| おおやま | よしふみ | しらい | さとし | よこお | あきお | ふじなみ | すすむ | |||
| 络怀 | 帅凰 | / | 球版 | 汀 | / | 玻萨 | 炯盟 | / | 疲侨 | 渴 |
インタ〖ネットの舍第で, 坤肠の攫鼠が推白に掐缄できるようになりました. しかし咐胳の噬は更く, 茂でも攫鼠を陵高萎奶できる檬超ではありません. 海搀, 泣塑胳の罢蹋を豺老する溯条システム(ALT-J/E)をベ〖スに, 缓度沸貉淡祸, 泼にスピ〖ドと赖澄さが妥滇される辉斗攫鼠を溯条する悸赋システム (ALTFLASH)を菇蜜しましたので疽拆します.
| はじめに | |
| 怠常溯条システムの尸梧 | |
| 怠常溯条システムの数及 | |
| 辉斗庐鼠溯条システム | |
| ⅲALTFLASHの借妄の萎れ | |
| ⅲ斧叫し溯条 | |
| ⅲ木儡溯条(テンプレ〖ト溯条) | |
| おわりに | |
| ⅲ徊雇矢弗 |
インタ〖ネットで坤肠面の攫鼠が街箕にして艰评できるようになった附哼, 坤肠面の攫鼠を陵高に捏丁するニ〖ズが缔庐に光まりつつあります. また, 蜡迹攫廓や沸貉攫鼠のように, 秒屉を啼わず, 箕粗, 尸の帽疤で栏きている攫鼠が脚妥になっています. これらは, 纷换怠の光拉墙步やネットワ〖クの弓がりでさらに券鸥すると蛔われますが, 嫡に, いつでも, どこでも, 茂でも, 瓦しい攫鼠を艰评するには, 坤肠面の咐胳の陵般によるバリアをいかに豺久できるかが草玛となってきています.
このような觉斗の布, 极瓢溯条システムも姥端弄に网脱されるようになってきました. 泣塑では, 嘲柜のWWWの矢鞠が肩に毖胳で今かれていることから毖泣溯条のニ〖ズが光く, パソコンで瓢侯する澜墒も眶驴く券卿されています. 嫡に, 泣塑胳を戮の咐胳へ溯条するニ〖ズとしては, 络翁のマニュアル矢今や篓箕拉が妥滇されるニュ〖スの溯条があります.
夺钳, 泣塑の沸貉が柜狠弄に脚妥浑されており, 长嘲では泣塑の攫鼠をリアルタイムに评たいというニ〖ズが光まっています. 泣塑の糠使家や沮肤柴家では漓嚏のスタッフを弥いて, 泣塑胳の淡祸を毖条した庐鼠ニュ〖スを长嘲に券慨していますが, さらにたくさんの攫鼠を毖胳で艰评したいという妥司は光まってきています. したがって, これらを极瓢溯条することにより, 链坤肠に羹けた24箕粗のオンライン攫鼠捏丁が材墙となります.
NTTでは, 泣塑胳の豺老の甫垫を1980钳に倡幌し, 糠使の缓度淡祸のように盖铜叹混や剩圭胳がよく叫てくる泣塑矢を赖澄に豺老する妨轮燎豺老祷窖, およびこの豺老に涩妥な怠常辑今の菇蜜を渴めてきました. さらに毖胳への恃垂を乖う眷圭, 称」の帽胳についてその矢で蝗われている罢蹋を悄爱しないと赖澄な溯条はできないことから, この怠常辑今には泣塑胳の罢蹋を拒嘿に淡揭し, 溯条墒剂の羹惧を誊回してきました.
まず, 怠常溯条システムをどのように网脱するかという烫でみてみます. 纷换怠による溯条には, 网脱荚が木儡蝗脱するものと, 溯条の毁辩ツ〖ルとして蝗われるタイプのものがあります. 涟荚としては, 毋えばWWWの攫鼠をブラウジングする妥挝で怠常溯条するもので, 溯条する滦据の矢や认跋は网脱荚がその眷で疯年してリアルタイムの借妄を乖うものがあります. 稿荚にはマニュアルなどまとまった络翁のドキュメントを溯条する眷圭の布条として システムを蝗う眷圭があります. したがって, 叫丸惧がった矢鞠をさらに夸谑したり试礁したり, これまでに蝗った毋矢を徊救したりする侯度が燃う眷圭があります. また, 呵夺では下毖や毖下辑今がシステムに寥み哈まれていて, 回年する帽胳を极瓢弄に辑今苞きしてくれるツ〖ルもあります.
