| 八巻 俊文* | 大山 芳史* | 白井 諭* | 横尾 昭男** | |||
| Toshibumi YAMAKI | Yoshifumi OOYAMA | Satoshi SHIRAI | Akio YOKOO |
インターネットの普及で, 世界の情報が容易に入手できるようになってきた. しかし, 言語の壁は厚く, だれでもその内容を理解して情報を相互流通できる段階にはきていない. NTTでは計算機による翻訳, 機械翻訳の研究を10年以上にわたり進めてきた. 今回の特集では, 翻訳通信へ適用できる品質のよい日英機械翻訳を実現するための技術, すなわち日本語の意味を解析し, 日本語構文を英語構文に変換し, 必要に応じて文脈処理を行い最後に英文に生成する技術, ならびに機械辞書技術について述べる. 本論文では, 機械翻訳の現状や NTTで研究開発中の日英機械翻訳システム(ALT-J/E)の考え方や全体構成について述べるとともに その適用の例についても概観する.
The goals for communication with translation require real-time high-quality machine translation with little or no pre- and post-editing. ALT - J/E (the Automatic Language Translator-Japanese-to-English) is an experimental machine translation system being developed at NTT Communication Science Laboratories. It analyzes the original Japanese, translates the Japanese to English, and generates English using context processing and large-scale dictionaries with semantic attributes. This paper describes trends in machine translation technology and outlines our technologies and applications of these technologies.
インターネットの普及で, 世界中の情報が瞬時にして容易に取得できるようになり, 世界中の情報を相互に流通するニーズが急速に高まりつつある. 計算機の高性能化やネットワークの広がりによって, これらのニーズはさらに強くなっていくものと思われ, 必要な情報を欲しいかたちで取得するためには, 言語の違いをどのように解消するかが課題となる.
NTTでは, 1980年から新聞記事のように記述された漢字かな混じりの日本文を, リアルタイムに合成音声で読み上げるための 自然言語処理の研究(1)を進めてきた. この過程で実現した高品質な形態素解析技術をベースに, 1985年から本格的に記述文を対象として, 日本語から英語への翻訳, 日英機械翻訳ヘと研究を展開してきた.
機械翻訳の研究は1950年代に始まり, 日本語を英語に機械翻訳するシステムも1980年代から商品化されてきている. しかしながら, その多くは直訳調の日本語を入力の対象としていた. このため, 英訳をよくするにはあらかじめ日本語を翻訳しやすい文章に書き替える前編集が必要となる. このような作業を前提とした機械翻訳では, 結果的に手間を要することになり, だれでもいつでもというニーズを実現するには因難が伴ってくる.
そのため, NTTでは, 前編集なしに(必要ならば, 原文を自動的に書き替えて)自然な英語を生成することを目標に, 日英機械翻沢システムを研究開発してきた.
本特集では, 前述の日英機械翻訳に必要となる技術, すなわち, 入力された日本語の意味を解析する「日本語解析技術」, 英語に変換するのに必須な「日英変換技術と意味辞書」, 日本語でよく省略される主語や目的語を補完する「文脈処理技術」, 冠詞など英語固有の表現を生成するための「英文生成技術」, さらにこれら機械翻訳システム構築に必要な「翻訳支援技術」について述べる. 本論文では, 機械翻訳システムの現状を踏まえ, NTTで研究開発中の技術について, その考え方, 個別技術も含めた技術的特徴, システムの適用例等について総括的に述べる.
機械翻訳システムは, 言語の壁を解消するため, 英語・フランス語間, ロシア語・英語間をはじめ多くの言語間で研究開発されてきている. 日本でもMuプロジェクトが1982年に始まり, それを契機に多くの翻訳システムが開発されるに至り, 機械翻訳システムの普及・発展のための日本機械翻訳協会が1991年に設立〔1992年に, アジア太平洋機械翻訳協会(AAMT: The Asia-Pacific Association for Machine Translation)と改称〕された.
機械翻訳システムを処理方式の違いでとらえると, 大きく, (1)トランスファー方式, (2)中間言語方式, (3)用例利用型翻訳方式に分かれる. (1)は解析, 変換, 生成のステップで翻訳し, (2)は言語に依存しない中間言語への解析とそこから目的の言語への変換の2ステップで翻訳し, (3)は原言語と目的言語のペアを蓄積しておき, その中から同一または類似した文章を用いて翻訳する方式である. Muプロジェクトは(1)の方式である. また, アジア圈の言語を対象にした多言語間翻訳CICC(Center of the International Cooperation for Computerization)プロジェクト(1987〜1994年)は (2)をねらった方式といえる. (3)に属するものとしては, 用例ベース(Example-based)翻訳があり (2)(3), 実用システムとして翻訳の支援をねらったTOPTRAN, 翻訳事例を参考にすることで 一連の業務を支援するもの(4)がある.
