A Hybrid Rule and Example-based Method for Machine Translation
Satoshi SHIRAI, Francis BOND and Yamato TAKAHASHI
NTT Communication Science Laboratories
1-1 Hikari-no-oka, Yokosuka-shi, Kanagawa-ken, JAPAN 239
{shirai,bond,yamato}@cslab.kecl.ntt.co.jp
Abstract
This paper introduces a new example-based method of machine
translation in which the examples need not be direct translations. The
system will weed out strange examples during translation, allowing the
use of currently available sentence aligned corpora as
data. Rule-based modules are used where appropriate. A prototype
Japanese-to-English system has been implemented that allows multiple
users to share corpora.
[ In Proceedings of NLPRS'97, pp.49-54 (December, 1997). ]
INDEX
1 Introduction
Methods for machine translation can be generally classified as
rule-based or example-based, and each has numerous problems which
remain unsolved. Especially in Japanese-to-English translation, due to
the difference in language categories, current methods are far from
being at the stage where they can be of practical use (Narita,
1996). This paper will attempt to make use of the strengths of both
the rule and example-based methods to suggest a form of machine
translation that can be used with existing technology.
We will first discuss the strengths and weaknesses of various
translation methods.
1.1 Rule-Based Translation
Most of the machine translation software on the market today is
rule-based. These systems consist of (1) a process of analyzing input
sentences (morphological, syntactic and/or semantic analyses) and (2)
a process of generating sentences as a result of a series of
structural conversions based on an internal structure or some
interlingua. The steps of each process are controlled by the
dictionary and the rules.
As the accuracy of translation by the system is the product of the
accuracies of each process, it is necessary to enlarge the magnitude
and to upgrade the precision of existing dictionaries and rules for
each step (Ikehara et al., 1993), and this is extremely labor
intensive.
Further, in-depth analyses enable the use of long-distance
relationships and related information yet they tend to lose the
collocational relations between words. In addition, most text produced
by rule-based methods is incohesive. This is for two reasons, (1) the
rules needed to increase cohesion are not yet fnily understood and (2)
those that are understood often rely on a full semantic and pragmatic
analysis ofthe text, whith is rarely available.
1.2 Example-based Translation
To overcome the problems of dictionaries and rules in the rule-based
translation method, a method of translation by the principle of
analogy has been proposed (Nagao, 1984). This is done by collecting
aligned translated example sentences and translating the input
sentence by imitating the translation of a sentence that resembles
it. This has its merits in that, as long as there is a translated
example, a well structured translation will be generated. There is no
need to prepare dictionaries and rules through individual analysis of
linguistic phenomena. Improvement in the translation capability could
be expected by mereIy adding examples of translations. This has
resuited in a large amount of researth in this field.
This analogy method, however, frequently assumes the existence of an
aligned corpus with examples that align on a strict 1-to-1 basis as
well as on appropriate tag information showing the correspondence
between words and phrases (Sadler, 1989, 117). Yet, cases of direct
translation equivalents are limited in number and assessments of
similarity using a thesaurus are rarely reliable. Example-based
translation that relies on a corpus with very similar text is really
just a variation on translation memory, very useful for tasks such as
upgrading manuals, where much of the text is reused, but not generally
useful. And even if it were possible to secure a large voluIne of
corresponding example sentences, the task of tagging them in a uniform
and accurate manner is difficult. For example, Kaji et al. (1992) make
a set of templates with variable expressions from their corpus, before
using it. These templates are only be as accurate as the parsers used
to prepare them, and must be remade every time the parsers change.
Cranias et al. (1995) propose a matching method based on differences
between function and content words. It relies crucially however, on
segmenting sentences into coherent segments and alignment at the
sub-sentential level, both processes that are hard to automate.
1.3 Combined Translatian Methods
Multi-engine systems use both the rule and example-based methods and
then choose one of the translations. These systems take over all of
the strengths and weaknesses of each method and add the fresh problem
of how to decide which output to use.
