSANDGLASSの基本設計を述べ、翻訳方式の議論を行なう。
英語が翻訳対象言語でない場合、例えば中国語と日本語の間での音声翻訳について述べる。 これらの言語間においては日英や英日とは異なり対訳コーパス(bilingual corpus)の入手は容易ではないため、 対訳コーパスを利用した翻訳手法は有力な手法とは言えない。 特に音声翻訳の場合はこの傾向が顕著であり、 将来に渡って複数言語で対応づけされた大量の音声言語資源の入手は現実的ではないため、 コーパス利用の手法は実用的ではない。 一方、言語によっては二言語話者を確保することさえ容易ではないため、 手作業による翻訳知識の構築も比較的困難である。 日英/英日翻訳とは異なるこのような状況下で、 我々はどのような音声翻訳モデルを考えるのが現実的かについて議輪する。
幸い、日本語もしくは中国語に限定すれば、近年単言語コーパスの入手は容易となり、 単言語話者に作業依頼することも比較的容易である。 もし、これを有効活用して原言語および目的言語で単言語処理を十分に行なうことができれば、 二言語に直接関わる知識及び処理を低滅した翻訳機構を構築できるのではないかと考えた。 すなわち、変換処理に基軸を置いた機械翻訳モデルを転換し、 原言語と目的言語の両者の換言処理を翻訳機構の基軸に置いた機械翻訳モデルを提案する。 このモデルでは、従来は変換部で解くべき問題のできるだけ多くを原言語と目的言語の換言処理の問題と捉え直し、 変換部では文宇通りの「言語変換」すなわち原言語表現から(複数の)目的言語表現への写像(候補列挙)のみを行なう。
本モデルはちょうど、我々が翻訳対象言語に不慣れな場合に行なう訳出作業に似ている。 例えば、中国語の知識がほとんどない状況で中日翻訳を試みる場合、 一旦は辞書で(不自然でも構わずに)日本語に置き換えてから、日本語単独で考え、より自然な日本語に言い換える。 また日中翻訳の場合は、当初は日本語入力表現に対して辞書を引くが、日中辞書に項目記載のない場合もあり、 その場合は別の日本語表現に一旦言い換えて辞書を引くという作業を、我々はごく当然のように行なっている。 以上の観察から、二言語知識を豊富に持つのが理想的ではあるが、仮に二言語に関係する翻訳知識がある程度下足していても、 原言語並びに目的言語で換言処理を十分に行なうことができれば、ある程度の機械翻訳は可能であると考えた。
以上の基本方針に基づいて、現在我々は中日翻訳を対象にして音声翻訳システム(SANDGLASS)の構築を進めている。 本稿では、本提案機構の基本設計を述べ、翻訳方式の議論を行なう。
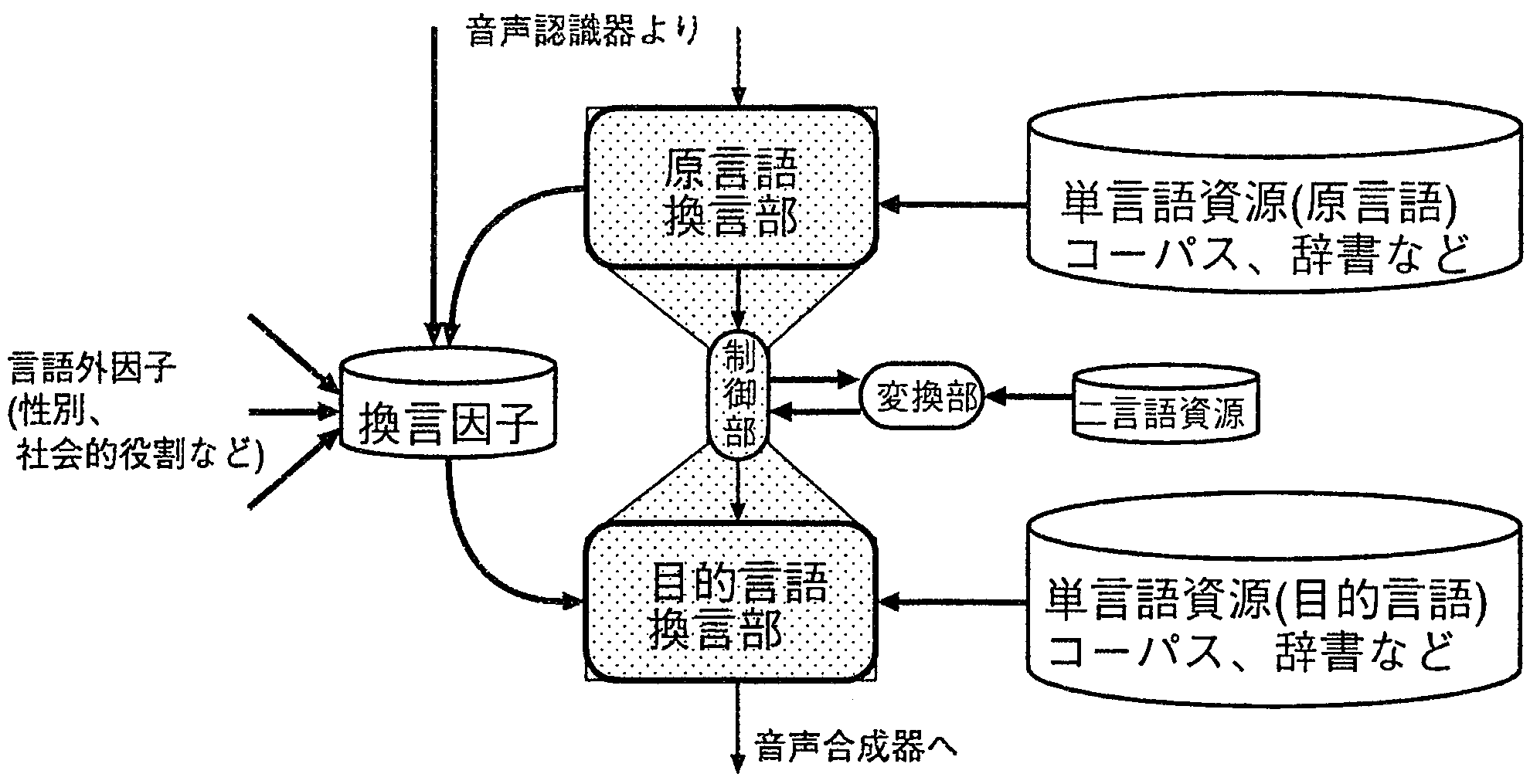
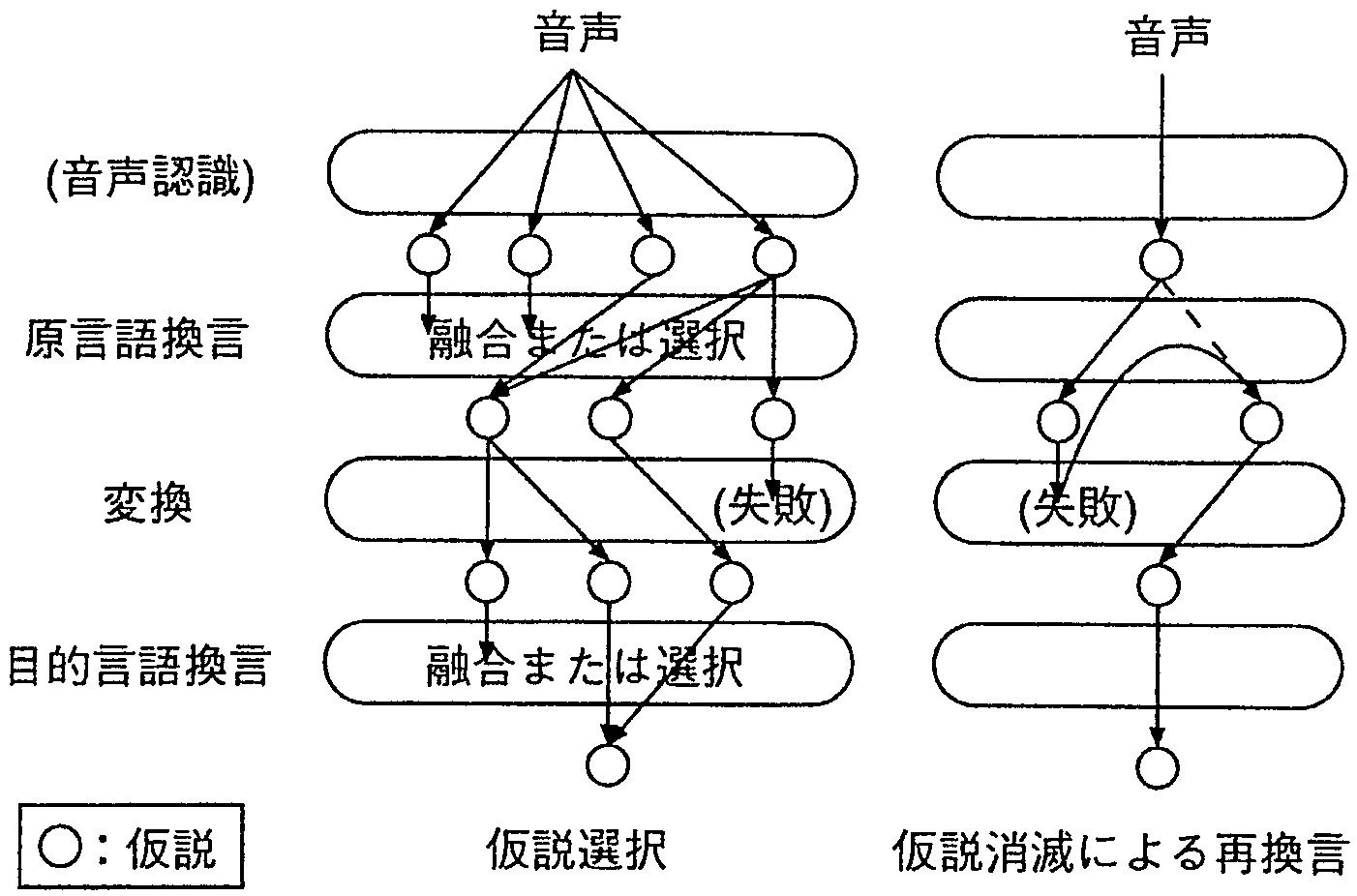