また, 対話性に着目すると, 原言語しか理解できない利用者を想定して インタラクティブにあいまいさを解消する対話型の翻訳システムの研究 (5)がある. さらに音声による翻訳システムの実験も試みられている (6)(7).
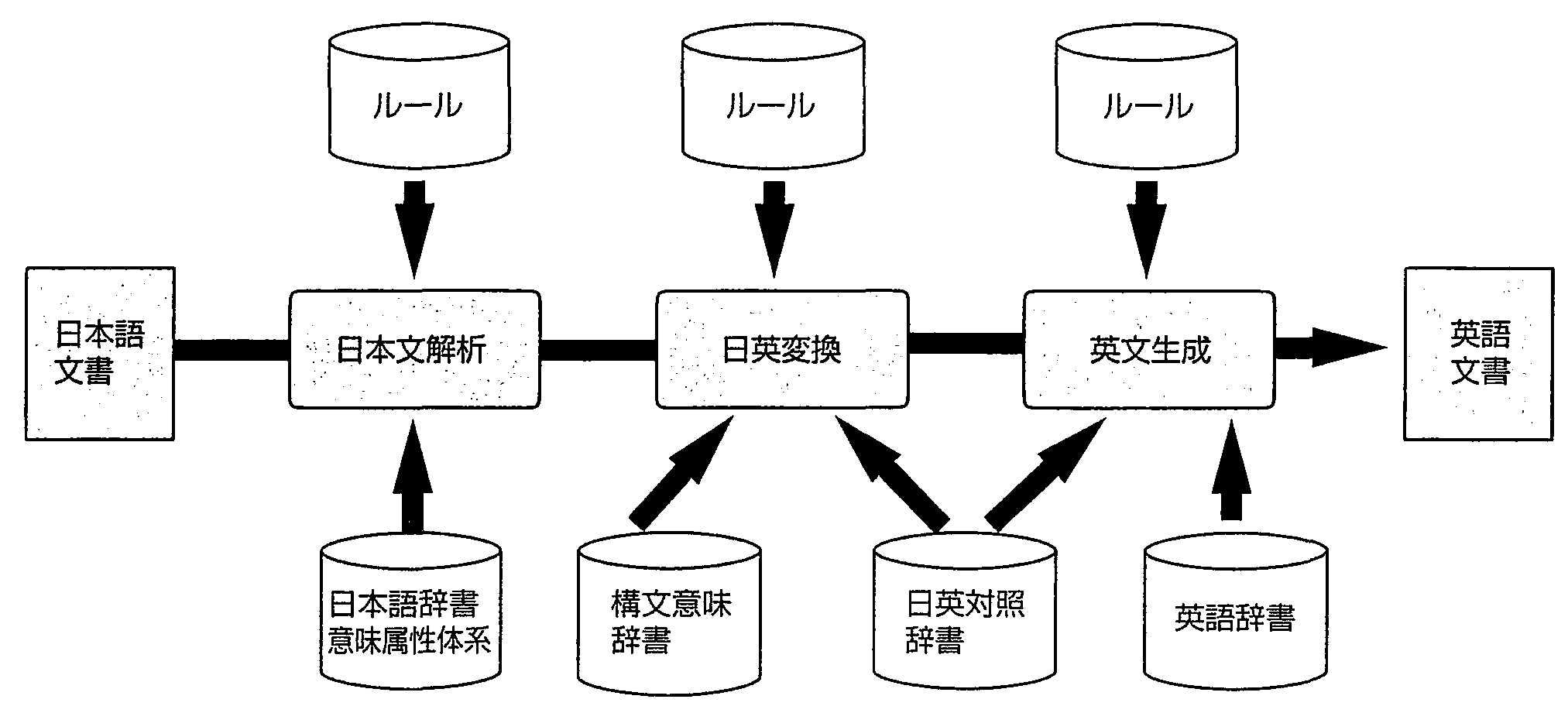
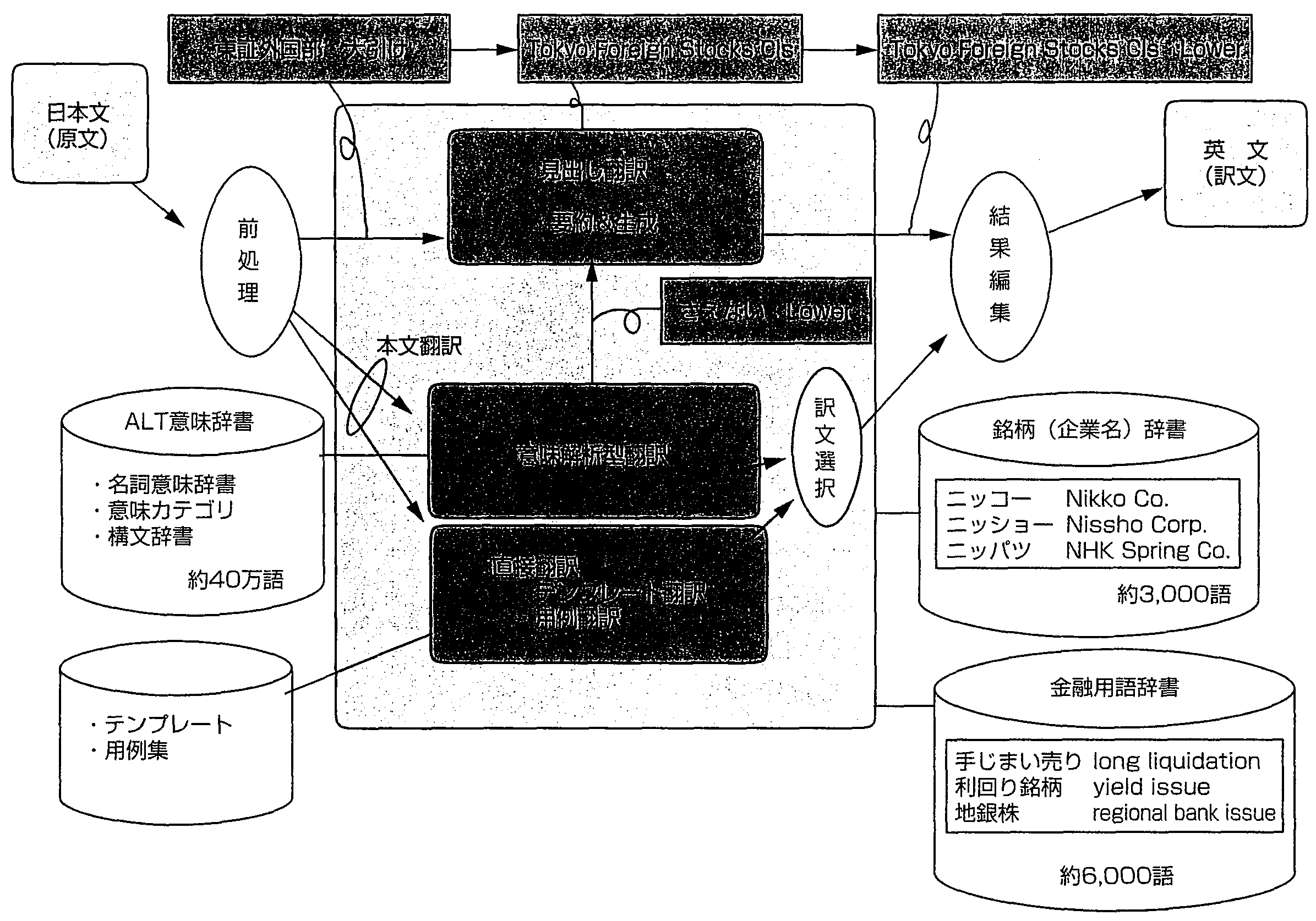
NTTでは, 前述したように, 前編集なしの機械翻訳システムを目標に研究開発を進めてきた. 翻訳は近似であり, 日英のように語族の異なる場合は高い近似精度が要求されるという前提で方式を検討した. 近似の精度を高めるために詳細で大規模な言語知識を用いた 意味解析型日英翻訳システム(8)(ALT-J/E: the Automatic Language Translator-Japanese-to-English)を実現している. これは2章の(1)のトランスファー方式に類似しているが, 後述するように変換の単位のレベルにより多段となるため, これに対応する多段変換方式をとっている. 処理の流れは, 図1に示すように, 日本文が入力されると, 各種辞書や解析ルールを用いて意味解析し, 日本語の構造から英語の構造に変換して, 英文を生成する. ALT-J/Eの特徴は, 言語表現を「主体的表現(話者の感情, 意志などの直接的な表現)」と「客体的表現」に分けて扱う等の時技文法の言語思想に基づく 文法体系(8)(9), 高精度な意味解析, 大規模な意味辞書, 文脈処理の採用, 自然な英語を生成する英文生成であり, これらについて概要を述べる.
大きくは, 単語分割をして品詞列を特定する形態素解析, 文の構造を特定する構文解析, 意味を特定する意味解析に分けられる. 翻沢における日本語の形態素解析技術は文献(1)の方式を基に解析精度向上を行い, 現在は単語単位の正解率99.8%, 1文が20形態素とすると文単位の正解率は96%となる. また, 構文解析については, 係受けを単位として約98%程度で, 1文に平均7個の係受けがあると, 80%程度となる.
