| 1 はじめに | |
| 2 名詞の意味的関係 | |
| 2.1 名詞間の意味的係り受け関係の表現 | |
| 2.2 使用する意味属性数の最適化 | |
| 2.3 係り名詞と受け名詞の意味属性について | |
| 3 最適な意味属性の組の推定法 | |
| 4 実験 | |
| 4.1 実験データ | |
| 4.2 実験結果 | |
| 5 おわりに | |
| 参考文献 |
最近、結合価パターン辞書( 日本語語繁体系[1]) の 開発により、 日本語動詞の意味は、かなり精度良く解析 できるようになってきた。 しかし、名詞の意味解析で は、依然としてよい方法が知られていない。本論文で は、「の」型名詞句を取り上げ、格助詞「の」を介して 結合された名詞間の意味的関係を記述するのに必要最低 限の単語意味属性の組を明らかにする。
具体的には、任意の2 つの名詞の意味的係り受け関 係が名詞の意味属性間のマトリクス(正方行列) で表現 できると仮定する。そして、名詞の意味属性として結合 価パターン辞書の単語意味属性(約2,700 種類) を使用 し、意味的係り受け解析の精度を低下させないで、使用 する意味属性をどこまで絞り込めるかを明らかにする。
今回使用する意味属性体系[1]は動詞の意味の解析用 に開発されたが、名詞の意味を詳細に分類(約2,700 種 類) しているため名詞の意味解析にも適用できる可能性 がある。そこで、本論文では、名詞の中でも典型的な名 詞句である「の」型名詞句を取り上げ、名詞間の意味的 係り受け規則をこの意味属性体系を使用したマトリクス (係り名詞を行、受け名詞を列) で表現する。
マトリクス上、名詞間の意味的係り受けの有無は、二 者択一的に〇×で表現される。経験的に、その値を人間 の思考実験で正確に決定することはほとんど不可能*で ある。そこで、本論文ではコーパスを使用した標本統計 によって決定することを考える。しかし、結合価パター ンの記述に使用された単語意味属性、約2,700 種類のす べてのペアについて、信頼できる統計量を得ることは現 実的に不可能である。 また、名詞間の意味的関係はより 少数の意味属性で表現できる可能性がある。そこで、標 本統計によって得られた係り受け関係データを用い、意 味属性の数を絞り込むことにより、名詞句解析に必要な 意味属性の数とその組を決定する。
