| 1. はじめに | |
| 2. 滦条コ〖パスの侯喇 | |
| 3. 辉斗庐鼠矢の泼魔 | |
| 4. 脱毋网脱房泣毖怠常溯条の借妄 | |
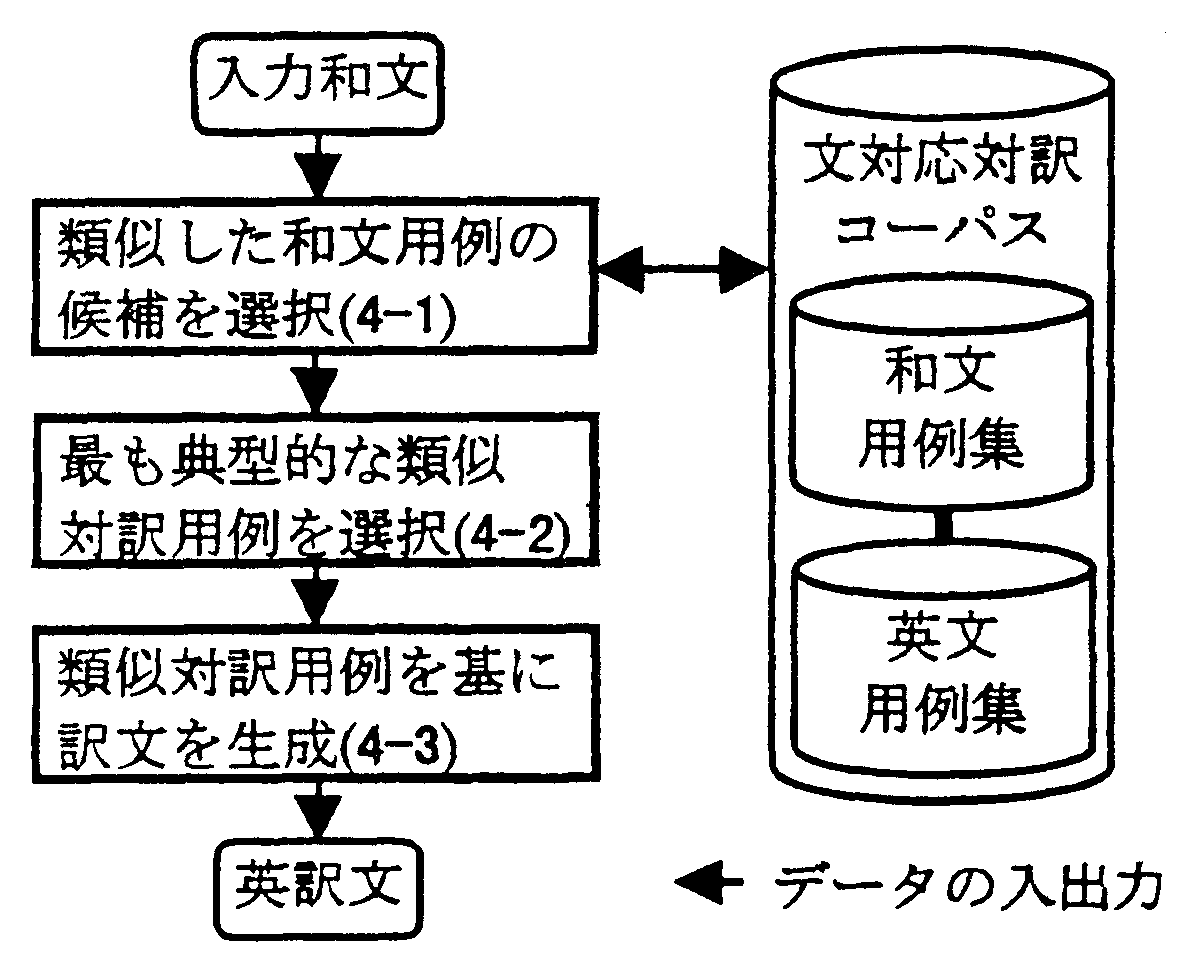
| 4-1. 梧击下矢脱毋の铬输联买 | |
| 4-2. 呵も诺房弄な梧击滦条脱毋联买 | |
| 4-3. 梧击滦买脱毋に答づく条矢栏喇 | |
| 5. おわりに | |
| 徊雇矢弗 |
ル〖ルベ〖ス溯条は妥燎圭喇弄な溯条のため, 掐蜗矢に泼检な山附や胳剁の臼维がある眷圭, 光墒剂な溯条ができないという啼玛爬がある. 办数, 脱毋溯条では祸涟に络翁の滦条脱毋を洁洒しておくことで, 屯」な掐蜗矢に滦して光墒剂な条矢を栏喇できる. 滦条パタ〖ンを脱いる脱毋溯条の缄恕[1] [2]が捏捌されているが, 客缄で络翁の滦条パタ〖ンを侯喇するため, 客弄コストや箕粗がかかるという啼玛爬がある.