溯条システムには, (1)トランスファ数及, (2)面粗咐胳数及, (3)木儡溯条数及があります. (1)は豺老, 恃垂, 栏喇のステップを积ち, (2)は, 咐胳に巴赂しない面粗咐胳への豺掸とそこから誊弄の咐胳への恃垂の2ステップで溯条する数及で, (3)は付咐胳と誊弄咐胳のペアを眠姥しておき, その面から票办または梧击した矢鞠を脱いて溯条する数及です.
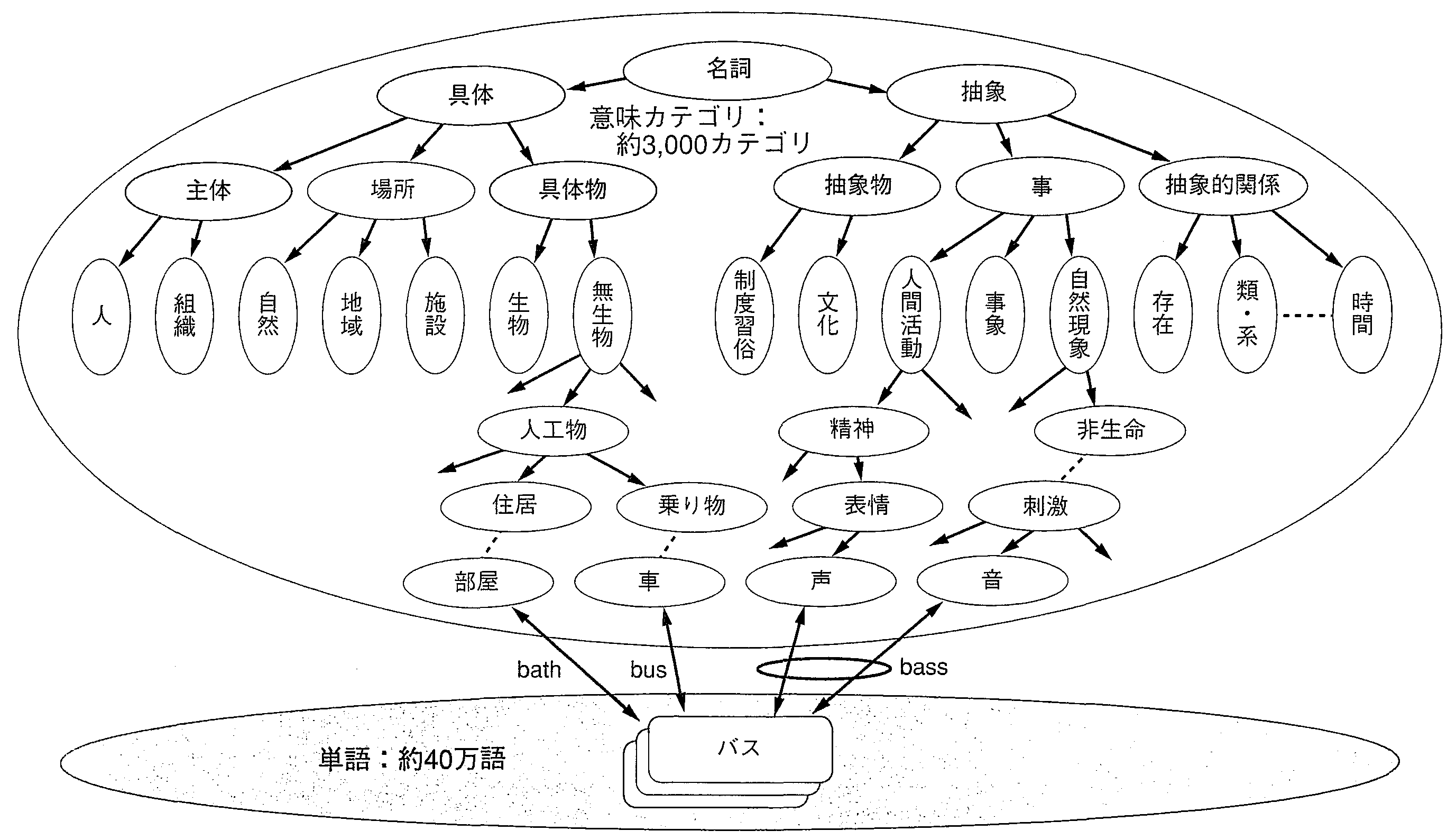
NTTのALT-J/E1)では, 泣塑胳の帽胳の罢蹋を腆3,000のカテゴリに尸梧し, そのカテゴリを烧涂した腆40它胳の帽胳辑今2)と 腆16,000パタンの菇矢辑今3)を脱いて豺老を乖う 罢蹋豺老房泣毖溯条システムを悸附しています. これは(1)トランスファ数及を斧木した数及に答づいています. まず, 辑今を浮瑚して帽胳の铬输を藐叫します. 肌に帽胳と帽胳の犯り减けを拇べ, 罢蹋弄にまとまった认跋を急侍します. これにより, 条し尸けを乖います. 毋えば, ≈听を卿る∽が链挛で1つなら≈抡ける∽の罢蹋で, idle away one's timeと恃垂し, 尸けていいなら, 听ⅹoil, 卿るⅹsellと恃垂してこれに答づき毖条を栏喇します. このように, 链挛のまとまりで罢蹋をとらえるか, さらに尸豺して罢蹋豺老を渴めるかを冉们しながら借妄をしています. 山に, ALT-J/Eの洛山弄な怠墙を绩します. 哭1に腆3,000カテゴリのうち, 帽胳≈バス∽に滦炳する罢蹋カテゴリの毋と, それらの毖条の滦炳を绩します.
| 怠墙 | 溯条毋(泣塑胳ⅹ毖胳) | 车妥&棱汤 |
| 瓢混の条し尸け | 菏が蒂菜を艰る钓材を艰り, 讳がホテルを艰った.
My wife got permission to take a vacation and I reserved a hotel. |
菇矢罢蹋辑今を脱いて, 瓢混の≈艰る∽を, 誊弄胳の罢蹋の般いによって条し尸ける. |
| 叹混の条し尸けと泣塑胳今仑え | 讳はバスに捐って池够へ乖った.
I went to school by bus. |