名詞間の係り受け関係を表現するのに適した行列は、 必ずしも正方行列になるとは限らない。 形態素解析の文 法接続表の例+から類推すると、係り名詞を表現する単 語意味属性の数に比べて、受け側の名詞を表現する意味 属性の数はより少なくてすむ可能性がある。 しかし、こ こでは、 まず両者の数及び種類を等しいと仮定して、最 小限の意味属性の組を求めることにする。従って、以下 で求められる意味属性の組は、最終的に目標とするマト リクスの長辺を構成する意味属性の組と考えることがで きる。
以下に示す手順によって、最適な意味属性の組の数を 推定する。
1. 初期マトリクスの設定
「名詞Aの名詞B」型名詞句の名詞A及び名詞B をそ れぞれ意味属性に置き換える。次に、初期値を任意に選 びn ×n の共起マトリクスを作成し頻度統計をとる。
2. 共起マトリクスの拡大
ある任意の意味属性に着目し、その意味属性をその一 段配下の意味属性に置き換え、n’ X n’ の共起マトリク スを作成する。以後、 この新しい共起マトリクスを拡大 共起マトリクスと呼ぶ。
3. 共起頻度を用いた 「名詞A+の+名詞B+の+名 詞C 」の係り受け解析
先ほど作成した拡大共起マトリクスを用い、( AのB ) と(AのC ) の頻度より、「名詞A+の+名詞B +の+名 詞C 」の係り受け解析を行う。係り先は、 以下の式(1) に従い決定した。
| f (A のB ) * w ≧ f (A のC ) ならば((A のB ) のC ) | ||
| f (A のB ) * w < f (A のC ) ならば(A の(B のC )) | ||
| ----(1) | ||
| f (A のB) : (A のB) の頻度 | ||
| f (A のC) : (A のC) の頻度, w : 重み | ||
この時、名詞Aは名詞C より名詞B に係りやすいこと を考慮にいれ適当な重みw (2 〜 2.5) を(A のB) の頻 度に掛けた。そして、重みを変化させながら係り受け解 析を行い、その時の最高の正解率をこの拡大共起マトリ クスを使用した係り受け解析の正解率とした。
4、 手順2 と手順3 を繰り返す