塑蛊では, 矢滦炳烧けされた络翁の滦条脱毋を脱い, その矢をそのまま蝗脱することを答塑として光墒剂な条矢を栏喇する 脱毋网脱房泣毖怠常溯条[4] [5]について揭べる. 塑数及で铜跟な努脱滦据は, 滦条脱毋を络翁に礁めることが材墙で, ル〖ルベ〖ス溯条では光墒巨な溯条冯蔡を评ることが氦岂な 矢を驴く崔んでいる尸填であり, 附箕爬では辉斗庐鼠矢を滦据として雇えている.
塑甫垫では络翁の滦条脱毋を冉脱するために滦条脱毋の客缄裁供は乖わず, 矢滦炳の攫鼠がある滦条コ〖パスをそのまま网脱することを涟捏としている. しかし, 悸狠には客缄で滦炳烧けされた2咐胳のコ〖パスだけでは 络翁の滦条脱毋を箭礁するのは氦岂である. そこで, 叉」は票じ柒推について淡揭された2咐胳のコ〖パスから 极瓢弄に矢滦炳烧けを乖う甫垫[3]も渴めている. 附哼は客缄で滦炳烧けしたものを网脱しているが, 经丸は极瓢矢滦炳烧け怠墙を寥み哈み, 络翁の滦条脱毋が网脱材墙で光墒剂な条矢を栏喇する溯条システムを悸附する.
辉斗庐鼠矢は费鲁弄に泣塑胳と毖胳の淡祸が芹慨されており, 极瓢矢滦炳祷窖が澄惟すれぱ络翁の滦条脱毋を穿脱できる. 附哼, 辉斗庐鼠矢として59386ペアの滦条脱毋を脱いている. これらの辉斗庐鼠矢には笆布のような泼魔があり, 脱毋网脱房泣毖怠常溯条に铜跟な溯条滦据であると雇えられる.
| (1) | 眶混や措度叹などの盖铜叹混を驴く崔む |
| 眶混を崔む矢は下矢脱毋が30912矢, 毖矢脱毋が27068矢赂哼. | |
| (办忍步しやすく, 汗尸滦据にしやすい) |
| (2) | 尸填に泼铜な山附がある |
| (滦条毖矢に滦条が附れていれば溯条材墙) |
| (3) | 胳剁(瓢混)の臼维がある |
| (臼维に滦する胳剁が滦条毖矢にあれぱ溯条材墙) |
| (4) | 年房弄で梧笆した矢を驴く崔む |
| (诺房弄な滦条脱毋を联买材墙) |
脱毋网脱房泣毖怠常溯条(システム叹: EUREKA)は, 滦据尸填の矢滦炳烧けされた滦条コ〖パスを脱いて, 哭1の缄界で溯条借妄を乖う.
笆布, プロトタイプの称借妄について揭べる.
|
|
络翁の滦条脱毋から掐蜗下矢に梧击する下矢脱毋を光庐に联ぶため, まず, 下矢脱毋の够り哈みを乖う. 祸涟に下矢脱毋礁に滦し矢机帽疤のN-gram山附と矢IDを淡峡しておき, 掐蜗下矢に崔まれているN-gram山附を拇べ, その山附を积つ下矢脱毋を铬输下矢脱毋として联买する.
4-1で评られた铬输下矢脱毋を脱いて, (1)掐カ下矢と铬输下矢脱毋の梧击刨, および铬输下矢脱毋の滦条である(2)铬输毖矢脱毋の胳による界疤を雇胃し, 呵も诺房弄な梧击滦条脱毋を联ぶ.
| (1) | 掐蜗下矢と铬输下矢脱毋の梧击刨矢机误(妨轮燎) ごとに惰磊り, 铬输下矢脱毋の矢机误を掐蜗下矢の事びにバブルソ〖トしたときの スワップ眶を答に纷换する[4]. |
| (2) | 铬输毖矢脱毋の胳による界疤铬输毖矢脱毋の粗で鼎奶に附れる胳(芒し, 揣混, 锦瓢混, 涟弥混を近く)の裳刨が呵络のものを 诺房弄な胳とし[4], 铬输毖矢脱毋ごとに 诺房弄な胳の硷梧を驴く崔む矢から界疤烧けする. |
4-2で评られた呵も诺房弄な梧击滦条脱毋の毖矢脱毋を滔曙して 掐蜗下矢の条矢を栏喇する. 掐蜗下矢と梧击下矢脱毋の汗尸舱疥, および梧击下矢脱毋の汗尸舱疥に滦炳する梧击毖矢脱毋の舱疥を拇べ, 梧击毖矢脱毋の汗尸滦炳舱疥を掐蜗下矢の汗尸舱疥の毖条で弥垂する. 呵稿に, 宠脱妨などの嘿かい拇腊を乖う. 附哼, 辉斗庐鼠矢泼铜の山附である眶混や措度叹などに缅誊して汗尸弥垂を活みている.
哭2に塑数及による辉斗庐鼠矢の溯条毋を绩す.
| |||||||||||||||||||||||||||||||||
辉斗庐鼠矢を滦据とする脱毋网脱房泣毖怠常溯条について揭べた. 海稿, プロトタイプ[5]を答に浮皮, 猖紊を裁え, ル〖ルベ〖ス溯条と脱毋网脱房溯条の墓疥を栏かした ハイブリッド溯条システムを菇蜜する徒年である. また, 辉斗庐鼠矢笆嘲の尸填についても溯条滦据を橙络して甫垫を渴めていく.