日英翻訳のための日本語解析技術
Japanese Analysis in Japanese-to-English Machine Translation
| 白井諭* | |
横尾昭男** | |
松尾義博* | |
大山芳史* |
|
| Satoshi SHIRAI | |
Akio YOKOO | |
Yoshihiro MATSUO | |
Yoshifumi OOYAMA |
あらまし
機械翻訳システムをはじめとするあらゆる言語処理システムでは,
まず, 入力文に対する解析処理として, 単語を調べる処理(形態素解析)と,
文の構造を調べる処理(構文解析)が実行される.
解析処理の後に行われる様々な処理は,
一般に解析結果が正しいことを前提として構築されているため,
解析処理の成否はシステムの処理性能に大きく影響を及ぼす.
本論文では, 日英機械翻沢システムALT-J/E(以下, ALT-J/E)の解析処理のうち,
中核となる形態素解析, 構文解析について技術的な課題とその解決方法を述べる.
また, 日英翻訳における前編集の自動化をねらいとして導入した自動書き替えの方法を示す.
Abstract
Natural language processing systems, such as machine translation systems, analyze
input sentences first. The process is composed of two sub-processes, that is,
morphological analysis for splitting words and syntactic analysis. The process is
very important because the analysis results affect the following processes, so they
must be performed as accurately as possible.
This paper describes analysis in ALT-J/E, a Japanese-to-English machine translation
system, and discusses problems and solutions. It also describes automatic rewriting
that can replace human pre-editing.
[ NTT R&D, Vol.46, No.12, pp.1399-1404 (1997.12). ]
[ NTT R&D, Vol.46, No.12, pp.1399-1404 (December, 1997). ]
* NTTコミュニケーション科学研究所
NTT Communication Science Laboratories
** ATR音声翻訳通信研究所
ATR Interpreting Telecommunications Research Laboratories
(c)日本電信電話株式会社 1997
INDEX
1 まえがき
機械翻訳システムをはじめとするあらゆる言語処理システムでは,
最初に, 入力された言語表現にどのような単語が含まれるか(形態素解析),
それらがどのように構成されているか(構文解析)などを調べる解析処理が実行される.
解析処理の後に行われる様々な処理は,
一般に解析結果が正しいことを前提として構築されているため,
解析処理の成否はシステムの処理性能に大きく影響を及ぼす.
本論文では, ALT-J/Eの解析処理について, 技術的な課題と解決方法を述べる.
ALT-J/Eの解析処理では, 入力文に対し,
形態素解析, 構文解析, 自動書き替えの3つの処理が順に適用される.
形態素解析処理は, 入力文を単語に分割する処理で,
多段解析法に基づく基本処理とパタンマッチによる補正処理から構成される.
多段解析法の開発により, 単語当りの解析精度99.8%が達成された.
構文解析処理は, 形態素解析結果に基づいて, 入力文の構造を調べる処理である.
長文に対する適用性を高めるため,
長文に多く出現する従属節と名詞句それぞれの相互関係に対する解析ルールの精密化を行った結果,
一部作成中ではあるが, 文当りの解析精度90%が達成される見込みである.
日本文書き替え処理は, 形態素解析や構文解析により得られだ情報に基づき,
入力文の単語や構造を英訳しやすいものに置換する処理である.
翻訳システムを適用する際,
翻訳システムが処理しやすい表現に翻訳対象の文章を書き改める前編集が行われることが多い.
本論文では, 前編集の自動化をねらいとして導入した自動書き替えの方法と効果を示す.
2 形態素解析
形態素解析は自然言語処理において最も基本となる技術であり,
日本語の形態素解析の正解率は新聞記事などの一般テキストに対して
単語単位で97〜99%といわれている(1).
新聞記事では1文平均40文字(20単語)であるため,
1文単位の正解率に換算すると80%程度となるため,
実用上は解析誤りを1桁程度減少させる必要がある.
これに対して, ALT-J/Eで使用する多段解析法に基づく形態素解析処理では,
処理の精密化により単語単位の正解率99.8%を達成した.
2.1 多段解析法による形態素解析
多段解析法は, 解析精度と処理能力を両立させるため,
文字種の違いに着目して仮に設定した範囲内(仮文節)で
あらゆる単語の組合せを検定する局所的総当り法をベースとし,
構文や意味の情報が有効となる複合語解析や
同形語†判別などには,
部分的に深く解析することを特徴とする(2).
