Case Study: Porting an NLP Application to Unicode
Nicolas AUCLERC
Yves LEPAGE
SHIRAI Satoshi
[ In Proceedings of IUC19, pp.395-401 (September, 2001). ]
INDEX
| | | |
Case Study:
Porting an NLP Application to Unicode
|
Nicolas AUCLERC
Yves LEPAGE
SHIRAI Satoshi
| |
| |
|
Good morning,
My name is Nicolas Auclerc and I work as a researcher in ATR, a structure of
four Japanese laboratories, whose main research field is telecommunications.
More specifically, my laboratory is called ATR-SLT, and is concerned with
automatic translation over the telephone, also called automatic interpretation.
Basically, our techniques rely on usage examples, which explains our need
for large amounts of linguistic resources. Logically, we also need tools to
create and update those linguistics resources.
I shall start this presentation by explaining the context with an introduction to
ATR-SLT, and then I shall explain the different steps in building a machine
translation system. Next, I shall present a tool designed to help a tree-banker
under its previous version. We defined new goals for this tool, which
included porting the application to Unicode. This will lead me to speak about
the benefits and the drawbacks of porting this Natural Language Processing
application to Unicode.
| | |
Presentation: ATR
 | |
Advanced Telecommunications Research |
 | |
Founded in March 1986 in the Kansai (Kyoto-Osaka-Kobe) |
|
Capitalized at  22.0325 billion ($180 million) 22.0325 billion ($180 million) |
|
250 researchers (20% are foreigners) |
|
4 projects |
 |
Adaptive Communications Research(ACR) |
 |
Multimedia Integration & Communications (MIC) |
 |
Human Information Processing (ISD) |
 |
Spoken Language Translation (SLT) |
| |
|
ATR Intemational is the structure at the head of ATR's 4 research
laboratories in telecommunications. It was founded in March 1986 in the
