| 1 はじめに | |
| 2 解析アルゴリズム | |
| 2.1 文法規則 | |
| 2.1.1 係受解析のためのデフォルト文法 | |
| 2.1.2 格フレームから文法規則への変換 | |
| 2.1.3 文法規則ID | |
| 2.1.4 接続ID | |
| 2.2 解析アルゴリズム | |
| 3 効率と精度 | |
| 3.1 計算量と所要メモリ | |
| 3.2 解析精度 | |
| 4 おわりに | |
| 参考文献 |
日本語の構文解析では、 文法的な制約を主に用いて 文節間の依存関係を解析する係り受け解析が一般に行 われている。 これは、実用的な文法を記述しようとす ると、省略や語順の入れ替わりを無視できず、英語の ように句構造文法で記述することが困難であるためで ある。 しかしながら、文法的な制約のみで正しい構造 を解析できることは望めず、係り受け解析では複数の 構造候補を出力し、後段の意味解析で意味的に適切な 構造を選択する手法が一般に用いられる。意味解析の 主たる目的は、語句の語義の決定と、語句の意味的機 能(深層格) の決定であるが、この手法では、正しい文 構造の選択という機能も持っていると考えられる。
一方、 日本語の動詞句の意味構造を記述した辞書と しては、格フレーム辞書が挙げられる[2]。格フレーム では動詞の各語義について、取り得る格要素が意味属 性や語表記を用いて記述されている。格フレームは動 詞の語義を決定するための意味辞書ではあるが、正し い文構造を選択する機能を考えると、格フレームこそ が日本語の動詞に関する語彙化された文法規則と捉え ることもできる。
しかし、格フレームを直接用いて構文解析すること もやはり困難であることから、前記のように、一旦係 り受け解析を行う手法が取られている。格フレーム解 析で係り受け構造を選択する場合は、係り受け構造全 体を覆うのに最も適した格フレームの組合せを求め、 それを最適構造としている。しかし文法的に可能性の あるすべての候補を一旦出力することは、その候補総 数が組合せ的に増加するために困難であり、技狩りが 必要である。したがって、係り受け解析が出力する候 補には正解が含まれていない可能性があり、解析失敗 の原因となり得る。
そこで、本稿では、 日本語の格フレームを係り受け 解析の文法規則に変換することにより、構文解析と意 味解析を一度に行なう手法について報告する。本手法 では、文法的制約のみを先行適用することによる正解 候補の脱落という問題は生じず、 また、係り受け解析 と同時に動詞の語義と格要素の深層格も決定されてお り、効率的な解析が可能となる。
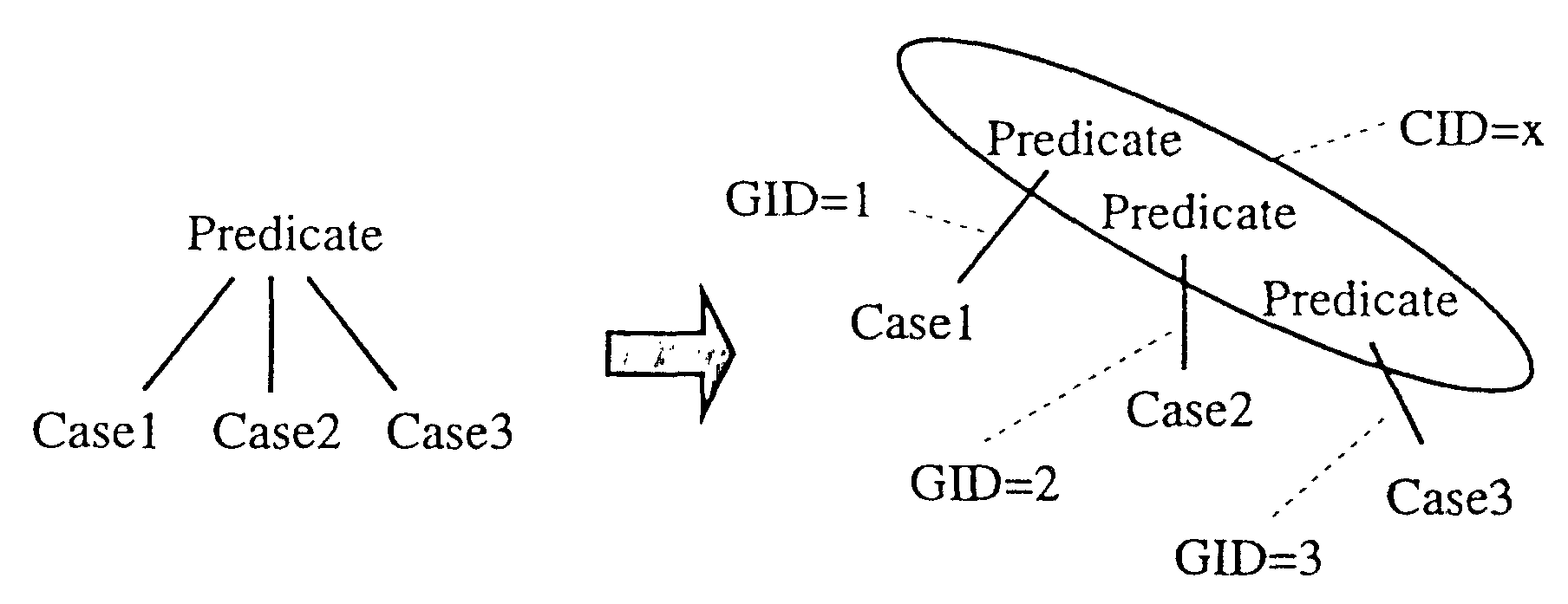
格フレームを係り受け解析に直接適用するための基 本的な考え方は、格フレームを二文節関係だけの文法 規則に分割することである(図1)。 それぞれの文法規 則の右辺には二つの文節だけが記述されており、文法 規則の組合せ適用によって、全体の格フレームが構成 される。分割された文法規則の継りを保持するために、 「文法規則ID(GID)」 と 「接続ID(CID)」 の二つの識 別子を導入する。 GID とCID については後述する。
|
|
本手法では2 種類の文法規則を用いる。 ひとつは、 係受解析のデフォルトとして機能する簡単なCFG 規 則である(図2)。極めて単純化して記述すると、 日本 語は下記の規則を持っている。
|
上記規則に従って、形態素解析は各文節を2 つのシン ボル(品詞) 列と解析するように作成する。 1 つめのシ ンボルは自立部の種類(V またはN) で、 2 つめのシ ンボルは修飾機能の種類(V-V, V-N, N-V, N-N) であ る1 。 後者は、 “修飾元の自立部の種類-修飾先の自立部 の種類” を意味する。 ただし、 文末は修飾機能を持た ず1 つめのシンボルのみである。 また、形態素解析が 単一の品詞を決定することができなかった場合、複数 の品詞候補が出力される。例えば、 「彼と東京に行く」 は以下のように解析される。
図2 にデフォルト文法規則を示す。 それぞれの規則 の右辺には最大2 つの文節のみが含まれており、格要 素が省略された文や文節順が入れ換わった文を受理で きる。