処理の概要を以下に述べる.
| |
・ステップ1: 仮文節境界の設定 |
| 字種の変化点(ひらがな→漢字・カタカナ等, 句読点→非句読点)に着目して
仮文節境界を設定する.
仮文節は局所的総当り法による単語認定を行うための処理単位である.
|
|
|
| ・ステップ2: 単語候補の抽出 |
| 単語意味辞書(3)を検索し, 仮文節内の単語候補を抽出する.
仮文節境界を挟んで混書き語が位置すれば, 仮文節境界を補正する(図1). |
|
図1 仮文節境界の補正
|
|
|
| ・ステップ3: ひらがな列分割パタンの抽出 |
| 仮文節内のひらがな列に対する単語候補が連接可能かどうかを文法的に検定し,
ひらがな列分割パタンとして可能なものをすべて生成する. |
|
|
| ・ステップ4: ひらがな列分割パタンの絞込み |
| 単語意味辞書記載の単語の優先・
非優先の指定†と
仮文節内の自立語数・付属語数を総合的に評価して,
ひらがな列分割パタンを一意化する. |
|
|
| ・ステップ5: 漢字列分割パタンの抽出 |
| 仮文節内の漢字列に対する単語候補が接続可能かどうかを文法的に検定し,
漢字列分割パタンとして可能なものをすべて生成する(図2).
|
(例) 漢字列分割パタンの作成(全34通り)
図2 漢字列分割パタンの作成
|
|
|
| ・ステップ6: 意味的係り受け関係の解析 |
| 漢字列分割パタンのそれぞれに対し,
格関係†・
副詞修飾等の構文的関係や
意味属性†による
単語間の意味的関係を解析する
(図2の色矢印)(4)(5).
|
|
|
| ・ステップ7: 漢字列分割パタンの絞込み |
| 漢字列分割パタンに対して, 分割数最小法を基本とし,
意味的関係や単語の優先・非優先の指定を加味し評価が高いものを選択する
(図3)(4).
|
(例) 漢字列分割パタンの絞込み(意味的係り受けを考慮した分割数最小法)
| 分割パタン |
単語数 | 関係数 | 評価値 | 採否 |
| 畜産│物価−格安│定法 |
4 | 1 | 3 | × |
| 畜産−物│価格−安│定法 |
6 | 2 | 3 | × |
| 畜産│物価│格│安│定法 |
5 | 0 | 5 | × |
| 畜産−物│価格−安定−法 |
6 | 3 | 2 | 〇 |
| 畜産│物価│格−安定−法 |
5 | 2 | 3 | × |
( │ は単語境界, −はステップ6で意味的関係ありとされた単語境界)
図3 漢字分割パタンの絞込み
|
|
|
| ・ステップ8: 単語列分割パタンの抽出 |
| 漢字列分割パタンとひらがな列分割パタンとの文法的な相互制約により,
仮文節内の単語分割列パタンを絞り込む. |
|
|
| ・ステップ9: 単語列分割パタンの決定 |
| 文節境界の設定, 同形語の多義の絞込みなどを行い,
形態素解析の最終結果とする.
|
新聞記事965文(311記事, 21,303単語)を対象に, 一般語12万語のほか,
人名・地名・企業名などの固有名詞20万語, 専門用語5万語など,
合計40万語が収録された単語意味辞書(3)を用いて
解析実験を行い, その結果を分析した.
未知語登録後の形態素の境界判定の精度は, 再現率99.80%, 適合率99.86%であった.
境界設定が正しい形態素の品詞認定(約300分類)の正解率は99.81%であり,
これらの積を形態素解析の総合的正解率とすると,
解析精度は99.5%となる(6).
また, 文節境界の設定では, 再現率99.71%, 適合率99.58%であった.
解析誤りを分析した結果, 技術的改良により約半数の誤りが解決できる見込みであることから,
総合的正解率99.8%の達成を目指して改良を進めている.
2.2 形態素補正処理
多段解析法による形態素解析では, 大規模で詳細な情報を持つ辞書と
精密なアルゴリズムにより単語当り約99.8%程度の解析精度を達成した.