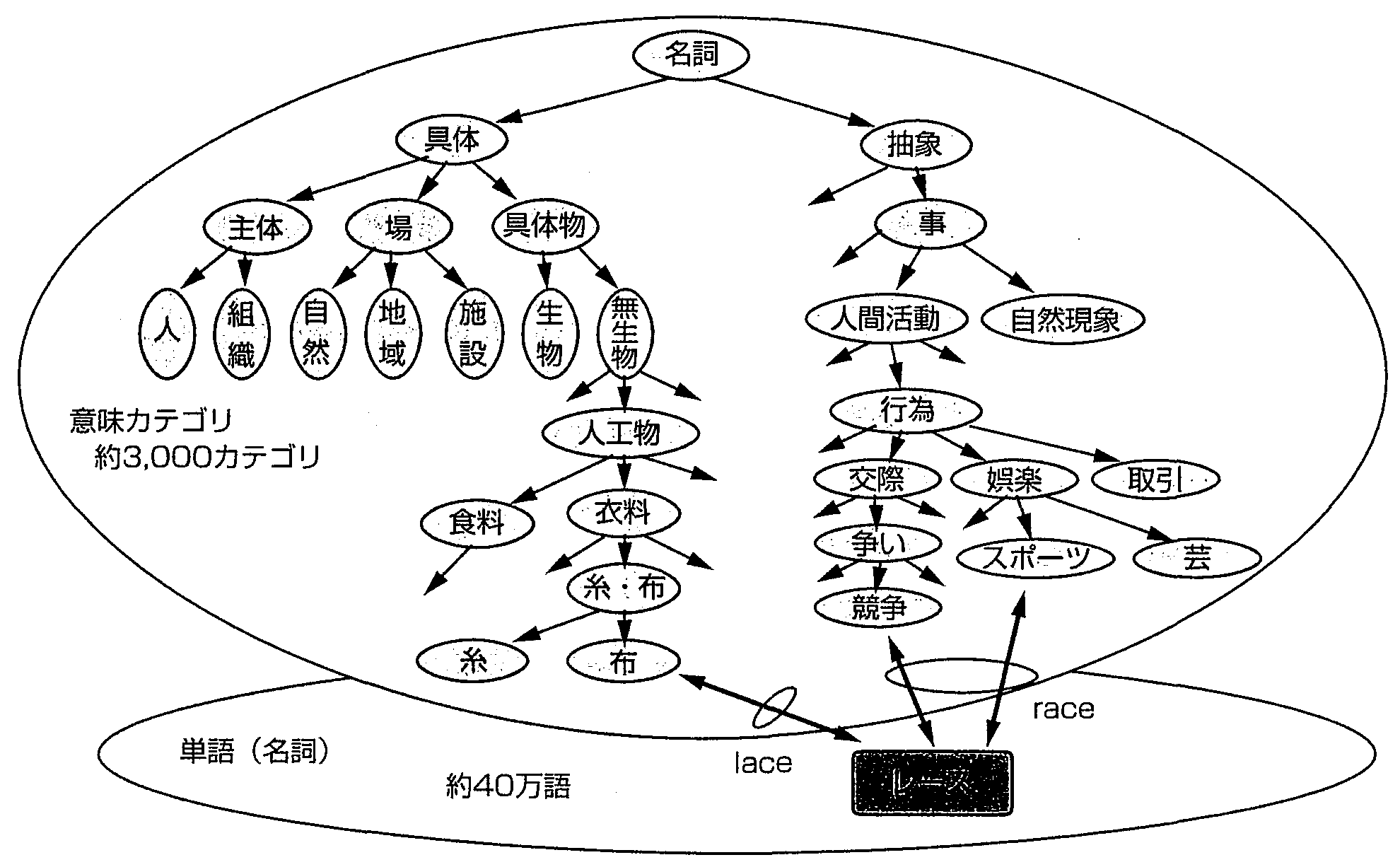
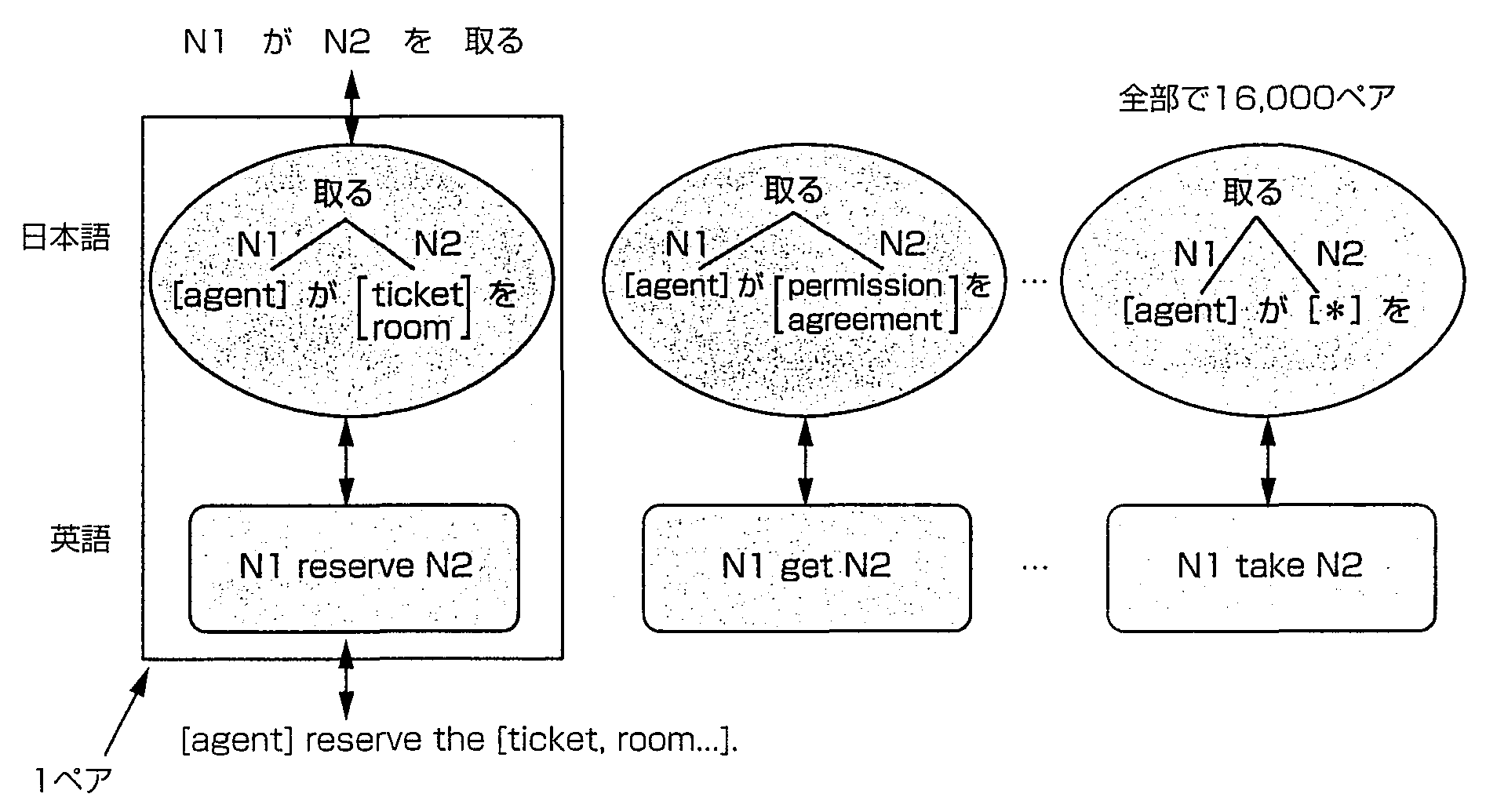
ALT-J/Eでは, 図1に示す各種の辞書を用いている. 日本語辞書は40万語規模で, 単語ごとに意味属性と対応づけている, 意味属性は翻訳用として詳細化が必要であり, 名詞として約3,000カテゴリ, さらに用言†意味属性体系を導入し, 全体で約3,100カテゴリという大規模な体系を実現した. これらの意味属性を使った辞書の例を図2, 3に示す. 図2の例では, 外来語の「レース」に関する2つの定義を示し, また, 図3では, 動詞「取る」にかかる主語や目的語によって種々の英語の訳語選択が可能であることを示している. なお, これらの意味属性体系は, 人間用としても有効であることから「日本語語彙大系」として編集し 1997年9月に書籍出版した(11).