拡大共起マトリクスを使用したときの係り受け正解率 とその前の共起マトリクスを使用したときの係り受け正 解率とを比較し、正解率が上がっていればその拡大共起 マトリクスを採用し、 手順2 へ行く。正解率が下がって いるならば元の共起マトリクスに戻し、 手順2 へ行く 。 手順2 と3 を繰り返し、 どの意味属性を拡大しても係り 受け正解率が上がらなくなった場合終了とする。
使用する名詞句データは新潮文庫の小説100 冊より 抽出した。「名詞A + の+名詞B 」型名詞句は抽出され た約17 万件のうち、 約4,200 件を使用し、 それを共起 分析用データとした。 また「名詞A +の+名詞B +の+ 名詞C 」型名詞句は抽出された約12,000 件のうち、約 1,300件を使用し、それを係り受け解析用データとした。
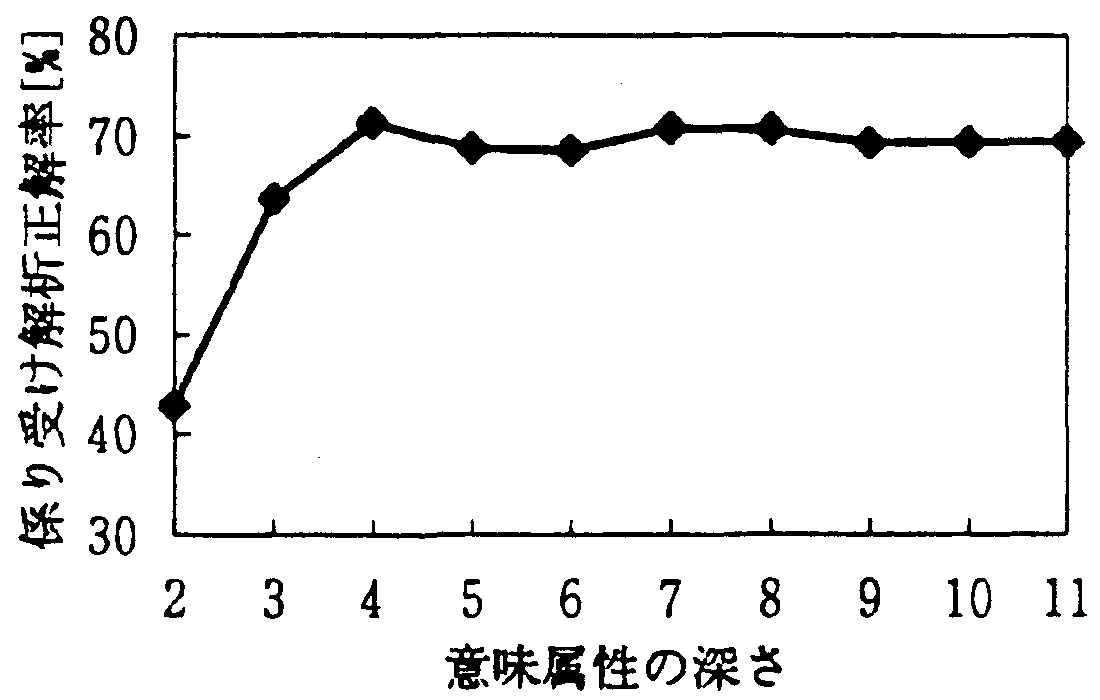
図1 に意味属性体系の深さ ( その深さにある意味属 性を使用する) と係り受け正解率の関係を示す。この図 より、正解率のピークは深さ3 (意味属性数:21) から深 さ5 (意味属性数:256) の間にあることが分かる。
|
|
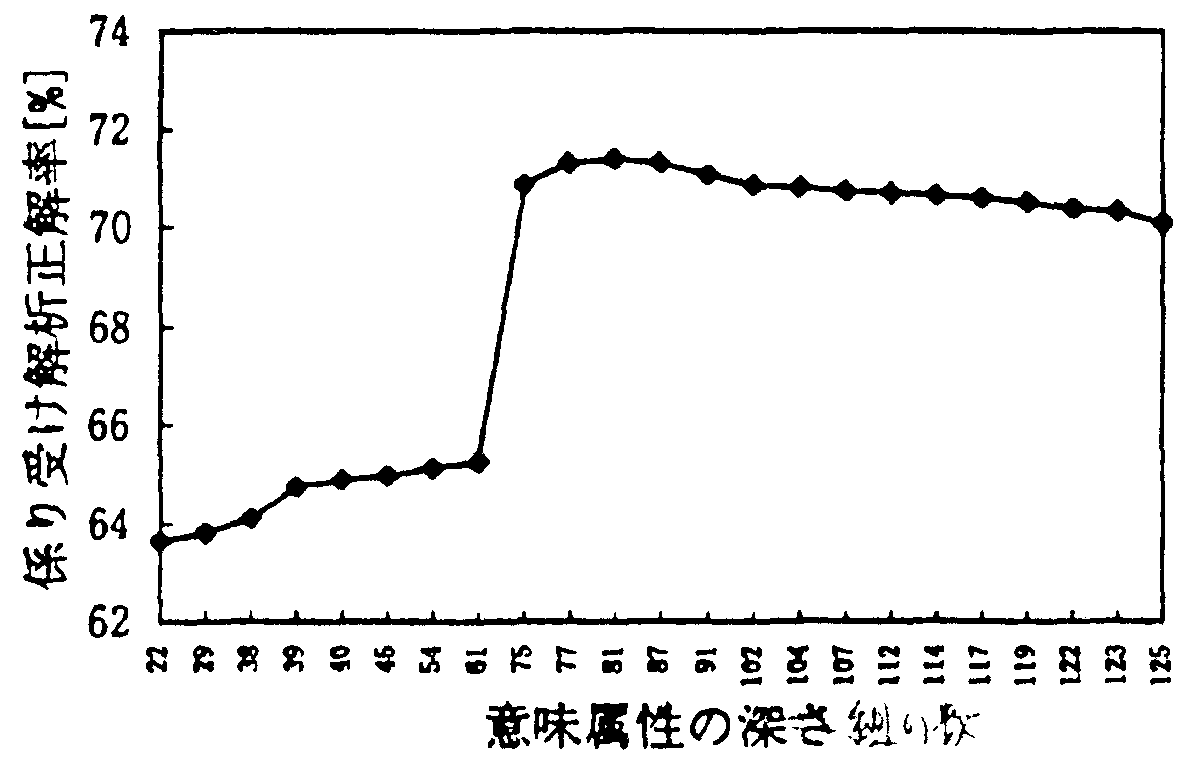
そこで、深さ3 にある意味属性21 種類を初期値とし、 3 章に示した手順に従って21 ×21 の共起マトリクスを 拡大していく。 図2 に意味属性の数と係り受け解析正解 率の関係を示す。 この図より意味属性の組の数を81 個 にした時、係り受け正解率が最大になることが分かる。 よって名詞句解析に使用する「AのB」の共起マトリク スは81 ×81 のマトリクスが最適であることが分かる。
|
なお、81 ×81 (=6,561) の共起マトリクスのうち実 際に共起関係にある「AのB」の数は全体の約1 割にあ たる665 組(頻度1 以上) であった。
本稿では、「の」型名詞句の名詞間の意味的関係を記 述するために必要最小限の意味属性の組の数を推定する 手法を提案し、名詞間の共起関係を共起マトリクスにま とめた。実験により、81 ×81 の共起マトリクスが名詞 句解析に最適という結果が得られた。
今後は、受け側の名詞の意味属性を圧縮しn (名詞A ) ×m (名詞B ,n>m) の共起マトリクスを作成し、再度 比較してみる必異がある。 また、作成した共超マトリク スに意味関係を付与する予定である。