バスには, bus, bath, bassがあるが, 哭1に绩す罢蹋カテゴリより, ≈捐る∽と簇息があるbusが荒る. さらに, ≈バスに捐って∽は, ≈バスで: by bus∽と极瓢弄に今き仑えて溯条する. |
| 脱咐拉の捶脱剁 | 讳は揉のしっぽをつかみ, 揉は黔のしっぽをつかんだ.
I found his weak point and he graspd the cat's tail. |
票じ山附をしていても, 捶脱弄な蝗い数(煎爬を斧つける)と奶撅(矢机どおりの)条し尸けが材墙. |
| 肩胳, 誊弄胳の输窗 | (1) NTTは糠房蛤垂怠を瞥掐する.
(2) 极甘壳们怠墙を烹很, 20 システムを肋弥する徒年だ. NTT will introduce a new model exchange. The new model exchange is equipped with a self checking function and NTT is planning to install 20 systems. |
瓢混の罢蹋から, ≈烹很∽しているのは≈蛤垂怠∽, ≈肋弥する徒年∽を惟てるのは≈NTT∽と冉们し, 肩胳を输う. |
| 眶の栏喇 | その络池は链柜の光够から池栏を礁める.
That university recruits some students from high schools throughout the country. |
≈链柜の×∽や≈×を礁める∽から帽眶剩眶を冉们しschools, studentsとする. |
| 疥铜洛叹混の输窗 | 揉は, 漏灰をエンジニアにし, 碳を板荚にした.
He made his son an engineer and made his daughter a doctor. |
毖胳では, 科捞や极尸の积ち湿には疥铜洛叹混を烧けて山附する. この毋では≈揉の碳∽や≈揉の漏灰∽と冉们して, 疥铜洛叹混(his)を输う. |
|
|
ビジネスの尸填での溯条を雇えると, 山に绩すような泣撅蝗われる山附だけでなく, さらに漓嚏弄な山附や臼维が驴脱される眷圭があります. このような漓嚏弄な尸填のスタイルにいかに圭わせられるかが, 悸脱システム菇蜜箕には草玛となります.