図1にSANDGLASSの翻訳機構を示す。SANDGLASSは音声認職結果を受け取り、まず原言語換言部で換言処理を行なう。 その結果は変換制御部を通して変換部に渡され、目的言語に変換される。 変換が成功した場合すなわち目的言語が得られた場合、制御部は目的言語換言部にその紹果を渡す。 すべての原言語換言結果が変換に失敗した場合、 制御部はどこが失敗したのか1についての情報を原言語換言部に返し、 同時に異なる換言結果を要求する(図2右)。
|
|
また、SANDGLASSでは換言因子[Yam01]を言語表現とは独立に保存する。 換言因子とは換言の際に作用するパラメータのことである。 我々は、厳密な意味で同義となる換言は不可能であるという立場をとる。 これに従えば、換言前後の表現には何らかの差異が生ずることになり、これを我々は換言因子と呼んでいる。 因子となり得るものの多くは言語外情報(発話された状況: 例えばホテルでの旅行会話、話者が女性)や話者の感情、 ある特定の表現に対する強調などの情報で、 これらのうちいずれかの特徴があり、かつこれらの特徴抽出に成功した場合に換言因子として保存される。 換言因子は音声認識部、原言語換言部、システム外のいずれからも得られる可能性がある。
換言因子はいずれも言語に非依存であるため、これらの情報そのものに対して原言語から目的言語に「変換」する必要はない。 すなれち、変換部がこれら情報を入力する必要はないと考え、 本機構では変換部負荷低減の観点からこれらの情報は変換部を経由しない2。
最後に、目的言語換言部において、制御部から渡された複数の仮説に対して、 目的言語の単言語コーパスや辞書、シソーラスなどを利用して最適な単一の目的言語表現を選択する。 同時に、換言因子も入力し、目的言語において各因子を反映させた換言を行ない、その結果を音声合成器に渡す。 換言因子が変換部をパイパスし、原言語換言で得られた因子を目的言語で活用することで、 変換部に一切の負担をかけず、また二言語資源を一切増大させずに、 原言語で持つ細かい表現の差異を目的言語において復元することを可能にする。 原言語で換言因子であっても目的言語では表現の差異が生じず、 換言因子とならない場合がある(性別による表現の差異や敬語など)が、 このような場合は目的言語換言部の判断によってその因子を無視する。
SANDGLASSにおいて原言語で換言処理を行なう目的は以下に示すように3分類できる。
なお、中国語の換言処理については[Zha01]で、 換言による曖味性解消については[Yam01]で議論する。
変換部では、原言語表現に対して目的言語への写像を試みる。 従来の機械翻訳モデルにおける変換処理との重要な差異は、本機構における変換部が以下の2項目の義務を共に負わない点にある。
仮説生成義務 変換部が入力された表現に対して必ず仮説を生成する義務
