| 名詞A or B or Cの意味属性 |
|
本塙では、構造に多義を持つ日本語名詞句の中でも、 基本的でかつ高頻度で現れる「AのBのC」を対象に、 名詞の意味属性を用いた係り受け規則の自動生成法を提案する。 この手法は名詞句の持つ意味的な構造に着目して、 1つの名詞句学習データから、 3つの名詞A、B、C間の意味的係り受け規則(3タイプ、計7種類)を自動生成する。 次に、得られた係り受け規則を別の名詞句標本データ(10,021個)に 汎用規則(1, 2, 3次元規則の順)から適用した結果、 判定率96.0%、適合率88.4%の精度で係り先が判定でき、 最終的な正解率は85.1%であった。 これより、提案した方法は名詞句の特徴をよく捉えた、 精度の高い係り受け規則が得られることが分かった。
名詞句解析 係り受け規則 機械学習 汎化
This paper proposed a method automatically to generate dependency rules for "A no B no C", the most typical noun phrases and frequently appeared in Japanese (similar to "C of B of A" in English), using a semantic attribute system currently developed. In this method, 3 kinds of semantic dependency rules such as one-, two-, tree-dimensional rules are independently generated from a noun phrase data-base. In the experiments, the generated rules. were applied to the dependency analysis (in the order of 1-, 2- and 3-dimensional rules) resulting in the recall rate of 96.0%, precision rate of 88.4%, accuracy rate of 85.1%. From these result, it was found that the method yields accurate rules for dependency analysis.
Noun Analysis, Dependency Rule, Machine Learning, Generalization
自然言語処理の最大の問題は、表現の構造と意味に関する解釈の曖昧性である。 いままで、多くの研究が行われてきたが、確率的、 文法的情報に頼った従来の方法では、これらの問題を解決するのは困難であった。