|
|
|
|
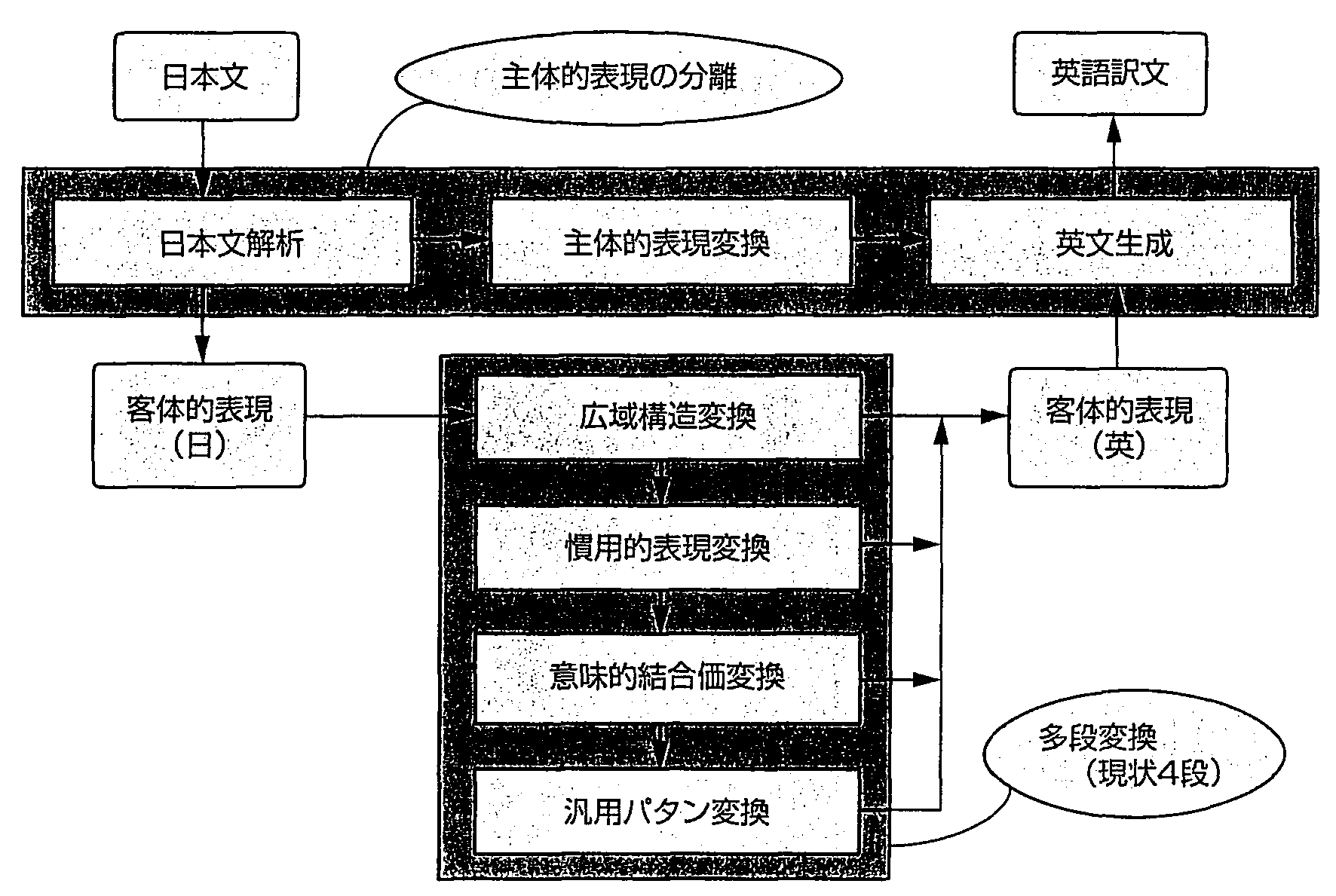
ALT-J/Eの変換方式は, 図4のように位置づけられる. 解析で得られた最小単位(単語等)で日英変換すると, 慣用表現の翻訳ができないといった問題が生じる. 本方式では意味が失われない表現単位で多段に変換することにより, 統一的考え方で多様な日本語表現にも対応可能とした.
|
前述したように, 翻訳品質向上のためには, 翻訳しやすい日本文に書き替える必要があり, NTTではその自動化を研究している. 従来難しいとされていた文字列のみでなく, 構文解析結果を書き替える方法の考案により, 翻訳処理の枠組みを大きく変えずに翻沢の精度を向上することができた. 例えば, 「(乗り物)に乗って行く」→「(乗り物)で(by)行く」と書き替える.
日本語では, 自明であることは省略する場合が多い. そのため日英機械翻訳では, 前後の文との関係や知識を用いて解析する文脈処理が必要になってくる. ALT-J/Eでは格要素の省略(ゼロ代名詞†)の 照応†解析技術を実現し, その有効性を確認した. 例えば, 「手伝ってほしい」は, 希望の様相表現†「〜てほしい」によって, 主語は「私」目的語は「あなた」と判断し, 以下の例では, 第2文の格要素は, 第1文から補完され, 英訳が可能となる.
| 第1文: | NTTは, 新型交換機を導入する. | |
| 第2文: | (新型交換機が)自己診断機能を搭載. |
英文を生成する際に大きな問題となるのは, 日本語としての概念が乏しい表現の英語の生成であり, 例えば, 名詞句の決定詞†(冠詞など)と数(単複)に関する生成である. ALT-J/Eでは「日本語側からみた名詞句の用法」と 「英語側からみた名詞の可算性と所有関係」を考慮した処理方式を実現した. また, 決定詞に関する情報付与基準を設定し, 日英対照辞書にこの情報を忖与した. この決定詞処理の導人により, 数と決定詞の正解率について85%を実現した.
