シソーラス(thesaurus)は、元来、ことばや知識の宝庫を意味することばであるが、 一八五一年に、イギリスのロジェ(Samuel. R. Roge)が単語の意味分類辞書を作成し、 これをシソーラスと呼んで以来、 語や句を意味によって分類し、配列した辞書をシソーラスと呼ぶようになった。 日本語では、分類語彙表、類語辞典などと呼ばれている。
日本語のシソーラス(荻野・一九八七)としては、 単語の同義語や類義語を分類整理し、階層的な木構造にまとめたものとして、 『分類語彙表』(国語研究所・一九六四)や 『角川類語新辞典』(大野、浜西・一九八一)がある。 計算機による情報処理の分野でも、シソーラスは大変重要で、 新聞記事検索などの情報検索の分野では、さまざまなシソーラスが作成され、 検索用のキーワードを調べるのに用いられている。 また、最近では、言語の意味解析での重要性が認識され、 概念辞書(EDR 1990)が作成されたほか、 オントロジ(Ontology)と称し、言葉のより詳細な情報を収録した辞書作成の提案が行われている。
これらの動きに加えて、この九月、 岩波書店より『日本語語彙大系』(池原他・一九九七)と称する 大規模な日本語のシソーラスが出版された。 この辞書は、NTTが日英機械翻訳システムを実現するため、 過去一〇年以上にわたって作成してきた計算機用の意味辞書 (池原他・一九九三)を 人間用に編集したもので、規模が大きいだけでなく、 その内容は、世界的に見ても従来のシソーラスにない多くの特徴を持っている。 また、この辞書は、レキシコグラフィ(lexicography)の観点からも、 人間が使いやすいようなさまざまな工夫が行われており、今後、多方面での応用が期待される。 そこで、本稿では、『日本語語彙大系』がどのような辞書であり、 どのような使い方ができるかについて紹介する。
『日本語語彙大系』の特徴として、まず第一に挙げられるのは、 この辞書は、従来の類似の辞書と異なり、単語を語義によって分類するのでけなく、 意味的な用法によって分類している点である。
計算機処理では、単語が複数の語義を持つこと、 また語義によって用法も異なることが最大の問題である。 この問題を解決するため、この辞書は、実際の日本語表現で使用された単語の多義を その単語の意味的な用法を調べることにより解決することをねらって作成されている。
従来、単語の意味を扱う方法として、「意味素」「意味素性」「意味標識」などの考えがあるが、 これらは語義を構成要素によって規定することをねらったものであり、 そのまま現実の言語表現に適用することは適当でない。
実際の言語表現では、同じ対象を表すにも、見方、とらえ方によって異なった単語が使用される。 例えば、妻が夫を表現するとき、夫婦の関係で見れば「夫」となり、家の関係で見れば「主人」、 恋人の関係で見れば「彼」、一人の人間と見れば「山田太郎」などとなる。 逆に、同じ単語が使われたとしても、その表す意味はさまざまである。 例えば、「学校」は「教育を受けるところ」という基本語義を持つが、 現実の表現では、「学校」の持つ「場所」としての側面や、 「施設」や「組織」としての側面が取り上げられたりする。
このように話者が単語によって取り上げた対象概念の持つさまざまな側面は、 言い換えれば、使用された単語の「意味的用法」と言うことができる。