日本語名詞句の解析では、従来、コーパスの基づく方法として、 単語の共起情報を用いて係り先を決定する方法[1]、 意味的クラスの共起情報を用いて係り先が決定される確率を求める方法[2]、 また、名詞句解析では、大量の対訳用例の中から意味的に類似した表現を発見し、 翻訳結果を得る方法[3]などが提案されてきた。 しかし、通常、コーパスから得られる標本はスパースであり、 適切な用例がない場合には、結果は保証されない。 また必要十分な標本データを収集すること、 計算量が膨大となることなどが問題であった。
これに対し、最近大量の標本データから汎化を用いた学習を行い ルールを生成する手法が盛んに行われており、 Alves[4]らは「A のB のC」の係り受け解析に適用している。 しかし、この手法は3つの名詞の組の構造だけで名詞句を捉えようとしており、 名詞句それぞれの特徴に適したルールが作成されにくいといった問題がある。 この問題を解決するため、本稿では、「A のB のC」を対象に、 名詞句の持つ構造に着目して、 3つの名詞A、B、C間の意味的係り受け規則(3つの名詞の組の規則、 2つの名詞の組の規則、1つのみの名詞の規則)を 名詞句標本データから自動生成する手法を提案する。 そして、得られた係り受け規則を別の名詞句標本に適用して解析精度を評価する。
以下では、日本語名詞句の中でも、基本的でか つ高頻度で現れる、2つの助詞「の」と3つの名 詞A、B、C から構成された「A のB のC」の形の名 詞句を考える。ただし、記号A、B、C は名詞の出 現順序をも表す。この名詞句は、係り受け関係に 曖昧さのある名詞句の中で最も基本的なもので ある。以下、この型の名詞句を単に「の型名詞句」 という。
日本語では、一般に、表現要素間に後方修飾の 原則があることに注意すると、「の型名詞句」で は、名詞B の係り先は名詞C に特定されるため、 先頭の名詞A について、以下の2通りの係り受け 解釈が存在することになる。
| 1) | A→B (&B→C) の場合 | ||
| 例) | 「私の母の名前」、 「浴室の脱衣場の壁」 | ||
| 2) | A→C (&B→C) の場合 | ||
| 例) | 「私の昔の友達」、 「東京の数学の教師」 | ||
以下では、簡単のため、1)を 「b係り」、2)を 「c係り」 と呼ぶ。
「A のB のC」を 「A のB」 と 「B のC」 に分けて 考える方法は意味論的にも問題がある。要素合成 法の考え方に従えば、表現の意味はそれを構成す る部品の意味に還元されるが、言語表現では、こ の原理が成り立たない場合が多く、表現の構造と 意味の関係を考えなければならない場合が多い。 例えば、下記の名詞句では、2つの名詞句に分離 することは適切でなく、3つの名詞の組とその出 現順序に依存して意味が決定される。
| 例) | 「盗人のなれの果て」 「私の気のせい」 |