この段階に至るまでに要した辞書の開発や解析アルゴリズムの改良の工数を考えると,
その延長で残り約0.2%の誤りに対処するのは容易ではない.
形態素解析の誤りは, 辞書の情報と解析アルゴリズムのバランスに
微抄な狂いが生じたときに起りやすい.
例えば, 「畜産/物/価格/安定/法」が正しく分割される反面,
「現/代用/語」のように四字熟語を1-2-1に分割する場合が多発するようになった.
このような誤りは単語の個別事情により生じるため,
誤りの種類をある程度パタン化することができる.
そこで, あらかじめ指定した要注意語の前後の単語に着目して, 誤りかどうかを判定し,
誤りを回復させる処理を形態素解析の直後に付加することにより, 形態素解析の精度を
向上させることにした(7)(8).
同様の着眼により,
不要な多義も併せて絞り込むことが可能になる(9).
このように, 外付けの処理を行うことにより, 汎用性には多少欠けるが,
形態素解析の改良が容易に行えるようになる.
3 構文解析
日本語の構文解析は, 語順入替りや省略に強い
係り受け解析†が
適しているとされるが, 従来のように文法情報と経験則を中心にした方法では,
比較的矩い文なら70%以上の解析精度で解析することが可能であるが,
長文に対する解析精度は十分ではなかった.
長文解析の失敗要因としては, 従属節の相互関係と
名詞句の並列関係の解析失敗があげられる(10).
そこで, 文の構成要素の種類に応じて文法的性質を再分類し,
経験則の適用の仕方を見直した係り受け解析の方式を提案した.
係り受け解析は, 次の5つのステップにより構成される.
| | ・ステップ1: 文節の連接に従って
述語句†を認定し,
独立度†の強さに応じて
それらを52種に分類する. |
| ・ステップ2: 述語句の分類とその独立度に基づいて
述語句間の係り受けを決定する. |
| ・ステップ3: 文節の形式と類似性などに基づき並列関係を検出する. |
| ・ステップ4: 並列関係のうち, 部分的な並列関係があれぱ文節を適宜分割する. |
| ・ステップ5: 多項関係により連体・格・副詞修飾等を決定する. |
以下では, 従属節と名詞句の分類について述べ, 本方式による解析精度を示す.
3.1 従属節関係解析
文献(11)で言語学的見地から提案されている従属句の分類を
工学的見地から改良・詳細化した従属節述語の分類を
提案した(12).
文節の連接に従って述語句を認定し,
独立度の強さに応じてそれらを52種(大分類13×細分類4)に分類する(表1).
独立度の強さに従うことにより, 97.0%の従属節の係り受け関係が誤り率0.7%が一意に決定される.
その後, 一意に決定されなかったものに対し,
経験則のうち近くに係るものを優先するというルールを使うことにより,
文当りの従属節関係の解析精度は98.4%となる.
表1 従属節述語の分類
| 種類 | 大分類 | 備考 |
従
属
節 |
|
A | 〜シつつ,〜シながら(=継続), |
| A+読点 | 〜スル│ことに│加えて |
| B (通常) |
通常:〜シ,〜シて, 〜スルので,〜スル│ため, 名詞+で(助動詞)
強中止:〜シており, 〜スル│ことで |
| B (強中止) |
| B+読点(通常) |
| B+読点(強中止) |
| C | 〜スルが, 〜スルし |
| C+読点 |
| 引用節 |
引用相当(→B) | 〜スルよう(依頼する) |
| 引用(→C+読点) | 〜スルと(発表する) |
| 連体節 |
限定修飾(→B) | 一般名詞へ係る |
| とらえ直し(→B+読点) | 形式名詞へ係る |
| 主節 |
文末の述語句 |
|
| 細分類 | 備考 |
|
|
名詞性 | 名詞+指定の助動詞 |
| 形容詞性 | 形容詞, いわゆる形容動詞 |
| 自動詞性 | 自動詞, 受身を伴う他動詞 |
| 他動詞性 | 他動詞, 使役を伴う自動詞 |
|
3.2 名詞相互関係解析
文献(13)で提案されている単語並びの類似性や構文的特徴に基づく
並列関保の検定方式を改良し, 部分並列の認定も可能な名詞句の並列関係の解析方式を
提案した(11).
表2の適用順に従って, 順に並列の可能性を検出していく.