本辞書では、 単語の持つこのような「意味的用法」を「単語意味属性」として整理し体系化している。 したがって、単語がその語義を超えてさまざまな用法を持つことを考えれば、 単語は通常の辞書で定義された語義の範囲を超えた「単語意味属性」を持つことになる。 また、単語の「意味的用法」は、その単語の語義から派生するから、 文中で実際に使用された単語の「里語意昧属性」が分かれば、 その単語がどの語義で使用されたかを判断することができる。
本辞書の第二の特徴は、「単語意味属性」の分類の基準と精度にある。 従来の「意味標識」などによる単語の意味分類では、分類の基準が明確でないまま、 通常、三〇〜五〇種類の分類が行われていた。 また、この程度の分類では、単語の多義を解消することは困難であることが知られていたが、 どれだけ深く分類すればよいかについては未知のままであった。
一般に、単語の意味分類に必要な分類の精度は、用途によって異なる。 例えば、最近、IPA(IPA 1987)によって 日本語の単語の意味の詳細な分類が行われているが、 日本語と英語の意味的対応関係を決めるためには、さらに詳細な意味分類が必要となる。
『日本語語彙大系』では、この点を考慮して、 日英機械翻訳で用言(動詞、形容詞など)の訳語を決定するのに必要な範囲での 単語の意味分類が行われている。 日本語と英語の用言の意味的対応関係は大変複雑であるが、 日本語の用言を英語に翻訳するとき、訳語は、 その用言の格要素として使用される名詞の意味の関係から ほぼ決定できる(水谷他・一九八三)。 このことに着目し、本辞書では、名詞の意味属性を約二〇〇〇通り以上に分類すれば、 用言の訳語はほぼ決定できることを 実験的に確かめた(池原他・一九九三)上で、 約三〇〇〇種の意味属性からなる単語意味属性体系を作成している。
このように、本辞書では、日英の単語の意味的対応関係 を決めるのに必要な意味分類の精度を調べ、それに基づ いて、従来にない詳細な意味属性体系を作成している。
第三の特徴は、収録された文型パターン対が非常に精密なことである。 前項で単語の意味的用法の分類の基準け、 日本語動詞と英語表現との意味的対応関係を規定できる精度であることを述べた。 本辞書では、この考えに基づき、実際に、日本語用言の約六〇〇〇語の意味を分析し、 日本語文型とそれに対応する英語文型を約一四〇〇〇件の文型パターン対にまとめている。
このように、文型パターン対は非常に精密で、 日本語の用言の持つ微妙な意味の違いがパターン化され、 対応する英語表現の違いとしてまとめられている点は、従来の辞書にない大きな特徴である。
第四の特徴としては、語彙の網羅性と収録情報の信頼性が挙げられる。 計算機では、辞書に登録されていない単語の意味や用法を文脈から把握することは 大変困難であるので、語彙の網羅性が大変重要である。 また、収録情報の簡単な誤りも、計算機では重大な誤りとなることがある。 このような点から、この辞書では、国語辞典にあるような一般語のほかに、 人名、地名、組織名などの固有名詞も数多く収録されているほか、 日英機械翻訳システムに組み込んだ翻訳実験によって、 収録情報相互の関連性がチェックされている。