このような場合は、表現を分解せず、ひとまと まりのものとして扱うことが必要である。従って、 「の型名詞句」の名詞間の係り受け関係を決定す る場合も、表現を構成要素に分解してよい場合と 分解できない場合に分けて考えることが重要で ある。
「の」型名詞句の係り受け解析では、3つの名 詞の意味属性の組が決まれば係り受け関係が一 意に決定できると仮定する注と、すべての係り受 け規則は3つの名詞の意味属性の組で表現され る。 ここで「の」型名詞の係り受けの特徴を見て みると、必ずしも3つ名詞の意味属性のすべてが 決まらなくても、係り受け関係が決まる場合があ る。例えば、「私(A)の本当(B)の父(C)」 では、 「私」 は 「本当」 に係ることができないのでc - 係りである。 つまりこの名詞句は「本当(B)」 の みによって係り先を決定できる。そこで(A,B, C)の3つの名詞の同時共起で「の」型名詞句の 係り受け関係を捉えるだけでなく、(A,B), (B,C), (C,A)のそれぞれ2つの名詞の 関係、およびそれら3つの関係、さらに(A)、 (B)、(C)それぞれ1つの意味属性で係り受 け関係を捉えるほうが、対象とする名詞句の構造 の特徴をより良く捉えられると考えられる。 また、 3つの意味属性の組でルールを作成するだけで なく、2つの意味属性の組のルール、および1つ の意味属性のルールを作ることにより、1)複数の 3つの意味属性の組のルールを2つ、または1つ の組の意味属性のルールに置き換えることによ って、ルール数を圧縮することができ、2)制約の 緩いルールにすることによって、未知の用例に対 し、より多くの係り受けの判定ができると考えら れる。次節以降で1、2、3次元それぞれの係り 受け規則の生成法および適用順序について述べ る。
(1) 係り受け規則の形式
前節の仮定に従い、名詞句「A のB のC」の意味 構造を(X,Y,Z)で表す。 ただし、X, Y, Z は、それ ぞれ、名詞A, B, C の意味属性番号[5]とする。 次 に図1に示すように、この意味構造の名詞句に対 する係り受け規則を(X,Y,Z:D)で表す。ただし、D は係り受けのダイプで、D=b は前方係り受け (b-dependency)、D=c は後方係り受け(c-dependency)を表す。
| ||||||
(2) 係り受け規則のタイプ
係り受け規則を以下の4タイプ(例外規則を含 む)に分ける。
1)単一の名詞に着目した規則(1次元規則)
この規則は、構成要素の名詞の一つの意味属性
とその名詞が何番目の名詞として使用されたか
が分かれば、残りの2つの名詞の意味属性とは無
関係に、係り受け関係が決定できる規則である。
対象とする名詞句では3つの名詞が使用されて
いるため、その位置に対応して、係り受け規則は、
次の3種類に分けられる。
(X,*,*:D), (*,Y,*:D), (*,*,Z:D)
* : 任意の意味属性