4番目の直近の並列を検定する際には, 部分並列の可能性を調べることにより,
90%以上の精度で並列が認定される見込みである.
表2 並列の認定基準(件数は新聞記事500文中)
| 適用順 | 認定基凖 | 件数 | 新聞記事の例 |
| 1 | 表記の同じ語 | 13 |
他上七階, │他下一階 |
| 2 | 類似の意味属性 | 39 |
米国, │東南アジア |
| 3 | 構造的特徴 | 33 |
ビデオテープ, │テキストなど |
| 4-1 | 直近の並列 | 18 |
現地法人や│〜社の│販売ルート |
| 4-2 | 部分並列あり | 10 |
日本, │米国布場 |
| 適用外 | 解析困難 | 1 |
近視, │遠視, │弱視の│視力回復と│視力低下を│予防する│プログラム |
| 件数合計 | 114 | |
3.3 解析精度
本方式に基づいて処理系を試作し, 新聞記事文300文の解析精度を測定した.
全300文に対して解析多義†の中に
正解が含まれ(ALT-J/Eの従来処理では95%), うち, 1位正解率は91%(同70%)となり,
長文に対しても十分に高い解析精度が得られることを
確認した(表3)(12)(14).
表3 提案方式の解析精度
| 文字数 | 1位正解 | 1位同点 | 2位以下 | 多義 |
| 6-20 | 26 (100%) | 0 | 0 | 1.1 |
| 21-40 | 87 (96%) | 4 (4%) | 0 | 2.6 |
| 41-60 | 93 (88%) | 9 (8%) | 4 (4%) | 6.4 |
| 61-80 | 52 (85%) | 4 (7%) | 6 (8%) | 7.1 |
| 81-111 | 15 (94%) | 1 (6%) | 0 | 20.1 |
| 300文計 | 273 (91 %) | 18 (6%) | 9 (3%) | 10.3 |
4 自動書き替え
日英翻訳システムを現実の文書に適用するには,
翻訳困難な表現や構文を機械翻訳に適した形式に書き改めておく前編集が必須とされている.
従来, 文字列の置換えによる前編集の自動化が検討されてきたが,
同一の文字列でも置き換えるべき場合とそうでない場合があり,
その識別が容易でないことから, 自動化は困難とされてきた.
これに対し本研究では, 日英翻訳システムの内部で,
文字列だけでなく構文解析結果を書き替えることにより,
副作用のない自動書き替えを実現した.
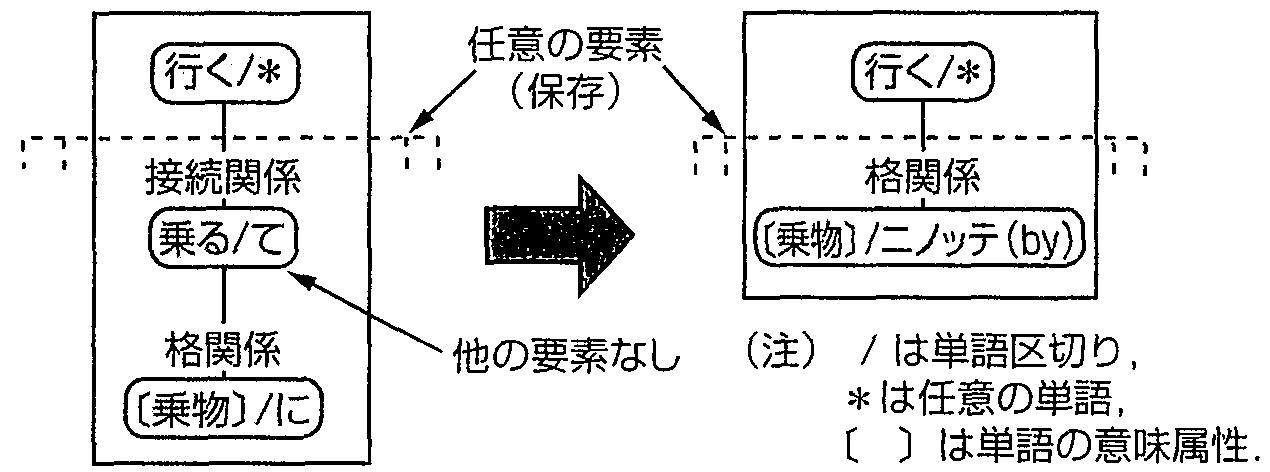
4.1 書き替えの方法
本方式では, (1)単語の詳細な文法的・意味的属性を使用して書き替えルールを記述する,
(2)原文の解析が進行し, 書き替えルールの適用条件の判定に必要な情報が
得られた時点(本研究では構文解析後)で書き替えを実行する,
ことにより副作用のない自動書き替えを行う
(図4)(15)(16).