収録対象語は、新聞記事などの現代国語の記述文に通常使用される語で、 収録語数は、一般語約一〇万語、固有名詞など二〇万語の合計三〇万語である。 翻訳用の機械辞書に収録されていた一部の専門用語、訳しことば、 古語および機械処理で必要な語は、『日本語語彙大系』には収録されていない。 また、翻訳実験では、各種の試験文の翻訳実験を通して、 収録情報の妥当性の確認が行われている。
『日本語語彙大系』は、表1に示すように、全五巻から構成されるが、 その内容は、図1に示すように、日本語単語の「意味的用法」をまとめた「意味体系」と、 単語とその意味的用法の関係をまとめた「単語体系」、 用言を中心とする文型の持つ意味を整理した「構文体系」の三つの部分が基本となっている。
| 第1巻 意味体系 | 概論 | 編集の背景、方針、方法などを記載、 また、各種辞書内容の分析データなどを収録 |
| 意味体系 | 3種(3,000項目)の意味属性体系を図示 | |
| 意味属性別単語表 | 各単語意味属性を持つ単語のリストを収録 | |
| 第2〜4巻 単語体系 | 日本語単語(30万語)の意味的用法を単語意味属性を用いて定義 | |
| 第5巻 構文体系 | 構文体系 | 日本語用言(6,000語)の用法(慣用的用法を含め合計14,000種)を 結合価パターン対の形式で収録 |
| 構文索引 | 日本語の名詞または英語の単語で、その語の使われたパターン対を検索 | |
この構造は、「実体」「関係」「属性」から構成される客体の世界を 「名詞」と「用言」を通して表現する言語表現の枠組みに対応させたものとなっている。
なお、人間用の辞書としての用途を考え、 第一巻に、単語意味属性別に単語を収録した「意味属性別単語表」、 第五巻に、慣用文型に含まれる名詞に着目して、 日本語名詞から慣用文型を検索するための「日本語名詞索引」、 一般文型、慣用文型とペアになっている英語文型を 文型に使われた英語単語から検索するための「英語索引」を掲載しているが、 これらの情報は、いずれも上記三種の基本情報から編集されたものである。 また、第一巻には、「概論」として、この辞書の編集の方針や情報収録の基準、 方法などが詳細に記述されているほか、語数分類などの詳細な統計量がまとめられている。
| |||||||||||||||||||||||||||||||||||||||||||||
前章で述べた『日本語語彙大系』の三つの基本部分に収録された情報の概要を紹介する。
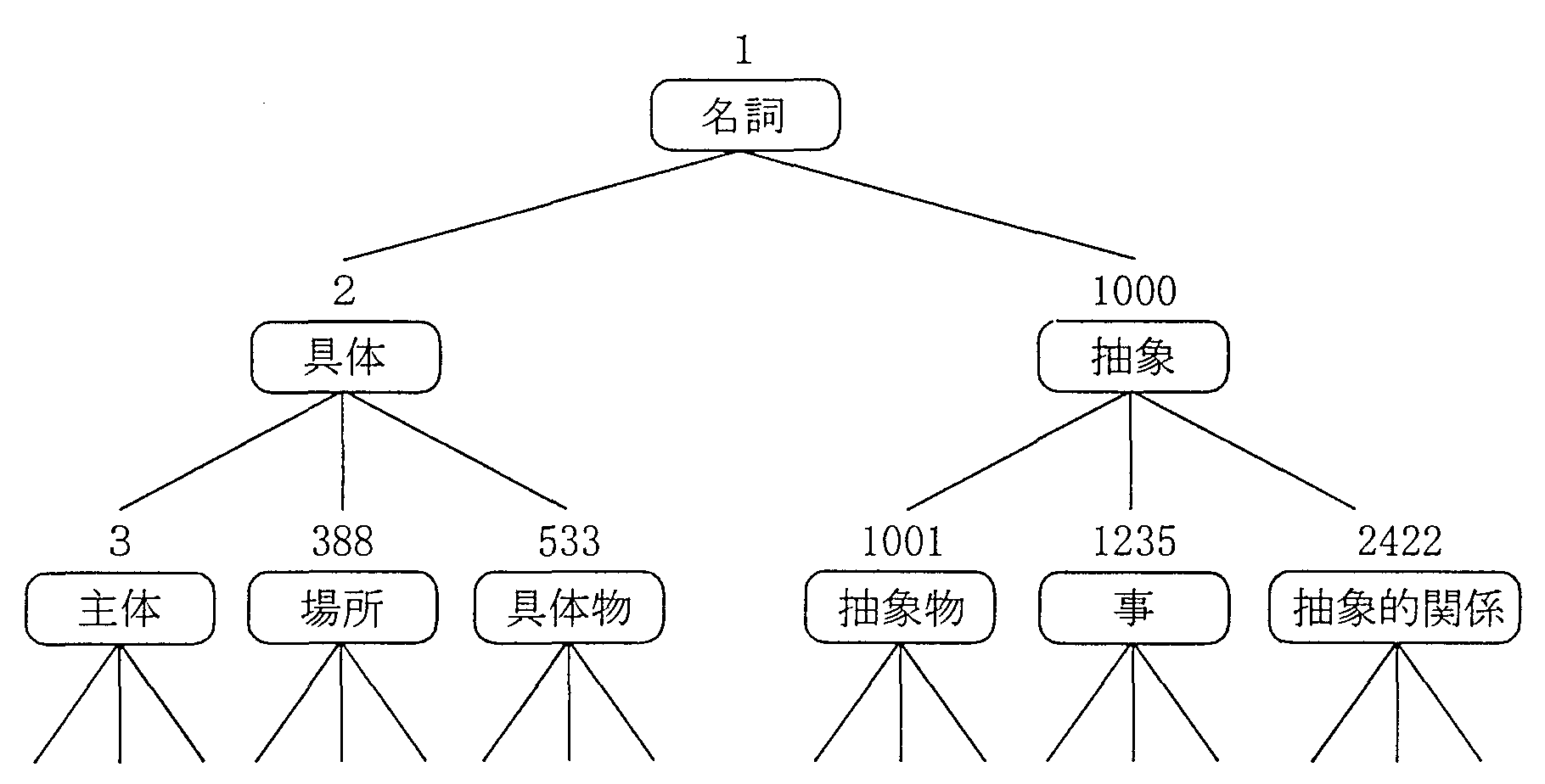
一般名詞、固有名詞、用言の意味的な用法が以下の三種類の「意味属性体系」として 木構造の形式にまとめられている。
| (a) | 「一般名詞意味属性体系」(一二段 約二七〇〇ノード)「is−a関係」(包含関係)、 「has−a関係」(全体−部分の関係)に着目して、 単語の意味的用法を木構造の形式にまとめたもの。 | |
| (b) | 「固有名詞意味属性体系」(九段 約一三〇ノード)「一般名詞意味属性」のうち、 固有名詞に該当する部分をより詳細化したもの。 | |
| (c) | 「用言意味属性体系」(四段 約三〇ノード)用言の持つ本来の意味と それが文中で使われたときの働きに着目して用法を分類したもの。 |