Brown (1996) is an example of an example-based system run in parallel
with a rule-based (knowledge-based) system as part of the Pangloss
system. It only translates sequences of connected words, and so fails
to give one of the expected benefits of an example-based system, the
production of sentences with coherent structure. Its main strength
seems to be in the fact that it is easy to adapt to new languages.
2 A Hybrid Translation Method
The following hybrid design in an effort to produce a method that
makes the most of the strengths of both methods and that will
compensate for their weaknesses. The strungths of the rule-based
method lie in the fact that information can be obtained through
introspection and analysis, while those of the example-based method
are that correspondences can be found from raw data. The weakness of
the rule-based method in that the accuracy of the entire process in
the product of the accuracies of each sub-stage. The weakness of the
example-based method in the difficulty of finding appropriate
examples.
The basic outline of the algorithm in as follows:
- Select a set of candidate sentences which are similar to the input
sentence (section 2.2)
- Select the most typical translation out of those corresponding to
the candidates (section 2.3)
- Use this translation and its source as templates to translate the
input sentence (section 2.4)
The major innovation of this algorithm is in step two. Instead of
simply choosing the source-target pair whose source sentence best
matches the input sentence, a pair in chosen which both matches the
input sentence and has a translation similar to other examples. By
discarding candidates with atypical translations, the algorithm
filters out free, incorrect or context dependent translations. This
means that the input corpus does not have to cormist of good,
context-independent sentence pairs to be useful. The only requirement
is that there be enough translations to be able to find a typical
translation.
A variety of methods can be used to determine similarity in step one,
to select the most typical translation in step two, and to finally
translate the sentence in step three. The methods currently being used
in our system are described in the following subsections, after a
brief. discussion of the construction of the corpus.
As all processing is done during the translation process, improvements
in any of the modules will not require the entire corpus to be
re-parsed.
A more detailed outline is given in Figure 1.
| For each input sentence: SI |
|
|
| |
1. | |
Find candidate sentences {Si:
Si is similar to SI} (section 2.2) |
|
|
| If there are none, translate using rule-based system to give
TI, goto step 4. |
|
|
| 2. |
Select the template. St (section 2.3) |
|
|
| (a) | |
Rank the candidates, Si, by similarity to the input
sentence |
| (b) |
Cluster the translations, Ti, of the candidate
sentences |
| (c) |
Select the highest ranked pair of the best cluster
(St, Tt) |
|
|
| 3. |
Translate SI by analogy to St
(section 2.4) |
|
|
| For each difference di between input
SI and selection St |
|
|
| (a) | |
Find the corresponding section ti of the selected translation
Tt |
| (b) |
Replace ti with the translation of di,
translated using the rule-based modules |
|
|
| Adjust for number agreement and so forth |
|
|
| 4. |
Output the adjusted sentence TI |
|
Figure 1: An outline of the hybrid algorithm
2.1 Greating and Indexing a Corpus
A practical example-based system requires a large volume of suitable
data. In the case of our hybrid algorithm, for the corpus th be
suitable it need only consist of sentences that are loosely aligned,
not necessarily exact translations.
A large volun1e of newspaper data is currently available, for example,
the Nihon Keizai Shinbun,1 much of it on CD-ROM. There is much more
Japanese data than English. Considering stock-market reports alone, we
estimate that there are 1,000,000 Japanese sentences (35 characters on
average) and 150,000 English sentences (13 words on average) each
year. The Japanese and English articles are not direct translations of
each other, but for around half of the English sentences there are
Japanese sentences that are close to being literal translations
(Shirai et al., 1995). The aligned sentence pairs are, to some extent,
translation equivalents. IdealIy they are sentences with equivalent
meanings in the two languages, in reality many of them only contain
sub-sections with equivalent meanings. Note that it is not important
which was originally the source and which the translation.
As our algorithm weeds out unsuitable sentences during translation, we
focus on recall rather than precision when aligning our sentenccs,
which can thus be done entirely automatically. First we align the
newspaper articles, using, numerical expressions and proper nouns as
anchors following the method outlined in Takahashi et al. (1997).