また, システムの内部で書き替え処理を行うことから,
一般的な書き替え(日本語内書き替え)のほか,
日本語の表現としては機械翻訳に適した表現が見いだせない場合でも,
英語の表現を指定することにより訳出を制御する方法
(擬似的日本語への書き替え)も併せて実現した.
また, 書き替えルール作成の効率化を目指し,
ルールの類型化を進めるとともに(17),
支援系と一体の処理系を構築した(18).
|
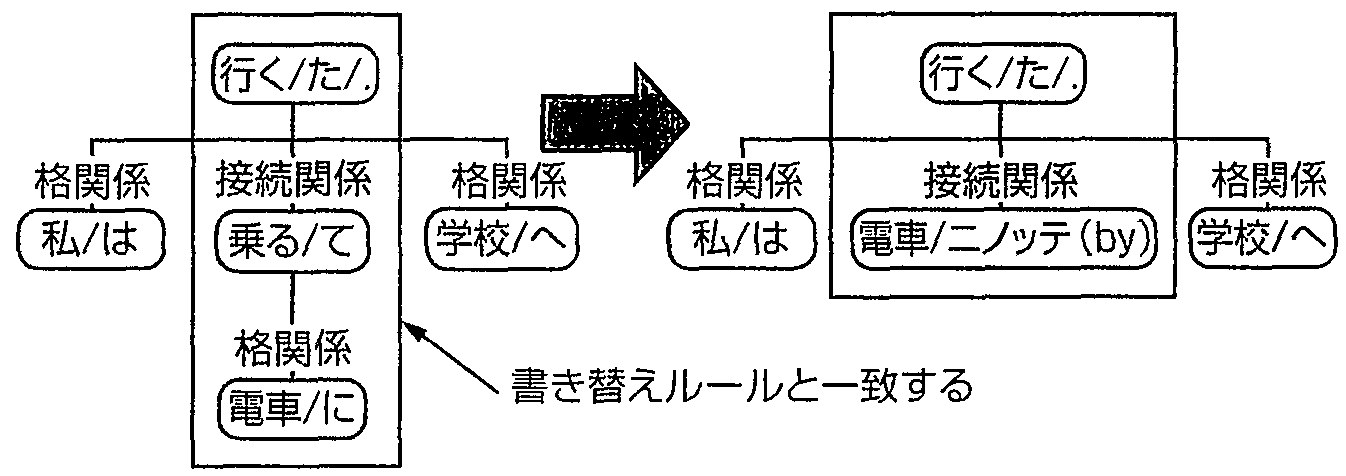
【書き替えルールの例】「〜に乗って〜」→「〜ニノッテ(by)〜」