仮説選択義務 変換部が処理中に生起する複数の仮説に対して取捨選択や尤度付与を行なう義務
すなわち、前者により、変換部は一部の入力表現に対して変換に失敗することを機構として認める (代わりに原言語換言部が変換を成功させる表現に換言する義務を負う)。 また、後者により、変換部は変換結果を一つに絞り込むことを期待されておらず、また変換時に仮説が増えることも認める (代わりに、原言語換言部が原言語の曖昧性を減らす義務を、目的言語換言部が変換結果候捕の中から選択する義務を負う)。 従来変換部に課せられていたこれらの義務は、すべて二言語知識と二言語処理の増大を招くため、 英語が翻訳対象言語でない場合にこれらの負荷を変換部に与えるのは不適当であると主張する。
結局、SANDGLASSにおける変換部は、可能な場合にのみ目的言語候捕を列挙するにとどめる。 一般に、従来の機械翻訳モデルでは変換部に対して変換精度(accuracy)と変換可能表現の網羅性(coverage)が同時に求められていたため、 どのような変換機構であってもこれを両立させるために構造的な困難性を抱えており、 これが従来の典型的な機械翻訳機構の本質的な問題の一つと我々は考える。 一方、本翻訳機構の変換部では、両者の要件のうち重要なのは変換精度のみであり、 網羅性を上げるために変換精度を犠牲にする必要が一切ない(代わりに原言語換言部が網羅性向上を担う)。 もちろん変換部においても網羅性が高いほど望ましいが、網羅性の高さは変換精度の高い場合にのみ意味を持つ。 翻訳機構全体としては、以上の条件を満たす変換部であればどのような機構であってもよく、また換言処理の機構とも独立である。
ところで、表層的な情報で(特に活用語に対して)多くの品詞を推測できる日本語とは異なり、 孤立語である中国語はそのような標識を持たない。 また、内容語と機能語がかなり明確に分離している英語とも異なり、 中国語の機能語、特に介詞(前置詞)の多くは内容語(特に動詞)からの転成であるため多品詞性が顕著であり、 その結果名詞/動詞や介詞(前置詞)/動詞など、複数の品詞を持つ語が英語よりも多い。 このため形熊素解析のみで品詞を決定するのは賢明ではないと考え、 多品詞性を保持したまま構文解析ができるMSLR3を採用した。
変換部では、MSLRを用いて形態素解析と構文解析を同時に行なった後、文字列照合処理によって目的言語に変換する。
例えば、「![]()
![]()
![]()
![]()
![]()
![]() 」という例文に対しては、表1に示す5候捕が出力される。
これは、「
」という例文に対しては、表1に示す5候捕が出力される。
これは、「![]()
![]() 」が「予約/予約する」、「
」が「予約/予約する」、「![]() 」が「場所/処理する」、
「
」が「場所/処理する」、
「![]()
![]()
![]() 」が「
」が「![]()