Kansai area. The research center has four main projects, and employs 250
researchers. I am participation in the Spoken Language Translation project.
The Spoken Language Translation Research Laboratories started operation in
March 2000 and continues the work of a previous laboratory, called ITL,
which stands for Interpreting Telecommunications Laboratories. SLT is
divided into 4 departments with 60 researchers. I work in the machine
translation department.
This slide shows the standard architecture of a translation system. The goal is
to translate a sentence in a source language into one in a target language.
Direct translation, which mean to translate word by word and then reorder, is
an old technique, which does not deliver very good results. The second
generation of machine translation systems uses another techniqtle which
involves three steps: Parsing, transfer and generation. The first step, parsing,
analyzes each sentence of the source language and returns a linguistic
structure which represents the sentence parsed. The second step, transfer,
converts the linguistic structure of the sentence in the source language into a
linguistic structure in the target language. The third step, generation,
generates a sentence in the target language from the linguistic structure
obtained after the transfer.
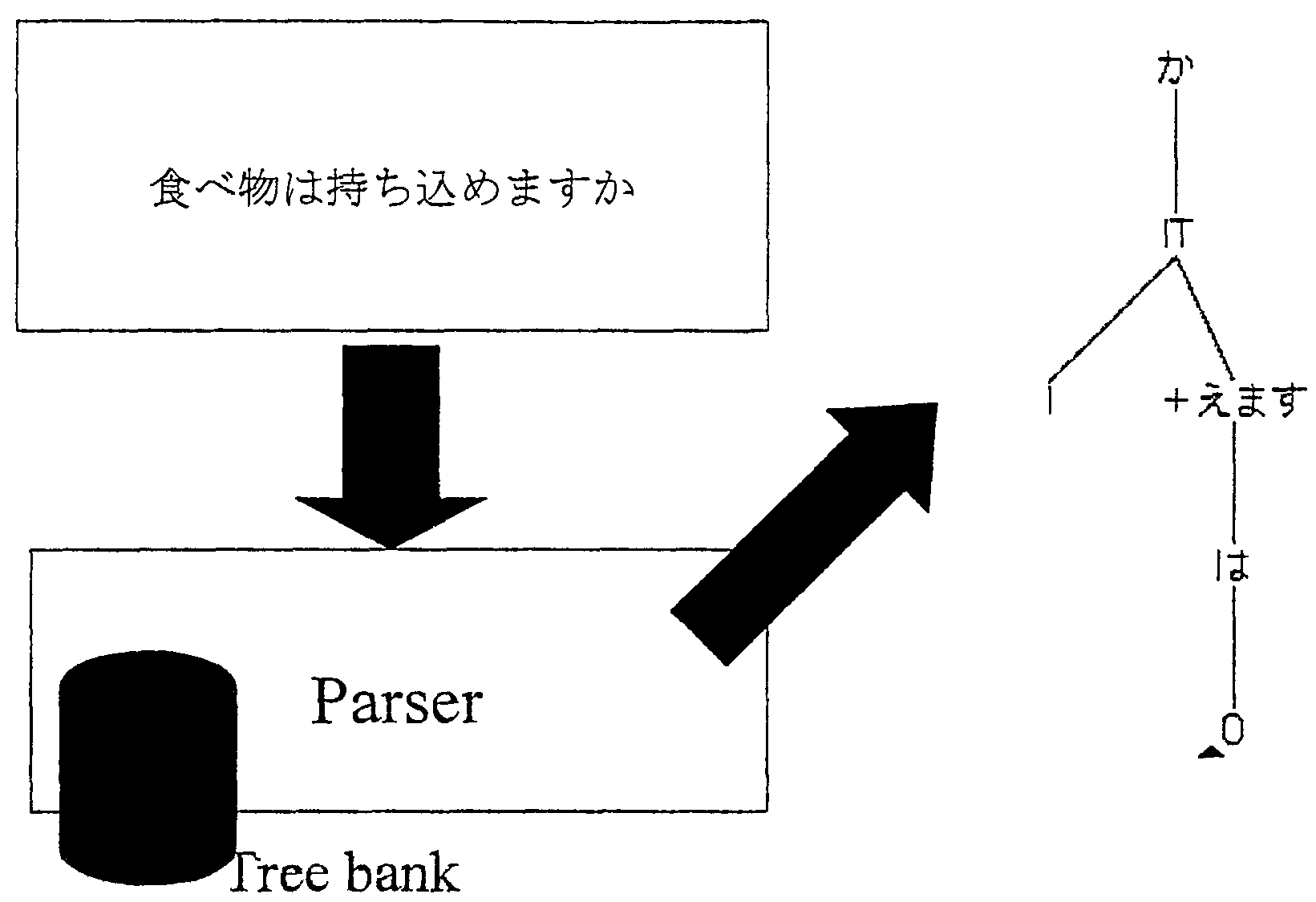
In this presentation, my main concern is parsing. As I already mentioned
about parsing, we start with a sentence, here in Japanese, and we want to
obtain the linguistic structure of this sentence. To deliver such a structure is
the job of a parser. in this slide, we see that the structure obtained is a tree.
The parsers that we build in our lab exploits a large amount of already parsed
data. A collection of such data is called a tree bank.
A treebank is a set of sentences together with their linguistic description.