【書き替えが適用される場合】「私は電車に乗って学校へ行った.」
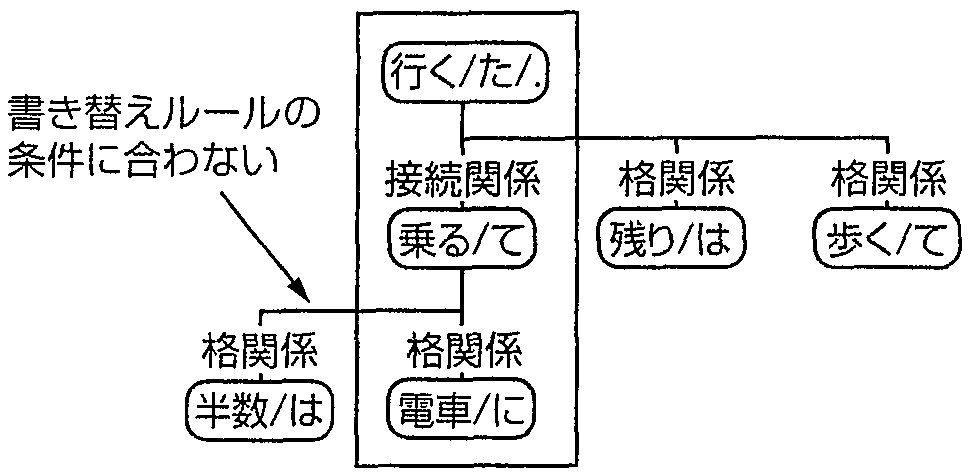
【書き替えが適用されない場合】「半数は電車に乗って残りは歩いて行った.」
|
図4 書き替えルールの例とそれの適用される例および適用されない例
4.2 書き替えの効果
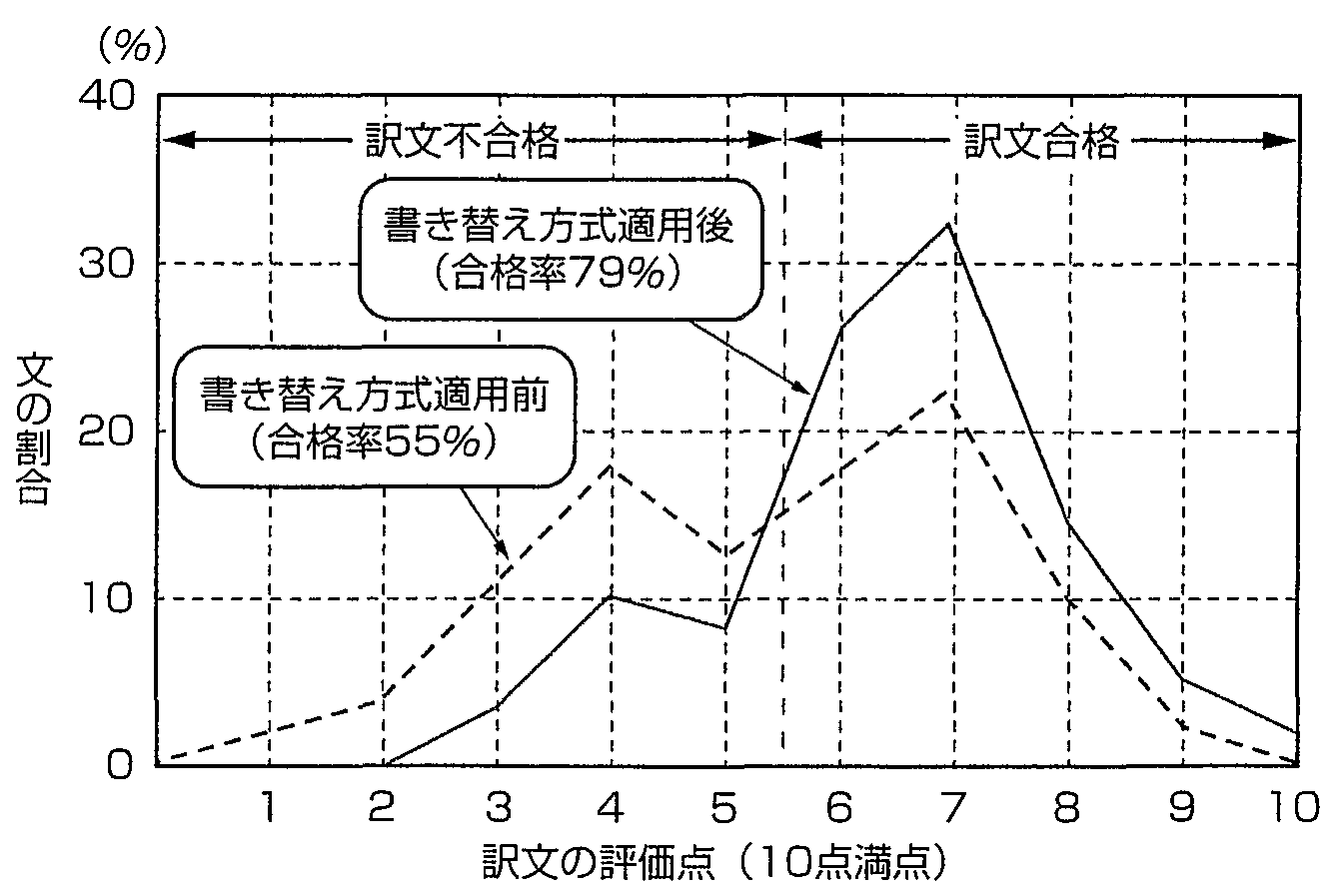
新聞記事102文を用いた実験によれば, 本方式は44文(43%)に適用され,
適用された文の訳文合格(英語だけで意味の分かる訳文)は,
従来の11文(20%)から33文(75%)に向上した.