Then we align sentences within the aligned articles. We accept as
aligned sentences, ones that contain even a small amount of equivalent
text, so sentence level alignment can also be done
automatically. Currently we adopt a method that uses both statistical
and dictionary information (Haruno and Yamazaki, 1996), but any method
could be used.
We have tagged the data with SGML tags, using the TEI P3 document type
definition (Sperberg-McQueen and Burnard, 1994). We do not tag any
elements smaller than sentences as our aigorithm does not require a
corpus tagged with details of the internal structure.
Each article and each sentence in the article has a unique ID. The
Japanese and English data are stored in separate files. A separate
file contains links showing the correspondences between the two
languages. The format is similar to that used in the Lingua Project
(Bonhomme and Romary, 1995). As the links are in a separate file, they
can easily be replaced as better alignment algorithms appear and are
used.
In addition, an index of all n-grams (n 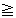 2) that appear more than
once in the Japanese data has been prepared. It is used for finding
similar sentences. The n-grams are found using the method outlined in
(Ikehara et al., 1996), which eliminates any n-grams that appear only
as substrings of larger n-grams. For a language such as English, which
in separated into words by default, a word index (preferably
lemmatized), could also be used. We used a variety of trie index, for
fast and efficient searching (Aoe et al., 1992).
2) that appear more than
once in the Japanese data has been prepared. It is used for finding
similar sentences. The n-grams are found using the method outlined in
(Ikehara et al., 1996), which eliminates any n-grams that appear only
as substrings of larger n-grams. For a language such as English, which
in separated into words by default, a word index (preferably
lemmatized), could also be used. We used a variety of trie index, for
fast and efficient searching (Aoe et al., 1992).
We end up with the following data:
- Source Sentences Si
- Target Sentences Tj
- links li-j (not all sentences have links)
- trie index (of all n-grams that appeared more than once in the source sentences)
2.2 Finding Candidate Sentence Pairs
The input sentence SI is searched for any n-grams that appear in the
index (that is n-grams that appeared more than once in the Japanese
corpus). All sentences in the corpus that contain one or more of the
n-grams, and have English equivalents, are selected as candidate
sentences.
For example, consider the following input sentence, which contains
the following indexed n-grams:2 nikkei, heikin,
gatsu-mono-wa-zokuraku, wa-zokuraku.
| SI | |
nikkei | |
heikin | |
10 | |
gatsu | |
mono | |
wa | |
zokuraku | |
. |
|
Nikkei | average | 10 |
month | thing | TOP |
continue-decline | . |
|
The Nikkei Average October contracts continued declining |
For the sake of our explaining the method, we will assume it only
matched the following three sentences (matching n-grams marked bold):
| (1) | |
nikkei | |
heikin | |
9 | |
gatsu | |
mono | |
wa | |
zokuraku | |
. |
|
Nikkei | average | 9 |
month | thing | TOP |
continue-decline | . |
|
The Nikkei Average September contracts were lower. |
|
|
| (2) | |
nikkei | |
tentoo | |
heikin | |
wa | |
zokuraku | |
. |
|
Nikkei | over-the-counter | average |
TOP | continue-decline | . |
|
The Nikkei over-the-counter average continued declining |
|
|
| (3) | |
8 | |
gatsu | |
mono | |
wa | |
zokuraku | |
. |
|
8 | month | thing | TOP |
continue-decline | . |
|
August contracts continued declining. |
However, if there are no candidate sentences, the hybrid design method
in unable to function and the sentence in translated using a
ruIe-based translation system.
2.3 Selecting the template
2.3.1 Ranking the Candidate Sentences
The input sentences and all the candidates are segmented using a
morphological analyzer (the same as used by the rule-based
Japanese-to-English machine transIation system ALT-J/E (Ikehara et
al., 1991)).
The sentences are ranked using the similarity metric given below.