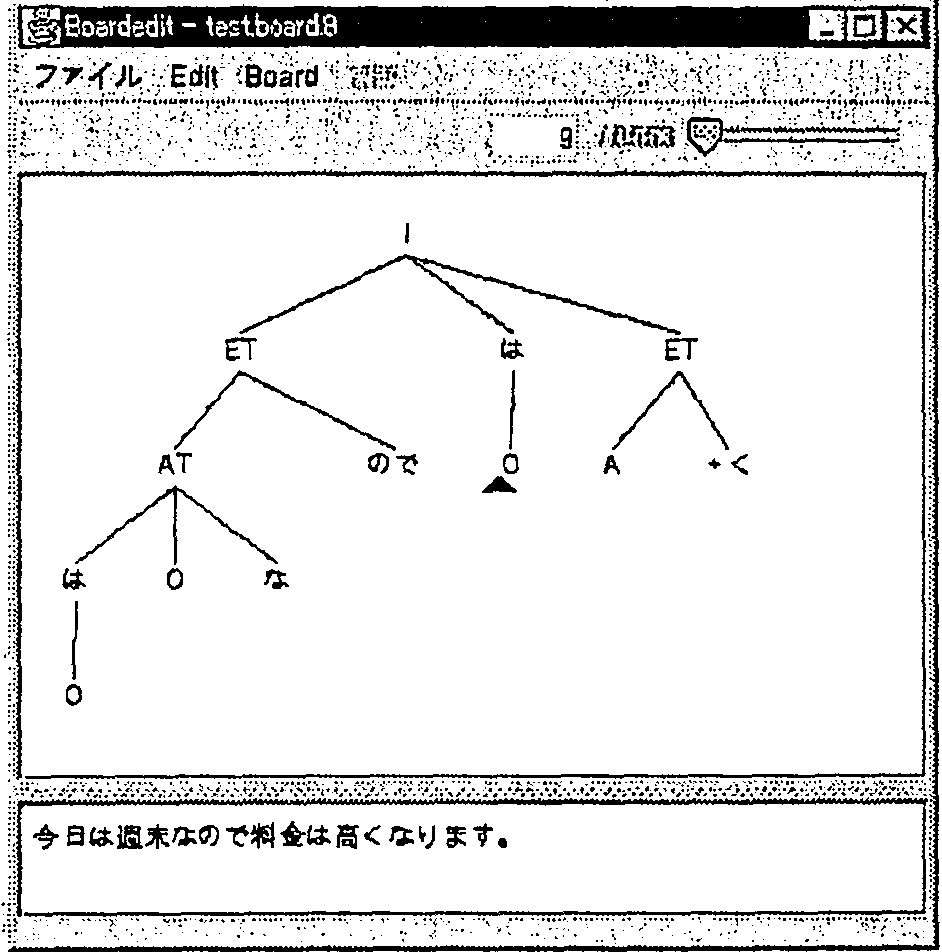
Here you see an excerpt of a treebank in the domain of travel situations.
The sentences presented here are: Can you bring food in?, You can't bring
food in, and Do you have a sleeping bag?
Here we show the general process of building a tree bank. The first step is to
collect a set of sentences. Then, for each sentence, we try to obtain the
linguistic structure by using parsing aids, such as exact match, completion by
analogy or just try to build it by hand.
| | | |
Goals: BoardEdit
a user-friendly tool for tree banking
| |
|
When augmenting a tree-bank, we start with a new sentence, and we want to
get a linguistic structure for this new sentence. As our final goal is to build a
parser, we do not yet have a parser at our disposal. In this case, primitive
tools, called parsing aids, shall help us. As the structures delivered by the
parsing aids may not be the precise ones, there is possibly a need to modify
them. For that reason, a tree editor is integrated with the parsing aids.
In 1995, the previous specifications, shows in this slide, guided the
implementation of a tool called BoardEdit under a 3Mac OS. In 1999, a new
implementation of BoardEdit was done for Solaris. Both implementations
were thus mono-platform applications. Moreover, the parsing aids developed
for these applications only support English and Japanese.
| | | |
New Goals
| |
Share in-house tree banks and parsing aids |
| | - | |
Client/server application |
| | | | > | |
Multi-platform or intranet |
| | - | |
Unicode |
| | | | > | |
Multi-lingual support |
| | | | > | |
Universal parsing aids |
| |
Support for at least 5 languages |
| | - | |
Janese, Chinese, Korean, French and English |
| |
|
In the beginning of 2000, our company, ATR SLT, decided to use Unicode as
the encoding character set for all linguistic databases.
Consequently, we decided to redesign BoardEdit and to include in the new
design a port to Unicode.