その結果, 全体としての訳文合格率は55〜79%に向上した
(図5)(16).
図5 書き替えによる訳文品質向上効果
5 あとがき
本論文では, ALT-J/Eの解析処理のうち, 中核となる形態素解析と構文解析について,
また, 前編集の自動化をねらいとして導入した自動書き替えについて,
技術の概要と到達点を述ベた.
これらの処理は, 評価した範囲では高精度を達成しているが,
まだまだ広範な言語現象に対応するには不十分な点がある.
評価する対象範囲を拡大し, 処理精度の向上を図ることが今後の課題である.
文献
- (1)
- 長尾他:
“自然言語処理技術のこれからの課題”,
「自然言語処理の技術動向」調査調査会, 1994.
- (2)
- 宮崎・大山:
“日本文音声出力のための言語処理方式”,
情報処理学会論文誌, 27, No.11, pp.1053-1061, 1986.
- (3)
- 池原・宮崎・横尾:
“日英機械翻沢のための意味解析用の知識とその分解能”,
情報処理学会論文誌, 34, No.8, pp.1692-1704, 1993.
- (4)
- 宮崎:
“係り受け解析を用いた複合語の自動分割法”,
情報処理学会論文誌, 25, No.6, pp.970-979, 1984.
- (5)
- 宮崎・池原・横尾:
“複合語の構造化に基づく対訳辞書の単語結合型辞書引き”,
情報処理学合論文誌, 34, No.4, pp.743-754, 1993.
- (6)
- 白井・横尾・池原・奥山・宮崎:
“多段解析法による日本語形態素解析の精度”,
情報処理学会第50回全国大会, 1R-2, 3, pp.37-38, 1995.
- (7)
- 白井・池原・河岡・上田:
“日本文書き替え処理における制御ルールの機能別構成”,
情報処理学会第47回全国大会, 6P-4, 3, pp.201-202, 1993.
- (8)
- 横尾・白井・奥山・河村・池原:
“日本語形態素解析の誤りの回復について”,
言語処理学会第3回年次大会, C4-4, pp.429-432, 1997.
- (9)
- 白井・池原・井上:
“近接単語の並びに着目した形態素解析多義の絞り込み”,
情報処理学会第52回全国大会, 5B-5, 3, pp.77-78, 1996.
- (10)
- 白井・横尾・木村・小見:
“従属節の依存関係を考慮した日本語係り受け解析の精度”,
第49回情報処理学会全国大会, 1G-10, 3, pp.115-116, 1994.
- (11)
- 南: “現代日本語の構造”,
大修館書店, 1974.
- (12)
- 白井・池原・横尾・木村:
“階層的認識構造に着目した日本語従属節間の係り受け解析の方法とその精度”,
情報処理学会論文誌, 36, No.10, pp.2353-2361, 1995.
- (13)
- 黒橋・長尾:
“長い日本語文における並列構造の推定”,
情報処理学会論文誌, 33, No.8, pp.1022-1031, 1992.
- (14)
- 白井・横尾・木村・小見:
“従属節の依存関係を考慮した日本語係り受け解析について”,
言語処理学会第1回年次大会, A1-3, pp.29-32, 1995.
- (15)
- S. Shirai, S. Ikehara and T. Kawaoka:
“Effects of automatic rewriting of source language
within a Japanese to English MT system”,
In Proc. of the TMI, pp.226-239, Kyoto, 1993.
- (16)
- 白井・池原・河岡・中村:
“日英機械翻訳における原文自動書き替え型翻訳方式とその効果”,
情報処理学会論文誌, 36, No.1, pp.12-21, 1995.
- (17)
- 白井・池原・阿部・松尾:
“日本文書き替え処理における制御ルールの類型情報の抽出”,
第49回報処理学会全国大会, 4K-10, 3, pp.243-244, 1994.