![]() +
+![]() /
/![]()
![]()
![]() (予約係)」という曖味性を持つためである。
前述したように、変換部においてはこれらの5候補の品詞/構文/意味上の曖味性解消を行なわず、5候捕すべてを目的言語換言部に渡す。
(予約係)」という曖味性を持つためである。
前述したように、変換部においてはこれらの5候補の品詞/構文/意味上の曖味性解消を行なわず、5候捕すべてを目的言語換言部に渡す。
| 構文構造 | 目的言語への変換結果 |
| [ |
/都ホテル/予約/は/処理する/ |
| [ |
/都ホテル/は/処理する/ことを/予約する/ |
| [ |
/都ホテル/は/場所/を/予約する/ |
| [ |
/都ホテル/予約/場所/ |
| [ |
/都ホテル/予約係/ |
対訳辞書には各原言語の語句に対し一般に複数の訳語が付与されている。
このような場合は、複数の訳語を併記したまま、目的言語換言部に情報を渡す。
例えば、「![]()
![]()
![]()
![]()
![]()
![]()
![]() (今日そちらのホテルに泊まります)」の「
(今日そちらのホテルに泊まります)」の「![]() 」は「住む/宿泊する」という複数の訳語を持つ。
同様に「
」は「住む/宿泊する」という複数の訳語を持つ。
同様に「![]()
![]() 」は「ホテル/酒屋」という複数の訳語を持つ。
この結果、変換部において両方の訳を併記したまま、
「/今日/の/ホテル:酒屋/に/住む:宿泊する/+ます/」というような形で目的言語換言部に渡される。
」は「ホテル/酒屋」という複数の訳語を持つ。
この結果、変換部において両方の訳を併記したまま、
「/今日/の/ホテル:酒屋/に/住む:宿泊する/+ます/」というような形で目的言語換言部に渡される。
変換終了後、目的言語において換言処理を行なう目的は (a)仮説の最終的な曖味性解消 (b)換言因子を反映したより「自然な」言語表現への変換の2点である。 例えば、前述の例文であれば、変換部より渡された5候補に対して様々な尤度 (例えば別途用意した単言語コーパスにおける出現確率)により比較を行ない、「都ホテル予約係(です)」が選択され、出力される。
機械翻訳における曖味性解消問題のうち、大きな問題の一つは訳語選択問題である。 これは従来、一般的には変換部で解消されるべき問題と考えられているが、 SANDGLASSでは(1)原言語での語義決定(2)目的言語での訳語決定、の二つの問題と分離して捉える。
例えば、表2に示すように、中国語の「![]()
![]() 」は少なくとも「開く/つける/打開する」の3通りに、
「
」は少なくとも「開く/つける/打開する」の3通りに、
「![]()
![]() 」も少なくとも「割れる/壊れる/砕ける」の3通りに訳すことが可能である。