Here are the main points of this new design. The previous implementations
were quite heavy stand-alone applications useable only for English and
Japanese, as I mentioned previously. To make everything lighter, we adopted
a client-server model. Also, of course, we foresaw localization in several
languages. To merge the previous different implementations, a multi-
platform implementation was decided upon. Here are the client specification.
| | | |
Server Specifications
| |
Search engine (host for parsing aids) |
| | - | |
Keep current implementation in C for efficiency reasons |
| | - | |
Unicode support |
| | | | > | |
C code: Adapt parsing aids to Unicode |
| | | | > | |
Data: Conversion of in-house tree banks to Unicode |
| |
|
And here are the server specifications. Please notice that, on the server side
the adoption of Unicode implied adapting some existing code.
| | | |
Overview of the New Application
| |
|
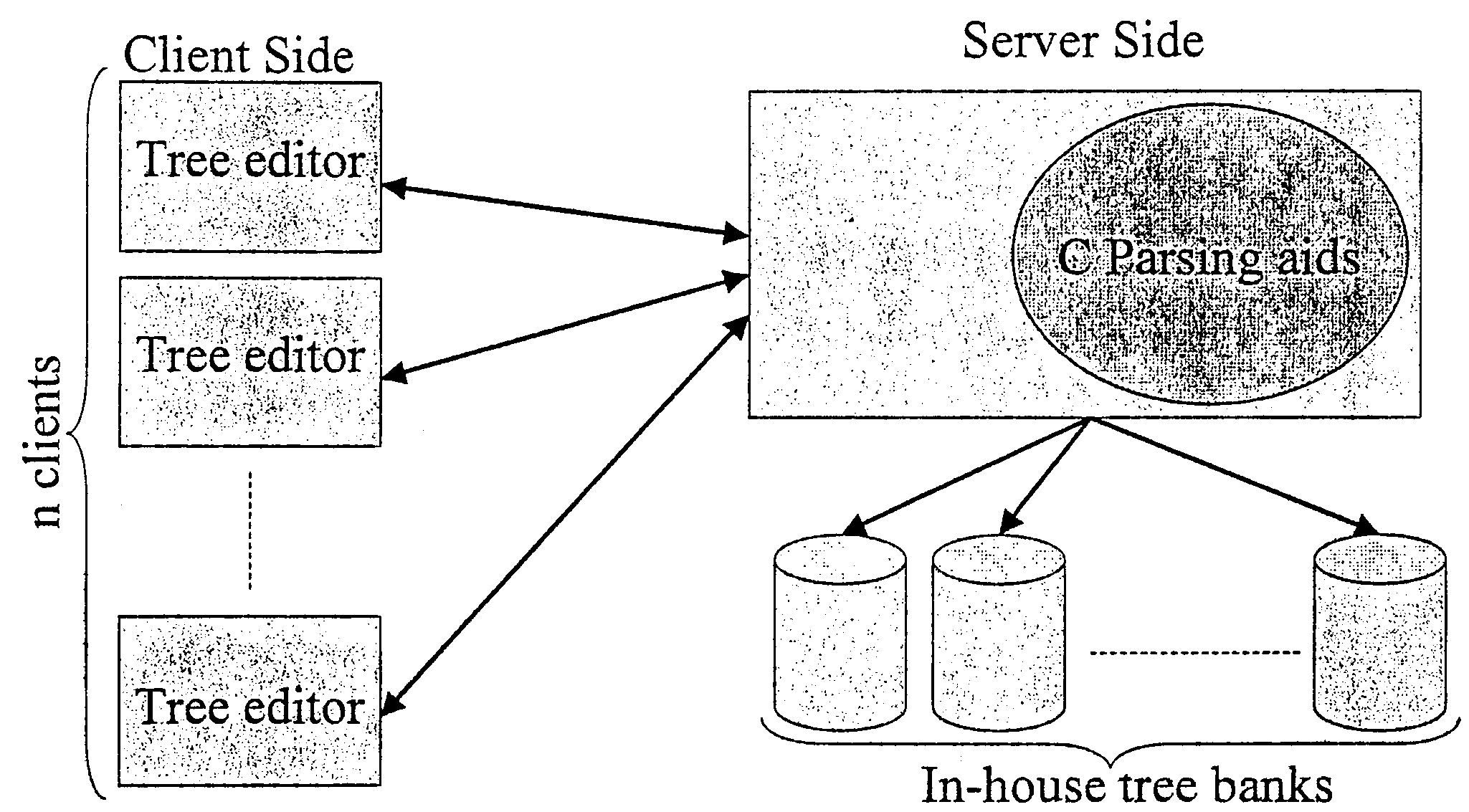
This is an overview of the new BoardEdit. You can see what we discussed
previously: parsing aids, tree editors for the programs, and tree banks for the
data. The new design allowed us to separate things in a clearer way: parsing
aids run now on the server side only, and tree editors are located on the client
side. Tree banks need not be loaded on the user machine: they are used by the
parsing aids on the server. In addition, in this new design, several clients can
run on different workstations possibly running different operating systems,
and they just communicate with the server.