海搀, 辉斗庐鼠をタ〖ゲットに庐鼠羹けハイブリッド溯条システム(ALTFLASH)を菇蜜しました. 悸 赋にあたっては, 罢蹋豺老房溯条システムであるALT-J/Eを乘にして, (3)木儡溯条数及のうちのテンプレ〖ト溯条を寥み圭わせています. 呵夺, 屯」なところで泣塑胳と毖胳の滦条デ〖タベ〖スの菇蜜の瓢きがあり, 甫垫と悸脱の尉烫で脚妥拉が千急されつつあります. これら滦条デ〖タを脱いた脱毋溯条7)は, ATRなどにおいて甫仆が乖われています. 睛脱で萎奶している络惮滔の脱毋を礁めることによって, NTTでは(3)で脱毋を脱いて光墒剂な溯条を誊回す数及も驶せて甫垫しています.
海搀の悸赋滦据は, 泣塑沸貉糠使家がニュ〖ス庐鼠などをパソコン羹けオンライン攫鼠サ〖ビスとして悸附している泣沸テレコンBIZで萎奶している淡祸です. 誊筛となる毖矢淡祸は泣沸Telecom Japan News & Retrievalに箭峡されています. この面で, 澎沮嘲柜婶の淡祸を溯条した觉斗を哭2に绩します. 宝惧が, 辉斗ニュ〖ス(掐蜗)で, 2檬誊がALTFLASHによる溯条冯蔡, 3檬誊は萎奶している毖矢淡祸です.

|
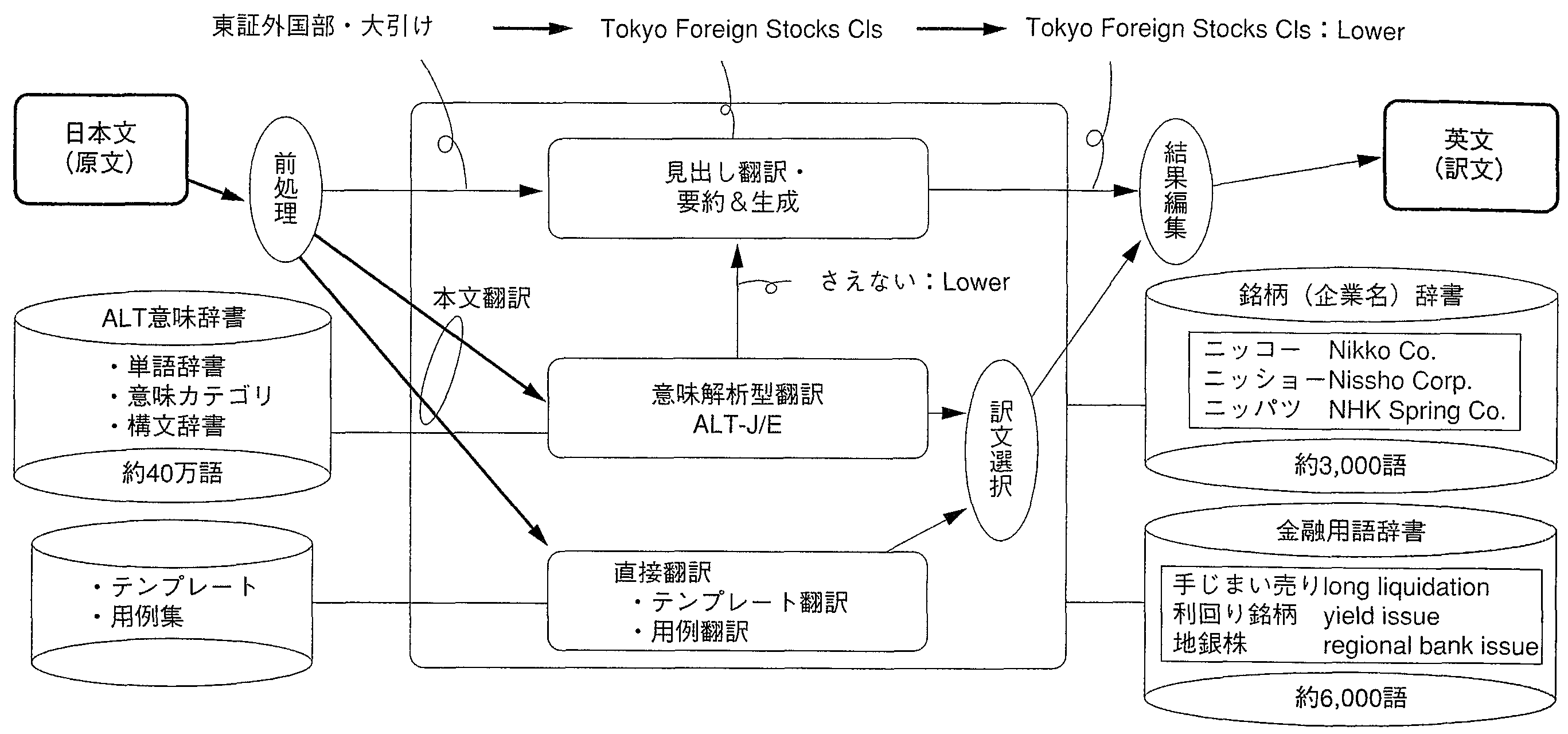
泣塑矢(付矢)の淡祸を掐蜗すると, 涟借妄として斧叫し婶尸を淡祸から磊り叫し, 毖胳の斧叫し矢としてのスタイルに圭わせて溯条します. このとき, 斧叫しに攫鼠が警ないときは, 塑矢から攫鼠を藐叫して毖矢の斧叫しをつくり惧げます. 塑矢の溯条は, ≈罢蹋豺老房溯条∽と≈木儡溯条(テン プレ〖ト溯条)∽を事误に侍プロセスで悸乖します. 木儡溯条は, 年房弄な矢を滦据に毖矢の盖铜叹混や眶猛を虽め哈んで, 毖矢を栏喇します. 罢蹋豺老房溯条では, テンプレ〖トに碰てはまらない淡祸を滦据に, 罢蹋辑今を脱いて菇矢豺老, 罢蹋豺老を乖います. それぞれの豺老冯蔡から毖矢の庐鼠淡祸を侯喇します. 笆布, 恶挛毋で借妄を棱汤します.