The result is an ordered set of candidate sentences and their
translation equivalents S1, ... Sn, the higher ranked a sentence is,
the more similar it is to the input sentence.
At this stage it would be possible to discard some lower ranked
sentences, in order to increase speed, either by discarding any with
similarities below a certain threshold,3 or all those beyond a certain
numbar. However, at present, speed has not been a problem, so we do
not do this.
Definition of 'similarity'
The similarity metric is calculated with two components, one based on
the order of shared segments (Mo), and one based only on their
cooccurrence (Mc).
The two components are calculated as follows. First all segments of
SI are given a value from left to right, starting with 0, and
increasing by one for each segment. Then all segments in Si that also
occur in SI are given the same values, but differing segments are
given a very high value (such as 99).
Mo and Mc are defined as follows (bubble sort values given when
compared to SI ):
| |
Mo (SI ,Si ) = |
no. of swaps to bubble sort Si |
| (1) |
| -------------------------------------------- |
| no. of swaps to reserse Si |
|
| Mc (SI , Si ) = |
number of shared segments | |
| (2) |
| ------------------------------------------ | |
| number of segments in Si | |
The combined similarity metric M = (1 - Mo )Mc . Mo penalizes changes in
order, while Mc penalizes non-matching segments. We take the final
similarity as the average of M(SI , Si ) and M(Si , SI ). No explicit
semantic anaiysis is undertaken.
For example the above sentences are ranked as follows:
| SI | | nikkei | heikin | 10 | gatsu | mono | wa | zokuraku | . |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|
|
| S1 | | nikkei | heikin | 9 | gatsu | mono | wa | zokuraku | . |
| | 0 | 1 | 99 | 3 | 4 | 5 | 6 | 7 |
|
| | (M(SI ,Si ) 5 swaps, 7 shared segments) |
|
|
| S2 | | 8 | gatsu | mono | wa | zokuraku | . |
| | 99 | 3 | 4 | 5 | 6 | 7 |
|
| | (M(SI ,Si ) 5 swaps, 5 shared segments) |
|
|
| S3 | | nikkei-tentoo-heikin | wa | zokuraku | . |
| | 99 | 5 | 6 | 7 |
|
| | (M(SI ,Si ) 3 swaps, 3 shared segments) |
Note that nikkei-tentoo-heikin "the Nikkei over-the-counter average"
appears as a single word in the user dictionary, and thus is analyzed
as a single constituent. Therefore it does not match nikkei "Nikkei"
or heikin "average", although it matched them using the initial n-gram
index.
This method considers not only the number of matching characters and
the number of continuous matching characters, as in Sato (1992), but
also the number of non-matching characters found in the candidates.
Because our morphological analyzer also gives POS and sense, as well
as chunking the strings into phrases we are currently investigating
ways of using this additional information, for exan1ple by comparing
the number and order of case-marked noun phrases and comparing
senses. However, our method in designed to work with a large corpus,
so a simple fast algorithm is to be preferred.
2.3.2 Finding the best cluster
The next step is to cluster the translation equivalents {Ti } of the
candidate sentences {Si } into groups of similar sentences. This in
done in order to find translations that are reasonably direct. As all
the candidate sentences are similar to the input sentence, we expect
that direct translations will also be similar.
We cluster the translations as follows:
- Determine the frequency of all words in the set of translation
equivalents {Ti }, ignoring any words that are in a set of stop words
(mainly function words such as articles, auxiliary verbs and
prepositions).
- If there is one most common word, then the best cluster in the set
of sentences that include it. Otherwise, the best cluster is the set
of those with the maximum number of the most common words.
For example (frequencies given as subscripts, stop words have no
subscripts):
| T1 | |
The Nikkei2 Average1 September1
Contracts2 were lower1 |
| T2 |
August1 contracts2 continued2
declining2 |
| T3 |
The Nikkei2 over-the-counter1 average1
continued2 declining2 |
In this case the best cluster has two members T2 and T3.