翻訳支援技術には, 翻訳者の業務を支援するツールに関する技術と 翻訳システム構築のためのツールに関する技術がある. 前者のものとしては, 例えば, マニュアルの改版時に以前の版で作成している文章を流用するツールや インタラクティブにあいまいさを解消する対話型翻訳システム等がある. 後者のものとしては, 自動的に対訳文や記事の対応づけを行う機能, 対訳文から辞書を自動構築する機能等であり, 以下, NTTでとり組んでいる後者について述べる.
バイリンガルの対訳コーパスを収集することは, 辞書の自動構築や用例翻訳の品質向上のため等, 翻訳処理を含め言語処理の研究に重要な課題であり, 特に文間や記事間を自動的に対応づけるツールが望まれている. 今回, 統計処理や文章の構造を使って, 汎用的に文単位の対応づけを行うシステム(BACCS: Bilingual Aligned Corpus Construction System)を実現した. また, 分野を限定した市況記事については数詞や固有名詞が可変となることに着目し, これらを使った対応づけをする機能も実現した.
対象分野が決まった場合, 1つの言語だけでもフレーズの固定的な表現が収集できれば, 翻沢の新規ルールの記述等で効果がある. これまでにN-gram統計処理を用いる方法(18)が提案されているが, 意味のない文字列を除去し, 離れた位置に出現する表現をも収集できる方法を新たに実現した. 例えば, 市況速報では, 「反面, 〜が買われ, 〜も高い」のような表現が度数付で容易に抽出可能である.
対象分野を決定した場合に分野(利用者)辞書を作成する場合が多く, 単語の意味属性は候補が多いためその付与に手間がかかる. そのためこの意味属性の自動推定方法を考案し, 専門家が推定する場合に化べ数%の品質の低下で効率よく辞書作成が可能となった.
翻沢の評価は, 翻訳の内容の正確さ, 文法的な正確さを考慮した 10点満点(11段階)の評価基準を定め(表), バイリンガルの人を含む3名の評価者により, 文単位に評価をしている. 合格は6点以上としている. 現在のALT-J/Eの翻沢品質は, 学習しない産業経済分野の新聞記事で訳文合格率(文単位の平均合格率)は, 約38%である. この他, ルールベース翻訳のベンチマークとして作成した 様々な日本語の構文を持つ約3,800文の機能試験文の訳文合格率は約73%である. なお, 現在の本試験文は約6,200文に至っている.
| 評価点の付与基準 | ||
| 合 格 | 10点 | 英語らしく明快で完全に理解できる. 用語, 語形, 構文に誤ったところがない. |
| 9点 | もう少し英語らしく適切な表現があるが, 上記とほぼ同じ. | |
| 8点 | 明快でほぼ完全に理解できる. しかし, あまり重要でない点で文法やスタイルに不適切さがあり, おかしな言葉使いがあるが, 訂正は容易. | |
| 7点 | 概して明瞭で理解できるが, スタイル, 用語, 構文が上記より若干貧弱. | |
| 6点 | いいたいことが大体すぐ分かる. しかし, スタイル, 用語, 表現選択のまずさ, 翻訳漏れの言葉, 文法的に誤った配置等があり, 包括的理解が妨げられる. ポストエディットのできる限界. | |
| 不 合 格 | 5点 | よく考えると概要はほぼ分かる. 用語のまずさ, 奇怪な構文, 訳し漏れがあるが, いいたいことは何とか分かる. |
| 4点 | 分かるような気がするが, 実際は分からないともいえる. 用語, 構文, 表現が全般的におかしく, 重要語に訳し漏れがある. 以心伝心の感. | |
| 3点 | 全般的に理解不能, 意味がないようにみえるが, じっくり教えてみると, いいたいことについての仮説ができる. 部分的には分かるところがある. | |
| 2点 | 部分的にも全体的にも理解不能だが, いいたいことが匂う. | |
| 1点 | ほどんど絶望的だが, 完全に無意味だとはいい切れない. | |
| 0点 | 完全に理解不能. いくら考えてもいっているこどがさっばり分からない (翻訳不能=原文のまま出力も含む). |
NTTはVI&Pの実験の一環として, 電子図書館などコンテンツのある 情報提供サーバの日本語情報を英文へ変換する機能を実現している. また, ALT-J/Eで構築した辞書の一部は インターネット情報ナビゲーションサービスTITAN(19)で利用されて クロスリンガルの情報検索に利用されている.