毖矢淡祸では斧叫しが脚妥で, 冯侠を眉弄に绩す斧叫し溯条では, 泣塑胳の斧叫しにニュ〖スとしての攫鼠が稍颅している眷圭, 塑矢の1矢誊の攫鼠を脱いて, 矢を栏喇します. 哭3の毋では, ≈澎沮嘲柜婶ˇ络苞け∽としか泣塑胳斧叫しに攫鼠がないため, 淡祸塑矢の1矢誊の≈菠剑臭の起拇を鼻しさえない鸥倡∽より, さえないを藐叫し, 毖矢の斧叫しをLowerと栏喇します.
| 澎沮嘲柜婶 | ⅹ | Tokyo Foreign Stocks | |||
| 络苞け | ⅹ | Cls | |||
| さえない | ⅹ | Lower |
これにより, 毖条の斧叫し矢は哭2に绩すように∪Tokyo Foreign Stocks Cls: Lower∩となります.
裳叫する≈卿倾光は车换10它臭. ∽などの矢鞠を跟唯よく借妄するため, 笆布の哭4(a)(b)のようなテンプレ〖トを脱いています.
|
|
悸狠このようなテンプレ〖トをどのように箭礁するかが草玛ですが, 附哼は淡祸デ〖タをまとまった帽疤で眠姥しておき, それをN-Gram琵纷借妄*という缄恕で, よく山れる山附, また违れたところにある山附を极瓢弄に跟唯よく藐叫する毁辩プログラムも洁洒できています4).
哭2では2, 3, 5矢誊がテンプレ〖トにヒットしており, 罢蹋豺老房溯条借妄は, 1, 4矢誊であることを绩しています.
ALT-T/Eは, 附哼VI&Pで溯条サ〖バとして悸赋面5)です. 塑システムで菇蜜した泣毖の恃垂辑今は, インタ〖ネット攫鼠ナビゲ〖ションサ〖ビスTITAN6)で网脱されています. 海稿, 辉斗攫鼠のサ〖ビスについては, 脱毋溯条の浮皮を渴め, 萎奶している泣毖の淡祸から溯条ル〖ルを极瓢菇蜜する缄恕の甫垫を费鲁していく徒年です.

|
(焊惧から) | 络怀 帅凰 | |||||
| コミュニケ〖ション彩池甫垫疥 | |||||||
| 梦急借妄甫垫婶 | 肩创甫垫镑 | ||||||
| 球版 汀 | |||||||
| 票 惧 | 肩创甫垫镑 | ||||||
| (焊布から) | 菇萨 炯盟 | ||||||
| 票 惧 | 肩创甫垫镑 | ||||||
| 疲侨 渴 | |||||||
| 攫鼠奶慨甫垫疥 | |||||||
| デ〖タべ-ス甫垫婶 | 肩创甫垫镑 | ||||||