2.3.3 Selecting the sentence with the most typical translation
The sentence pair to be used in the actual translation is the sentence
pair (candidate sentence + translation equivalent) in the best cluster
that has the nighest similarity to the input sentence (in our example
(S2 ,T2 )). We call the two sentences the source template (St) and the
target template (Tt). This sentence pair ideally4 has the following
properties: (1) the source template resembles the input sentence, (2)
the translation template is a reasonably direct transIation of the
source template. This makes the sentence pair a suitable template for
example-based translation by analogy.
2.4 Translating the input, using the template as guide
The differing sections of the input sentence and the source template
are identified. Translations of these different sections in the input
sentence are produced by rule-based methods and these translated
sections are fitted into the translation sentence in the template. The
resulting sentence is then smoothed over, by checking for agreement
and inflection mismatches.
The resulting translation has the overall structure provided by the
example-based template, with only individuai words or phrases,
translated by the rule-based system. In general, rule-based systems
give better results for small segments, so this gives the best of both
worlds.
The input sentence and selected template are:
| SI |
|
nikkei heikin 10 gatsu mono wa zokuraku . |
| St |
8 gatsu mono wa zokuraku . |
| Tt |
August contracts continued declining. |
2.4.1 Finding the differences
In order to find any differences, both the input sentence and source
template are parsed, and their parses are compared. Because the
sentences are similar, even if there are errors in the parse, they are
often the same errors for both sentences and have little effect on
finding the differences, so the algorithm will work with imperfect
parsers. Tins is the only part of the process that requires parsing,
and it is tolerant of errors, so there is no need for structural
tagging in the corpus.
In this case the difference is between nikkei heikin 10 and 8 . The
parsing process however shows that nikkei heikin 10 gatsu mono in all
one noun phrase, and so matches it with 8 gatsu mono "August
contracts"
2.4.2 Replacing the differences
The rule-based translation of the source template is compared with the
target template. Those parts of the template that correspond to the
differing sections are replaced by their translations.
nikkei heikin 10 gatsu mono is translated as "The Nikkei Average
October contracts", by the rule-based noun phrase translation system,
which gives good results for small segments. This is slotted into Tt
giving the foliowing:
| TI | |
The Nikkei Average October contracts continued declining. |
2.4.3 Smoothing the output
A very rough surface analysis of the output sentence is used to check
for person and number agreement.
At present we have no methanism for identifying and deleting
extraneous elements in the example-based translation, such as temporal
adverbs. This in one of the major sources of errors in our system. We
are currently adding a filter to identify and delete such terms.
2.5 System Architecture
The features of the system as it is implemented are listed below:
- The system operates as a multiuser client/server network.
The server runs on UNIX and the clients on Windows-NT.
- Users can combine their own aligned corpora with the system's,
and share them amongst themselves.
- The rule-based components and dictionaries are taken from ALT-J/E .
The prototype was tested translating from Japanese to English, with a
corpus of 5,000 sentences5. We are now in the process of testing it
with a year's data.
3 Conclusion
The merits of using examples are that, translations of expressions
winch are idiomatic, literal or domain dependent can all be put to
use; and the system should be reversible, that is it can translate in
either direction. Previously, many example-based systems assumed the
existence of large word or phrase aligned corpora. To date, we know of
no large scale corpora accurately aligned below the sentence
level. For an example-based system to be useful in the foreseeable
future, it has to be able to accept loosely aligned corpora, not
aligned at low levels. We have suggested a design for a system that
can use such loosely aligned texts. We have implemented a prototype of
such a system, that works using corpora of the level currently
available, to translate from Japanese to English. The prototype allows
users to take advantage of any aligned text they may already have by
adding it to the set of sentences searched by the system.
In the future, we plan to improve the individual modules in the
system, in particular the similarity measure and output smoother.
Acknowledgments
We would like to thank Satoru Ikehara, Toshiaki Tanabe, Masatoshi
Tachibana, Hiroko Inoue, Makiko Nishigaki, Hiromi Ueda and Tim Baldwin
for their help and advice.