図2に、「一般名詞意味属性体系」の上位三段目までの構 造を示す。各ノードの番号は、意味属性の通し番号である。
|
|
「単語辞書」は、固有名詞を含む日本語単語約三〇万語の意味的な用法を 「単語意味属性」を用いて定義したものである。 通常、一つの単語は複数の意妹を持ち、さまざまな使われ方をすることを考え、 各単語には、考えられるだけの種類の意味属性が付与されている。
一般名詞には「一般名詞意味属性」が対応し、 固有名詞には「一般名詞意味属性」と「固有名詞意味属性」の双方が対応する。 しかし、「固有名詞意味属性」と「一般名詞意味属性」には対応関係があるので、 本辞書では、図3に示すように、固有名詞には「固有名詞意味属性」のみを付与することにより ページ数を圧縮している。 「一般名詞意味属性」を知るには、別に掲載された対応表を検索すればよい。
|
日本語の用言の意味を以下の二種類の文型(結合価パターン)の形に整理したもので、 各文型パターンには、その文型の意味に対応する英語の文型パターンが併せて掲載されている。
「一般表現文型」は、用言の持つ一般的で汎用的な文型をパターン化したもので、 図4に示すように、用言の字面と一つ以上の格要素から規定される。 例えば、図4の動詞「掛ける」の(2)のパターンでは、格要素が三つ使われているが、 これらの格要累の主名詞(N1,N2,N3)は、 引き続き示されるような単語意味属性を持つ語でなければならない。
| |||||||||||||
なお、文型パターン対は、通常、述語となる用言ごとに作成されるが、 名詞が述語になる場合がある。 そのような場合は、名詞を述語とするパターン対が収録されている。 例えば、「名詞+だ(です)」型の日本語の述語名詞は、通常は英語の名詞補語に訳出されるが、 「今日は晴れだ。」のように述語名詞が英語の名詞補語には訳出できない場合は、 "It is fine today."に相当するパターンが収録されている。
「慣用表現文型」は、図5に示すように、一般表現文型と同様な文型パターン対であるが、 一つ以上の格要素が直接名詞の字面で規定される点が一般表現文型と異なる。 例えば、図5の例の(22)のパターンでは名詞「保険」が、 (40)のパターンでは名詞「鎌」の使用が指定されている。
| ||||||||||||||||||||||||||||||||||||
「構文体系」には、約六〇〇〇語の日本語用言に対して、 このような文型パターンが合計一四〇〇〇件(一般パターン一一〇〇〇件、 慣用パターン三〇〇〇)収録されている。 用言当たりのパターン数が多いのは、和語系の用言である。 最もパターン数の多い動詞は 「する」で、 一般文型と慣用文型を合わせて三一九件のパターンが登録されている。 「ある」「なる」の動詞ではそれぞれ三一九件、二〇三件、 前述の動詞「掛ける」では、ちょうど一〇〇件のパターンが登録されている。
『日本語語彙大系』では、日本語の文型(構文体系)とそれに使用される単語(単語体系)は、 「単語意味属性体系」(意味体系)を介して結合されている。 したがって、ある単語が与えられたとき、 その語が「構文体系」で定義された日本語文型の構成要素として使用できるか否かは、 「単語体系」と「意味体系」を併用して決定することができる。
以下では、これらの関係を用いた幾つかの利用の方法を紹介する。