もうひとつの文法規則は、 格フレームから変換して 作られる。格フレームは下記のように記述できる。
Pati = (Predi, Casei1, ... , Casein)
Cascij = (Nounij, Markij)
ここで、 Predi は述語が満たすべき制約を意味し、 Caseij はそれぞれの格要素が満たすべき制約を意味 している。Caseij のうちNounij は自立語部が満たす 制約で、 Markij は付属部が満たす制約である2。
それぞれの格フレームPati を以下の文法規則に変 換する。
| VP | → | NP(Nouni1) N-V(Marki1 ) VP(Predi ,[CID i ]), GID = (i ,1) | |||
| ・ | |||||
| ・ | |||||
| ・ | |||||
| VP | → | NP(Nounin ) N-V(Markin ) VP(Predi,[CID i ]), GID = (i ,n ) |
さらに埋め込み文を解析するために、主部がNP であ る文法規則も合わせて生成する。
| NP | → | VP(Predi,[CID i ]) V-N(φ) NP(Nouni1), GID = (i ,1) | |||
| ・ | |||||
| ・ | |||||
| ・ | |||||
| NP | → | VP(Predi,[CID i ]) V-N(φ) NP(Nounin), GID = (i ,n ) |
それぞれの文法規則には文法規則ID “GID= (i ,j )” が付与され、右辺シンボルのうちVP には接続ID “[CID i ]” が付与される。
格フレームから変換された文法規則は、 同じ述語に 対して2 度適用することはできない。 多重適用を避け るために、 それぞれの文法規則にユニークなGID を 与える。パーサーは新たな構造を生成する時に、既に 適用された文法規則を用いないようにGID を確認し ながら構造を生成していく。
さらに、埋め込み文のための規則、 NP→・・・ は同じ 格要素から変換されたVP→ …と同時に適用されて はならない。同一の格要素から変換される文法規則に は同じGID を与えることにより、 同時適用を避ける。 一方、 自由格のためのデフォルト文法規則はGID を持っておらず、 この規則は複数回適用することがで きる。
分割された文法規則の同一性を保つために、 文法規 則の右辺シンボルのうち、格フレーム木構造の連結点 である述語部にはCID を与える。 この時、同じ述語か ら変換されたシンボルには同一のCID を与える。 CID を持つ文法規則は、 同じCID を持った構造にだけ適用 され、 別々の格フレームがある述語に二重に適用され ることを防ぐ。
デフォルト文法規則にはCID を与えない。 したがっ て、 これらはどの述語にも接続できる自由格として機 能する。
解析アルゴリズムは基本的にはボトムアップチャー ト法である。弧のデータ構造を表1 と表2 に示す。 一 般的なチャート法と比較すると、それぞれの不活性弧 はCID とGID_list を追加情報として持っている。 さ らに、格フレームから変換された文法規則は語彙に関 する制約を持っているので、head を不活性弧中に保持 する。 ただし、 ここで用いる文法では主部は常に最後 のシンボルであり、 また、解析途中で語中の属性値が 書き換わることはないので、 head はend - 1 とend の間の語に常に等しい。 アルゴリズムを図3 に示す。 新しい弧を生成する時にパーサーは以下の2 点を満た すかどうかを調べることにより、格フレームの不適切 な組合せを避けながら解析を進める。
| < (beg, end), grammar, CID, GID_list, head > | |
| beg, end | この弧の範囲 |
| grammar | この弧を生成した文法規則 |
| CID | 接続ID。 もし未定義ならばφ |
| GID_list | 文法の主部を構成する不活性弧のGID のセット |
| head | この弧の主辞 |
| << (beg ,end ) , grammar ) >> | |