どちらの場合も、これらのうちどの訳が適切かは従来変換部で決定されていた。
しかし、「
」も少なくとも「割れる/壊れる/砕ける」の3通りに訳すことが可能である。
どちらの場合も、これらのうちどの訳が適切かは従来変換部で決定されていた。
しかし、「![]()
![]() 」は中国語で三つの異なる語義を持ち、「
」は中国語で三つの異なる語義を持ち、「![]()
![]() 」は中国語の同一の語義が日本語で3通りに訳される。
このような場合、SANDGLASSは
」は中国語の同一の語義が日本語で3通りに訳される。
このような場合、SANDGLASSは
という方策を採用する。
| 中国語 | → | 換言結果 | 日本語訳語 |
| → | (本を)開く | ||
| → | (テレビを)つける | ||
| → | (局面を)打開する | ||
| (グラスが)割れる (グラスが)壊れる (グラスが)砕ける | |||
ただし、原言語換言部において語義決定できなかった場合、あるいは語義決定は可能でも適切な換言ができなかった場合は、 原言語において語義決定のための換言処理が行なえないが、このような場合にも目的言語において訳語決定することを試みる。 原言語における語義決定の機構と目的言語における訳語决定の機構は処理内容も使用する言語資源も完全に独立であるため、 この結果SANDGLASSは独立した二つの語義選択機構を持つと考えることもでき、この意味においてより頑健なモデルとなっている。
図2に、SANDGLASSにおける候補選択の概要を示す。 従来の機械翻訳は語義選択、構文的曖昧性、訳語選択などほとんどの曖昧性を変換部において同時に解消する枠組みが多いが、 SANDGLASSでは、変換部において曖味性の解消は行なわない。 すなわち、SANDGLASSにおける曖味性解消は、原言語換言部と目的言語換言部が分担して行なう。
|
中日翻訳など英語以外の言語間で音声翻訳機構を構築するための基本提案を行なった。 我々は、これら言語間の機械翻訳では、可能な限り二言語に直接関わる翻訳知識(二言語知識)を低減し、 原言語及び目的言語の単言語処理に基軸を置くことで機械翻訳機構を構成する本機構が現実的な全体設計であると主張する。 ここでは従来では変換部が負っていた仮説生成義務は原言語換言部が負い、 一方で変換部の仮説選択義務は原言語換言部と目的言語換言部の両者が負う。
音声翻訳システムSANDGLASSは本稿で述べた提案内容に基づいて現在実装を行なっているが、 どこまで二言語知識の縮小が可能かについて現時点で検討が十分ではない。 このため、特にこの点について今後検討を行なっていく。 換言処理については、事例の収集[Shi01]、 現象の分析[Zha01]、モデルの検討をそれぞれ原言語と目的言語に対して同時に進めており、 これらについては別途報告する。