2) 2つの名詞に着目した規則(2次元規則)
この規則は、2つの名詞の意味属性とそれらの
出現位置が与えられれば、残りの名詞の意味属性
とは無関係に係り受け構造が決定できる規則で
ある。意味属性が無関係となる名詞の位置に応じ
て、解析規則は次の3種類に分類される。
(X,Y,*:D), (*,Y,Z:D), (X,*,Z:D)
3) 3つの名詞に着目した規則(3次元規則)
この規則は、3つの名詞すべての意味属性とそ
の出現位置の関係で係り受け構造が決定できる
規則で次の1種類である。
(X,Y,Z:D)
4) それ以外の規則(例外規則)
単語の意味属性と出現位置では係り受け構造 が決定できないもの。 単語の字面を用いて規則を 記述する必要があるため、ここでは例外ルールと 考える。
(1) 1次元規則の抽出と汎化
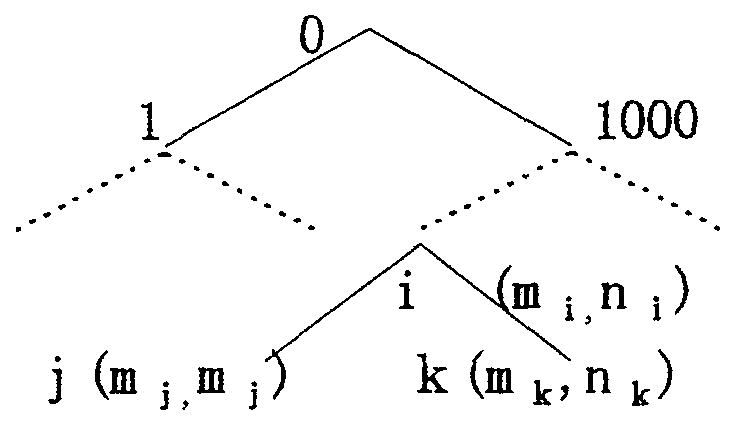
図4に示すように、名詞A, B, C のそれぞれにつ いて単語意味属性体系の木を用意し、各木の各ノ ードにリスト(mi、ni)を対応させる。 ただし、 mi は、i 番目の意味属性を持つ名詞が使用され た名詞句のうち、b-dependency の数、ni は、 c-dependency の数を表すもので、 いずれも、3.2節で作成した標本データを集計することによ り得られる値である。
|
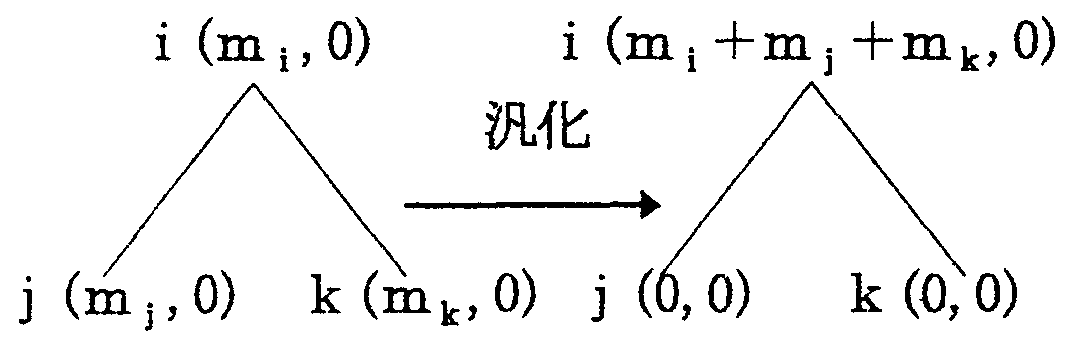
ここで、1次元規則は、3つの名詞のうちのど れか一つの名詞の意味属性のみに依存して係り 受け関係が決定できる規則である。十分大量の標 本データからmi, ni の値が求められているとす れば、mi またはni のどちらか一方が0となると ころでそのノードからルートのノードにたどっ たとき係り先の違う用例がない場合に1次元規 則が存在する。逆に、両者の値がいずれもゼロで ないときは、その意味属性i を用いた1次元規則 は存在しない。
すなわち、名詞A の意味属性体系で、mi ≠0 か つni =0 なる意味属性i からは、係り受け規則 (i,0,0:b)が得られ(図5参照)、mj =0 かつnj ≠0 なる意味属性j からは、係り受け規則 (j,0,0:c)が得られる。 mk ≠ 0 かつnk ≠ 0 なる 意味属性k では、1次元規則は存在しないから、 次項に述べる方法で、2次元規則、3次元規則の 有無を調べる。 なお、m1 =0 かつn1 =0 なるノ ード1では、改めて規則を作成する必要はない。
|
(2) 2次元規則および3次元規則の抽出と汎化
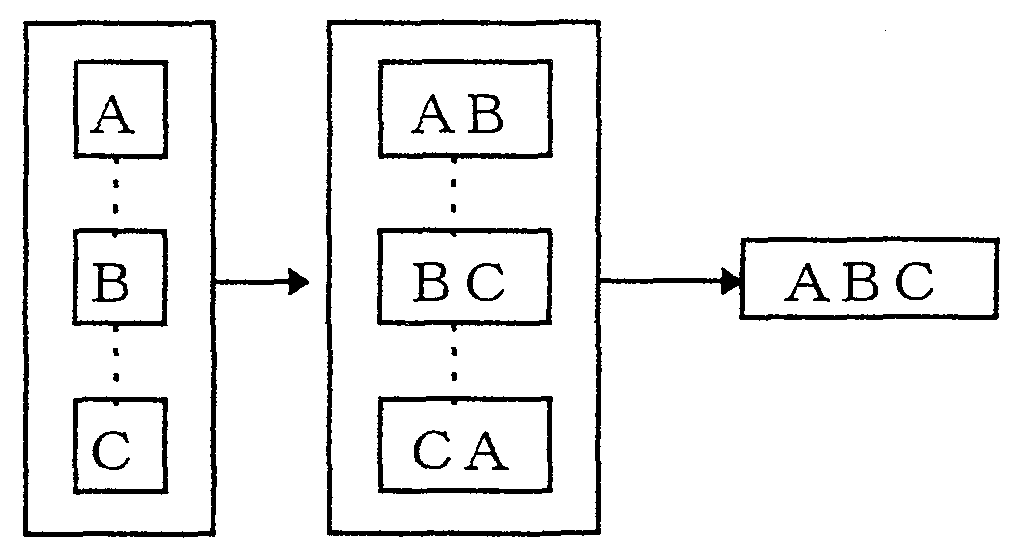
1次元規則が1次元配列から求められたのに 対して、2次元規則は、2次元配列から求められ る。(i,j)の位置の配列要素(mij, nij)から係り 受け規則を抽出する方法、および規則を汎化する 方法も前と同様である。3次元規則もまた同様で ある。