| beg , end | この弧の範囲 |
| grammar | 文法規則 |
| ||||||||||||||||||||||||||||||||||||||||||||||||||
本解析の計算量と所要メモリは本質的にチャート法 と同等である。解析中にはパーサーは、 範囲と非終端 記号、 CID、GID-list、headがすべて同じ不活性弧 については一つだけを保持する。 このことは、CID、 GiD_list のバリエーションは非終端記号のバリエー ションと同等であることを意味している3。CID の数 は文法の大きさ |G| に比例する。 また、 ある格フレー ムにおけるCID_list のバリエーションの数は、m を その格フレームの格要素数とすると、2m である。 し たがって、 入力文の長さをn とすると、所要メモリは O (n 22m|G|) であり、 計算量は O (n 32m|G|2) となる。 なお、 格要素の数m は一般に2 〜 3 程度の小さな数 である。
表3 は下記の試験例文をSparc Station 20 で解析し た時の解析時間と所要メモリである。
| 述語数 | 語数 | 解析時間(sec) | 活性弧数 | 不活性弧数 | 候補総数 |
| 1 | 5 | 0.022 | 115 | 29 | 11 |
| 2 | 11 | 0.030 | 381 | 98 | 220 |
| 3 | 17 | 0.053 | 815 | 206 | 8069 |
| 4 | 23 | 0.100 | 1417 | 353 | 364034 |
| 5 | 29 | 0.181 | 2187 | 539 | 18290244 |
| 6 | 35 | 0.301 | 3125 | 764 | 〜 109 |
| 7 | 41 | 0.475 | 4231 | 1023 | |
| 8 | 47 | 0.710 | 5505 | 1331 | |
| 9 | 53 | 1.013 | 6947 | 1673 | |
| 10 | 59 | 1.399 | 8557 | 2054 |
それぞれの名詞(A, B, ...) は格フレーム辞書中のすべ ての制約を満たす。 格フレーム辞書には、NTT の日英 機械翻訳実験システムALT-J/E [3] の結合価パタン辞 書(約14,000 パタン収録) を用いた。 同辞書中に「投 げる」は4 つの格フレームが記載されている。結果は、 計算量がほぼO (n 3) であり、 所要メモリがO (n 2) で あることを示している。
解析精度を調べるために、 本手法によるパーサーを 新聞記事に適用し、格要素の係り先が正しい述語であ る割合を測定した。格フレーム辞書は前実験と同様に ALT-J/E の辞書である。格フレーム辞書は名詞-動詞 の係り受けに関しての辞書であるので、その他の関係 を多数含む実際の文章に本手法を適用するために、い くつかのヒューリスティクスをパーサーに導入した。
これらのヒューリスティクスは、不活性弧のデータ構 造にscore を追加することにより、 不活性弧のスコア として実現する。 パーサーは解析途中で最高点のもの のみを保持する。
実験に用いたのは日経産業新聞の記事から抽出した 200 文である。 うち100 文は格フレーム辞書を作成す る時に例文として参照した文であり、 残りの100 文は
参照していない文である。文は平均46 文字(8.7 文節) であった。
結果を表4 に示す。 それぞれ217 と233 の文節が格 要素と解析され、既知の文については93.1%の係り先 が正解であり、 未知の文については86.7%の係り先が 正解であった。
| コーパス | 格要素数 | 正解数 |
| 既知 | 217 | 202(93.1%) |
| 未知 | 233 | 202(86.7%) |
本稿では、 格フレームから変換したCFG 規則を用 いて、 日本語係り受け解析を行う手法について報告し た。本手法では、係り受け解析と同時に格フレームに よる意味解析が終了しており、効率的な日本語処理プ ログラムの構築が可能である。
今後、 本手法を用いた機械翻訳システムの構築を進 める予定である。