実際の日本語表現で使用された名詞と動詞の意味(意味的用法)を調べることを考える。 まず、与えられた日本文の動詞とそれに支配された格要素の組を取り出す。 動詞を見出し語にして「構文体系」を調べると、一般に複数の文型が得られる。 「意味体系」と「車語体系」を検索して、 文型で定義されている格要素の主名詞の意味属性と 実際に使用された文中の名詞の意味属性の関係を調べ、 前者の配下に後者が属せば、それが実際に使われた文型である。
このようにして、与えられた表現に適用できる文型が求められた時点で、 それに関係した名詞と動詞の意味は決定される。 また、同時に日本文に対応する英語の文型も決定される。
動詞が与えられたとき、適切な名詞と助詞を補って、意味のある例文を作成することを考える。 まず、与えられた動詞を持つ文型は、「構文体系」から一つ以上得られるから、 そのうちのどれかの文型に着目する。
その文型で規定された格要素の意味属性をキーにして「意味体系」を調べ、 その意味属性の配下に存在するどれかの意味属性名を抽出する。 抽出された属性名に対して、「単語意味属性別単語表」を調べ、その属性名に属す単語を選べば、 与えられた動詞に対して日本語として意味のある文例が作成できる。
「意味体系」と「単語体系」の情報を組み合わせて使用すれば、 意味的に用法の似た単語を検索することができる。 この機能は忘れた単語を思い出すなどの発想の支援として役立つと期待される。
例えば、文章を書いているときや情報検索において 検索の範囲を指定するための適切なキーワードが思い浮かばないようなとき、 とりあえず思いついた単語の意味属性を調べ、 得られた意味属性からその意味属性を持つ単語をたどることによって 適切な単語を抽出することが期待できる。
「構文体系」には、従来の和英辞書に例のないような 微妙で詳細な訳し分けの情報がパターン化されて収録されており、 日本語と英語の用言の用法を調べるための学習辞典としての活用が期待される。
例えば、外国人に対する日本語教育では、 日本語動詞の複雑な意味を英語と対比して教えるのに便利である。 また、英語教育や日英、英日の翻訳の現場では、動詞の適切な訳し方を検索することができ、 「英語索引」を使用すれば、英語動詞の適切な日本語への訳し方を調べることができる。
国語学や言語学等の分野においても、従来の単語や表現の形態論的な統計に加えて、 日本語の意味解析の観点からの計量的分析等への応用が期待される。
計算機に言語を教えるのは、人間に外国語を教えるのに似ている。 人間にとっても、知らない言葉は単なる記号でしかなく、 厳密な意味や用法の定義を知らないと、それを使うことは困難である。 『日本語語彙大系』は、計算機に日本語の用法を教えることを目標に開発された辞書であるが、 われわれ人間にもことばのさまざまな用法を教えてくれる。
ことばの意味的な用法を細かく分類整理した辞書は、 従来のシソーラス、国語辞書、和英辞書などと異なった新しいジャンルの辞書とも言える。 今後、本稿では予想のつかなかったような新しい用法が開拓されていくことを期待する。
いけはら・さとる 鳥取大学教授/ みやぎき・まさひろ 新潟大学教授/ しらい・さとし NTTコミュニケーション科学研究所主幹研究員/ よこお・あきお ATR音声翻訳通信研究所第四研究室長