係り受け規則の生成法は以下の2つの方法が が考えられる。
| 1) | 初めに、1次元規則を生成し、生成された規則 に当てはまるデータを標本データから削除す る。次に残された標本データに対し2次元規則 を生成し、同様に生成された規則に当てはまる データを削除する。 そして最終的に残されたデ ータに対して3次元規則を生成する方法。この 場合、規則の適用は1次元規則から先に適用す る必要がある。 |
| 2) | 標本データから1、2、3次元ノレールを独立に 生成し、その後、次元間で重複するルールを削除 する方法。 |
この2つの方法には以下の特徴がある。
1. の方法は、生成された規則に当てはまる用例 を順次削除していくため、2. の方法に比べて、後 に生成される規則の数は減少する。また、後にな るに従って生成規則のための用例数が減少する ことにより、2. の場合より汎用的な規則が生成さ れるが、学習用の標本があらがじめ十分用意され ていない場合は、必要な規則が生成されなくなる 危険がある。
2. の方法では、各次元の規則はお互いに独立に 生成されるため、その総数は、1. に比べて多くな る。 また、2次元規則、3次元規則が汎化できる 程度も低い。しかし、学習データが必ずしも十分 でなくても、必要な規則の多くが生成できる可能 性がある。
本論文では、規則生成に必要な標本データをも れなく用意することは現実には不可能であるこ とを考慮し、有限の標本から必要な規則をなるべ くもれなく抽出するために、2. の方法を採用する。
学習データから3タイプ、計7種類の係り受け 規則を生成する場合、包含関係のある規則が生成 される可能性がある。 この場合、包含する側の係 り受け規則だけを残し、包含される側の係り受け 規則を除去することにより、ルール数の削減を図 ることができる。 そのための規則として以下の2 つの規則をつくった。
| 1) | 次元の異なるルールが生成された場合、よ り低い次元のルールを残し、その他のルー ルを除去する。 |
| 2) | 同次元のルールが生成された場合はどち らも残す。 |
本手法では3.4節の2. の規則生成法に従っ て、1つの学習データから3タイプ、計7種類の 規則を生成する。 この方法では、生成された規則 はいずれも独立であるため、適用順序は任意であ るが、ここでは以下の順に適用することとする。
| 1) | まず、汎用的な規則の順に1次元規則、2次 元規則、3次元規則の順に適用する |
| 2) | 同次元内の複数の規則が適用され異なった 係り先が得られた場合、その次元では係り 先を決定せず次の次元に送る |
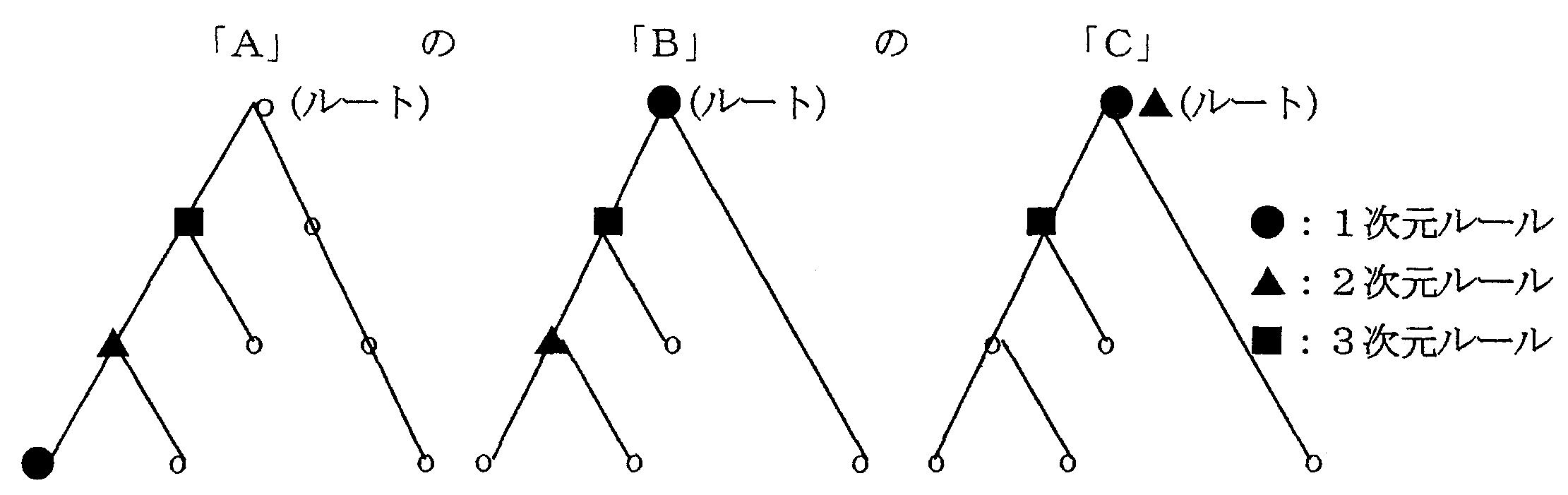
1) の規則について