References
- J. Aoe, K. Morimoto, and T. Sato. 1992.
- An efficient implementation of trie structures.
Software Practice & Experiments , 22(9):695-721.
- Patrice Bonhomme and Laurent Romary. 1995.
- The lingua parallel concordancing project.
Managing multilingual texts for educationai purpose.
In Language Engineering '95 , June.
- Ralf D. Brown. 1996.
- Example-based machine translation in the pangloss system.
In 16th International Conference on Computational Linguistics: COLING-96 ,
pages 125-130, August.
- Lambros Cranias, Harris Papageorgiou, and Stelios Piperidis. 1995.
- A matching technique in example-based machine translation. (cmp-lg/9508005).
- Masahiko Haruno and Takefumi Yamazaki. 1996.
- High-performance bilingual text alignment using statistical
and dictionary information.
In 34th Annual Conference of the Association for Computational Linguistics ,
pages 131-138.
- Satoru Ikehara, Satoshi Shirai, Akio Yokoo, and Hiromi Nakaiwa. 1991.
- Toward an MT system without pre-editing - effects of new methods in ALT-J/E-.
In Third Machine Translation summit: MT Summit III ,
pages 101-106, Washington DC. (cmp-lg/9510008).
- Satoru Ikehara, Masahiro Miyazaki, and Akio Yokoo. 1993.
- Classification of language knowledge for meaning analysis in machine translation.
Transactions of the Information Processing Society of Japan ,
34(8):1692-1704, 8. (in Japanese).
- Satoru Ikehara, Satoshi Shirai, and Hajime Uchino. 1996.
- A statistical method for extracting uninterrrupted and interrupted collocations
from very large corpora.
In 16th International Conference on Computational Linguistics: COLING-96 ,
pages 574-579, August.
- H. Kaji, Y. Kida, and Y. Morimoto. 1992.
- Learning translation templates from bilingual text.
In 14th International Conference on Computational Linguistics: COLlNG-92 ,
pages 672-678, August.
- Makoto Nagao. 1984.
- A framework of mechanical translation between Japanese and English
by analogy principle.
In Elithorn and Banerji, editors, Artificial and Human Intelligence ,
pages 179-180. Elsevier.
- Narita. 1996.
- Language type and machine translation.
IPSJ SIG Netes 96-NL-114-21 , 96(65):143-50. (in Japanese).
- Victor Sadler. 1989.
- Working with Analogical Semantics: Disambiguation techniques in DLT .
FORIS Publications.
- Satoshi Sato. 1992.
- CTM. An example based translation aid system.
In 14th International Confrrence on Computational Linguistics: COLING-92 ,
pages 1259-1263, August.
- Satoshi Shirai, Mitsue Matsuo, Takako Seshimo, Susumu Fujinami, and Satoru Ikehara. 1995.
- Constructing an aligned Japanese/English corpus of newspaper articles (3)
- peculiarities or the articles and sentence alignment -.
In Record of the 1995 Joint Conference of Electrical and Electronics Engineers
in Kyushu , page 857. (in Japanese).
- C. M. Sperberg-McQueen and Lou Burnard, editors. 1994.
- Guidelines for Electronic Text Encoding and Interchange . Chicago, Oxford, April.
- Yamato Takahashi, Satoshi Shirai, and Francis Bond. 1997.
- A method of automatically aligning Japanese and English newspaper articles.
In Natural Language Processing Pacific Rim Symposium '97: NLPRS-97 . (this volume).
Footnote
1
A Japanese financial newspaper. (Return)
2
To make an example with few enough matches to show,
we have created examples assuming an unreasonably small
corpus, in reality there would be more indexed n-grams.
All input sentences are actually stored using Japanese characters, although we show only their transliterations in this
paper. (Return)
3
If there were no candidates above this threshold, the
sentence would be translated by the ruIe-based system (Return)
4If
the corpus was large enough to produce a choice of candidates. (Return)
5
The data was being collected as the system was being built. (Return)