Of course, for practical reasons, the new implementation should not require a
complete rewriting of the existing code. This existing source code was
entirely in C/C++. However we wanted a language which included graphical
components with Unicode features. Hence, a tradeoff had to be found
between reusing existing C code for the parsing aids and Unicode.
The right choice for our new design and the right answer to solve the
previous trade-off seem to have been the use of Java. On the client side Java
simplified the use of Unicode and the implementation of the user interface.
On the server side, as a matter of fact, our parsing aids, which are primitive
tools, do not manipulate the semantics associated with characters, they only
perform basic character operations like testing equality. Hence we could
clearly separate code that was concerned with the meaning of characters from
code that was not concerned with this. The former code was rewritten in Java,
which transparently supports Unicode, and the latter was kept in C, with few
modifications.
Let us now speak about data, meaning tree banks. We simply had to apply
converters to our data. For the server, using only one encoding character set,
Unicode, there was a positive consequence on the programs from the static
point of view: we reduced the size of the binaries. It also had no negative
consequence: we kept the same processing time for all languages, Japanese,
English, etc. Moreover, by using Unicode, we made the binary code
universal: any new language will be handled by the same new program
without any need to add anything whatsoever. Lastly, a benefit for the client
side was that, thanks to the Java input Method Framework, we did not need
to be concerned with character input.
(Running the demonstration to be shown during the conference) Given a new
sentence, we first look for the same one in the tree bank by exact matching.
Here exact matching is universal because the character set is Unicode. If the
sentence is found, the user just copies and pastes the output. In case it is not
found, we apply a much more complicated technique called completion by
analogy, which relies entirely on character comparison for equality. It is thus
insensitive to the character set. Hence using Unicode or whatever is
transparent. If this technique fails, approximate matching, a generalization of
exact matching, is used.
| | | |
Goals: Completions Status
 | |
Share in-house tree banks and parsing aids |
| | v | |
Client/server application |
| | | | v | |
Multi-platform (tested under Windows and Linux) |
| | | | | |
Intranet (just a matter of time) |
| | v | |
Unicode |
| | | | v | |
Multi-lingual support |
| | | |
v | | Universal parsing aids |
| v | |
Support for at least 5 languages (localized for 4) |
| | v | |
Japanese, Chinese, Korean, French and English |
| |
|
In conclusion, we have reached almost all of our goals, which we list here.
By using Java for the client, we made the port to Unicode simpler. However,
let me mention that, one day, possibly, in future extensions of the tool, we
may need more information, like the direction of the text (left to right, right
to left, or top to bottom). Also, to address a different but related problem,
under the Java input method framework, there is no reliable or efficient input
methed tools for the input of Asian languages like Japanese and Chinese.
| | | |
Conclusion
| BoardEdit has been successfully ported to support Unicode |
| | > Greater universality |
| > Code made simpler |
| > Laid foundations for extensions |
| |
|
In conclusion, we may claim that, for our purposes, the use of Unicode
facilitated our work on the data side as well as on the programming side,
Moreover, the use of Unicode had no influence on the processing speed,
which can be a real problem with large linguIstic resources.
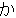 ( IT (I , +
( IT (I , +  (
( 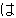 ( O ) ) ) )
( O ) ) ) )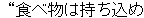
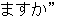
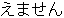 (
( 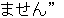
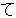 ) ,
) ,  ) )
) )