通常の規則の適用では、例外規則から先に 適用していく必要があるが、図2に示すよう に1、2、3次元規則の間には包含関係があ り、3次元規則は1、2次元規則を包含し、 2次元規則は1次元規則を包含している(1、 2、3次元全ての規則が生成されるわけでは ない)。 そこで、規則の適用順序はより広範 な名詞句の特徴を代表していると思われる規 則(1、2、3次元の順)から適用する。(図 3参照)
|
|
2) の規則について
1、2次元規則にはその中に3つの規則が あるため、同一の名詞句に対して、2つ以上 の規則が適用されたときは、係り先の違う結 果が得られる可能性がある。 この場合はその 次元で特徴を捉えられないという理由で係り 先を決定せず、次の次元に送る。
図6に実験の手順を示す。実験に使用する名詞 句は新潮文庫100冊(900万単語)より抽出した 10,021個のデータに、人手で意味属性および係 り先を付与したデータを使用した。 実験は、10 分割Cross Validation の方法とし、10,021の名 詞句データの9割を学習用データ、残りの1割を テストデータとして、10回繰り返した。
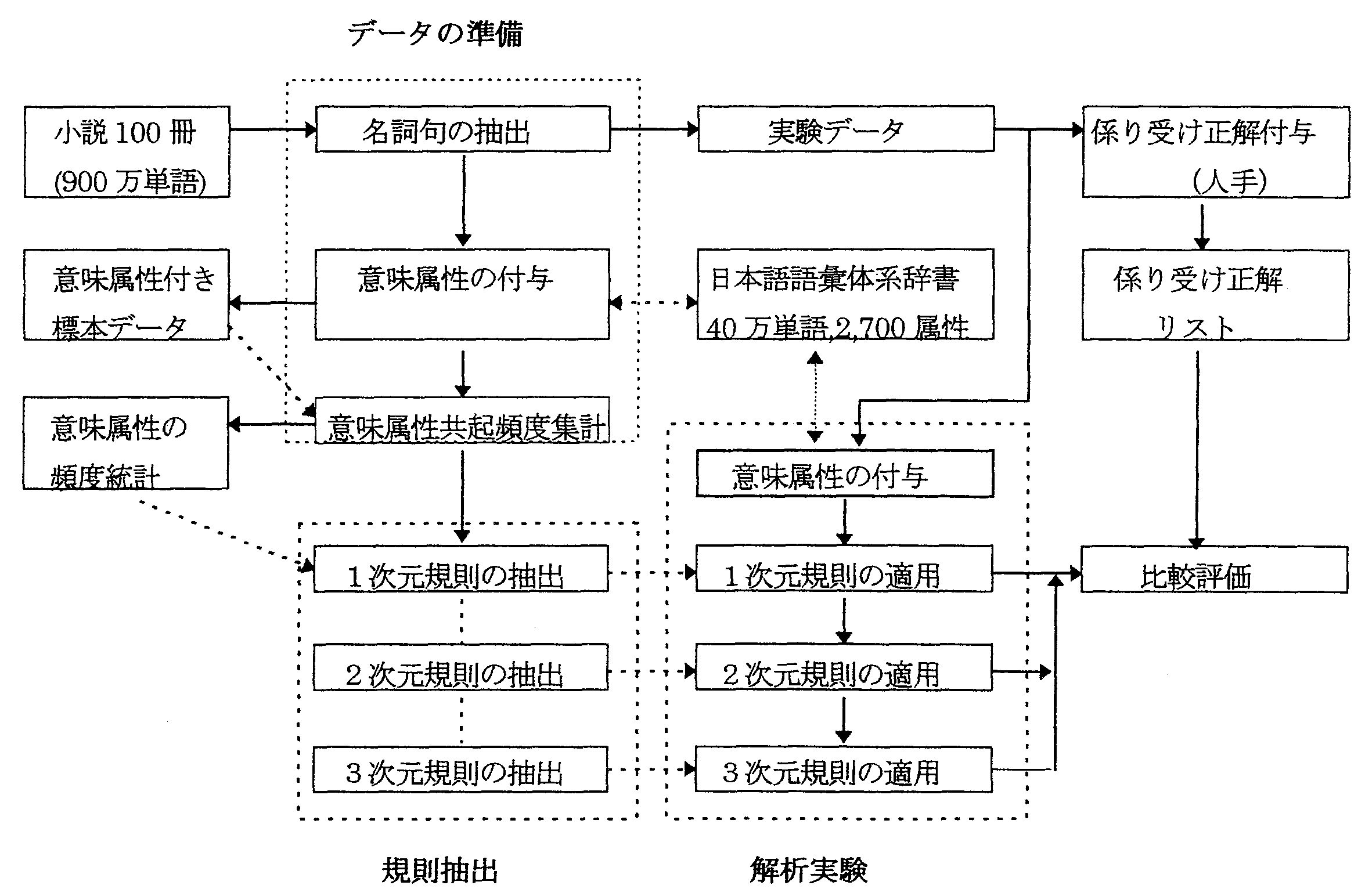
|
表1に標本データの各名詞ごとの意味属性の 深さついての度数分布を示す。
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| *1 : 意味属性体系の意味属性数 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| *2 : 使用された意味属性数 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| *3 : 適用回数 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
この表より以下のことが分かる。
表2に生成された規則の個々の規則数とその 係り受け規則を実験データに適用したときのカ バー率及び適合率を示す。 この表より以下のこと が分かる。
| タイプ | 1次元ルール | タイプ | 2次元ルール | タイプ | 3次元ルール | ||||||
| ルール数 | カバー率 | 適合率 | ルール数 | カバー率 | 適合率 | ルール数 | カバー率 | 適合率 | |||
| Aのみ | 78.5 | 9.0 | 91.5 | AB のみ | 974.6 | 59.3 | 90.2 | - | - | - | - |
| Bのみ | 84.3 | 8.8 | 89.2 | BC のみ | 937.0 | 69.8 | 91.7 | - | - | - | - |
| C のみ | 60.3 | 6.2 | 87.6 | CAのみ | 947.2 | 67.0 | 91.3 | - | - | - | - |