- (18)
- 白井・池原・松尾・兵藤:
“日本文書き替え処理における制御機能の構成について”,
第49回報処理学会全国大会, 4K-11, 3, pp.245-246, 1994.
Footnote

|
白井 諭
コミュニケーション科学研究所主幹研究員.
昭和55年入社. 主に自然言語処理(特に日本語処理) の研究に従事.
現在, 機械翻訳技術の研究に従事.
昭和53 年大阪大学工学部通信工学科卒業.
55 年同大学院工学研究科通信工学専攻博士前期課程修了.
電子情報通信学会. 情報処理学会・ 言語処理学会会員.
平成7 年第30回日本科学技術情報センター賞(学術賞), 人工知能学会1994 年度論文賞受賞.
|
|

|
横尾昭男
ATR音声翻訳通信研究所第四研究室長(前コミュニケーション科学研究所).
昭和57年入社. 主に日英機械翻訳技術の研究に従事.
昭和55 年電気通信大学電気通信学部電子計算機学科卒業.
57年同大学院電気通信学研究科電子計算機学専攻修士課程修了.
電子情報通信学会・情報処理学会・ 人工知能学会・言語処理学会会員.
平成7 年第30回日本科学技術情報センター賞(学術賞) 受賞.
|
|

|
松尾 義博
コミュニケーション科学研究所研究主任.
平成2 年入牡. 主に機械翻訳の研究に従事.
昭和63年大阪大学理学部物理学科卒業.
平成2年同大学院理学研究科修士課程修了.
情報処理学会・ 言語処理学会会員.
|
|

|
大山 芳史
コミュニケーション科学研究所主幹研究員.
昭和54年入社. 主に日本文音声出力システム,
漢字電報システムなど自然言語処理・ 対話処理の研究実用化に従事.
現在, 機械翻訳システムの研究実用化に従事.
昭和52 年大阪大学工学部電子工学科卒業.
54 年同大学院工学研究科電子工学専攻博士前期課程修了.
IEEE ・ 電子情報通信学会・ 情報処理学会・ 言語処理学会会員.
平成6, 7 年日本電信電話株式会社社長表彰.
|
■用語解説■
同形語
2種類以上の解釈が何能な語.
例えば, 「平野」は, 一般名詞「へいや」と固有名詞「ひらの(姓)」が考えられる.
また, 「行く」と「行う」は同形語ではないが,
「た」がついたかたち「行っ(た)」では同形語となる. (Return)
単語の優先・非優先の指定
例えば, ある単語が一般名詞と固有名詞の両方の解釈が可能である場合,
通常は一般名詞の解釈を優先するほうが正解率が高い.
しかし, 「こうぼく/たかぎ(高木)」や「きゅうじょう/みやぎ(宮城)」では
固有名詞(後者)のほうが一般的であるため, これらの語では一般名詞を非優先語,
固有名詞を優先語として辞書に記述する. (Return)
格関係
「何が」, 「何を」などの要素と動詞や形容詞との間に生じる関係.
ただし, ここでは「価格-安定」を「価格(が)安定(する)」と考えて格関係とみなす.
(Return)
意味属性
名詞の意味的な用法を分類したもの.
例えば, 「米国」は〔国名〕, 「東南アジア」は〔地域名〕で,
いずれも〔場所〕の分類下に属する. (Return)
係り受け解析
2つの文要素に着目し, それらの関係を検定する処理を操り返し行うことにより,
文全体の構造を検定する方法. (Return)
述語句
動詞, 形容詞やそれらに助動詞等がついた表現(述語)と,
述語等が複数組み合わさって全体として一体的に働く表現の総称として用いる.
例えば, 「(〜を)発売するのを始め...」では「発売する」, 「のを」, 「始め」の3文節であるが,
まとまった表現であるため, 全体を1 つの述語句とする. (Return)
独立度
従属節の範囲内で内容がまとまっている度合いが高いものを独立度が強いと定義した.
文献(11)には, 主語の有無や出現する助動詞に着目するにより
ABCの3段階に分類する方法が提案されている. (Return)
解析多義
1つの表現に対し2つ以上の解釈が可能な場合をいう.
「渡辺刑事は血まみれになって逃げる賊を追いかけた」
(「日本語の作文技術(本多勝一)」より)では, 「血まみれになって」いるのが渡辺刑事,
賊のいずれとも考えられる. (Return)