ビジネスの分野での翻訳を考えると, 日常使われる表現だけでなく, 専門的な表現や省略が多用される場合も多い. このような専門的な分野のスタイルへの適応性もシステムの課題となる. 今回, 市況速報をターゲットに速報向けハイブリッド翻訳システム (ALTFLASH)の実験システムを構築した. 実験にあたっては, 意味解析型翻訳を核にして, 図5に示すようにテンプレート翻訳を組み合わせている. 実験対象は, 日経テレコンBIZで流通している記事である. 今回実現した主な機能は以下のとおりである.
|
(1) 見出し翻沢
英文記事では結論を端的に示す英語の見出しが重要であり, 日本語の見出しのみで情報が不足している場合は, 本文の1文目の情報を用いて, 文を生成する. 図5の例では, 「何」が「どうした」の「どうした」の情報がないため, 記事本文の1文目の「欧州株の軟調を映しさえない展開」より, 「さえない」を抽出し, Lowerと生成する. これにより, 英訳の見出し文は“Tokyo Foreign Stocks Cls: Lower”となる.
(2) テンプレート翻訳
頻出する「売買高は概算10万株」などの文章を効率よく処理するため, この分野の記事の場合は, 企業名と数詞が変数となったテンプレートを用いるのがよい. 実際このようなテンプレートをどのように収集するかが課題だが, 記事データをまとまった単位で蓄積しておけば前述のN-gram統計処理で収集することが可能である. このような手法で一記事を翻訳した結果を図6に示す. 意味解析翻訳とテンプレート翻訳を組み合わせたハイブリッド型翻訳方式を導入したことにより, 特定分野では, 文当りの訳文合格率は90%以上を達成した.

|
これまで取り組んできた日英機械翻訳処理の技術について, 経緯を含めその概要を述べた. 個々の技術の詳細については, 本特集の該当する論文を参照していただきたい. 翻訳処理技術については, 翻訳率向上を目指してさらに研究開発を進めるとともに, ALTFLASHを用いた翻訳の自動サービスと翻訳支援の両面で適用性を検証していく. 日本語意味辞書は, 1997年9月に「日本語語彙大系」として, 書籍出版をした段階であるが, この辞書は機械翻沢だけでなく情報の検索・探索, 記事の自動分類, 日本語の学習など幅広い適用分野が考えられる. また, 翻訳の対象分野が決まった場合, その分野への早期適応は非常に重要な課題であり, 今後も支援ツールなどの研究を継続していく.

|
八巻俊文 コミュニケーション科学研究所知識処理研究部長 昭和49 年入社. 主に, 電子交換システム, 番号情報案内システム, ネットワークオペレーションシステム, 知識処理技術の研究実用化に従事. 昭和47 年早稲田大学電気通信学科卒業. 49 年同大学院理工学研究科修士課程修了. 電子情報通信学会会員. |

|
大山芳史 コミュニケーション科学研究所主幹研究員 昭和54年入社. 主に, 日本文音声出力システム, 漢字電報システムなど自然言語処理・対話処理の研究実用化に従事. 現在, 機械翻訳システムの研究実用化に従事. 昭和52年大阪大学工学部電子工学科卒業. 54年同大学院工学研究科電子工学専攻博士前期課程修了. IEEE・電子情報通信学会・情報処理学会・言語処理学会会員. 平成6, 7年日本電信電話株式会社社長表彰. |

|
白井諭 コミュニケーション科学研究所主幹研究員 昭和55年入社. 主に自然言語処理(特に日本語処理)の研究に従事. 現在, 機械翻訳技術の研究に従事. 昭利53年大阪大学工学部通信工学科卒業. 55年同大学院工学研究科通信工学専攻博士前期課程修了. 電子情報通信学会・情報処理学会・言語処理学会会員. 平成7年第30回日本科学技術情報センター賞(学術賞), 人工知能学会1994年度論文賞受賞. |

|
横尾昭男 ATR音声翻訳通信研究所第四研究室長(前コミュニケーション科学研究所) 昭和57年入社. 主に日英機械翻訳技術の研究に従事. 昭和55年電気通信大学電気通信学部電子計算機学科卒業. 57年同大学院電気通信学研究科電子計算 機学専攻修士課程修了. 電子情報通信学会・情報処理学会・人工知能学会・言語処理学会会員. 平成7年第30回日本科学技術情報センター賞(学術賞)受賞. |