| 1次元規則 | 223.1 | 19.3 | 91.7 | 2次元規則 | 2,859 | 85.8 | 90.9 | 3次元規則 | 2,455 | 91.0 | 86.7 |
| (A,B,C) | (AB,BC,CA) | ||||||||||
1) 1次元規則について
約223の係り受け規則が得られ、全体の19% をカバーしている。
2) 2次元規則について
ルールの種類ごと(ABのみ、BCのみ、CA のみ)のカバー率は60から80%である。 しかし、 3つ合わせた規則(係り先が競合した場合には判 定しない)を適用したところ、全体の86%の名 詞句に対して係り先を判定することができ、その 適合率は91%であった。
また、3つの規則合わせて、約2,860個の係り 受け規則が得られた。
3) 3次元規則について
係り受け規則数は約2450と多いが、カバー率 および適合率は1、2次元規則と同程度である。
生成された3タイプ、計7種類の規則 を 10,021件の実験データに適用し、カバー率、適 合率、および正解率を出した。 このときの7種類 の規則の適用順序は3.6節で述べた通りである。 結果は、表3に示すように、最終的に全体の 96.0%の実験データに対して係り先が決定され、 その適合率は88.4%であった。 規則が適用され なかった名詞句はわずか4.0%であった。 カバー 率と適合率をルールが適用される段階ごとに見 てみると、カバー率は個々に適用したときと比較 して2、3次元の順に悪くなっているのが分かる。 適合率も同様に比較した場合、カバー率と同様に 2、3次元の順に悪くなっているが特に3次元で の落ち込みが大きい。 これは1、2次元ルールの 適用が終わった段階において、判定しにくい名詞 句データが3次元の規則適用に送られてくるか らである。 このことより、3次元規則の適用に送 られてきた名詞に対しては別方式で係り受け解 析を行うといった、ハイブリッド型解析を行うこ とも考えられる。
| ||||||||||||||||||||||||||||||||||||||||||
| カバー率=計算機が係り先を決定した個数/全実験データの個数 | ||||||||||||||||||||||||||||||||||||||||||
| 適合率=係り先の正解の個数/計算機が係り先を決定した個数 | ||||||||||||||||||||||||||||||||||||||||||
| 正解率=カバー率×適合率 | ||||||||||||||||||||||||||||||||||||||||||
表4に2次元規則、3次元規則のみを使った解 析と本手法との解析精度の比較を示す。 この表の 全ルールとは学習データから得られた係り受け 規則すべてを指す。 この中には1つのみの学習デ ータから得られた係り受け規則も含む。 一方、度 数2以上のルールとは2つ以上の学習データか ら得られた係り受け規則を指す。信頼性の面から 1つのみの学習データから得られた係り受け規 則は使用しない方が妥当と思われる。 しかし、3 次元ルールでは全てのルールを使用した方が正 解率が良くなるという結果が得られた(カバー率 の差がそのまま正解率に反映されている)。以上 のことをぶまえて本実験では、2次元ルールは度 数2以上のルールを適用し、3次元ルールは全て のルールを適用し解析を行った。 結果は、1、2、 3次元のルールを汎用的なルールから適用する とした本手法が単一次元のみの場合と比べて、カ バー率で6〜11%上回った。 それにより、最終的 な正解率も6〜7%向上した。 このことより1つの 学習データより、3タイプ、計7種類の規則を生 成し、汎用的な規則(1次元規則、2次元規則、 3次元規則の順)から順に適用することの有効性 が示された。
| 2次元ルール | 3次元ルール | 本手法 | |||
| 全ルール | 度数2以上のルール | 全ルール | 度数2以上のルール | ||
| カバー率 | 65.8% | 85.8% | 91.0% | 79.1% | 96.0% |
| 適合率 | 90.2% | 90.9% | 86.7% | 91.3% | 88.4% |
| 正解率 | 59.3% | 78.0% | 78.9% | 72.2% | 85.1% |
表5に、ルールを削減した場合と削減していな い場合とのルール数および正解率の比較を示す。 この表より、ルールを削減したものはしなかっ たものに比べてルール数を35.1%削減すること ができた。 またルール数削減に伴うカバー率の低 下を1.8%に抑えることができた。
| カバー率 | 適合率 | 正解率 | ルール数 | |
| 規則削減前の係り受け規則を適用 | 96.0% | 88.4% | 85.1% | 5,313.4 |
| 規則削減後の係り受け規則を適用 | 94.2% | 87.8% | 82.7% | 3,448.4 |
本稿では、係り受け解析に曖昧性のあるもっと も典型的な名詞句である 「AのB のC」 を取り あげ、名詞の意味属性を使用した意味的係り受け 規則の自動生成法を提案した。 この方法により、 大量の解析済みの名詞句標本から名詞間の意味 的構造と係り受け解釈の関係を自動的に学習し、 汎用性の高い規則から順に3タイプ、計7種類の 規則を生成した。
本方式を日本語名詞句10,021件に適用した実 験では、1次元規則223件、2次元規則2859件、 3次元規則2455件が得られた。 また、これらの 規則を別の名詞句標本10,021件の解析に適用し た結果によれば、カバー率96.0%、適合率88.4%、 正解率85.1%で名詞句の係り受けを解析できた。 これより、提案した方法は精度の高い係り受け規 則が得られることが分かった。
また本方式は別の名詞句の係り受け解析“Aの B とC”、“形容詞+AのB” などにも適用可能 であると思われる。