| (序) | |
| 1 翻訳の仕方、人間と機械 | |
| 人間の翻訳(その1) | |
| 機械の翻訳(その1) | |
| 機械翻訳の仕組み | |
| 人間の翻訳(その2) | |
| 機械の翻訳(その2) | |
| 人間の翻訳(その3) | |
| 機械の翻訳(その3) | |
| 2 勉強の仕方、人間と機械 | |
| 人間の勉強 | |
| 機械の勉強 | |
| 3 例文集の利用、人間と機械 | |
| 4 むすび | |
| 参考文献 |
「翻訳家になったらやめるまで毎日が勉強なのに、 機械は『就職』したら毎回文字通り訳すだけで全然勉強しないね。」
これは、以前、ある翻訳家が語ってくれた機械翻訳に対する率直な感想です。 この方は、むしろ機械翻訳に期待し、辛口のコメントを下さいました。
最近では、パソコンを買えば当たり前のように機械翻訳が入っています。 皆さまの中にも使ってみた方は多いと思います。 それで、期待通り使えましたか? 「使える」ようにするには、覚悟を決めて辞書などをしっかり整備する必要があります。 しかし、それでも「使える」ようになるとは限りません。
そこで、今回は、人間と機械の勉強の仕方を比較してみたいと思います。 それに先立って、まず、人間と機械の翻訳の仕方の共通性や違いについて考えてみます。 また、人間と機械の違いを見つめ直すことによって、 先の翻訳家の期待に応える道を探ってみることにします。
あらかじめお断りしておきますが、人間翻訳は筆者の学校英語の経験と翻訳家から聞いた話、 機械翻訳は筆者らの記述文に対する日英翻訳の研究に基づきます。 皆さまの印象と異なる点はご容赦下さい。
では、人間はどのようにして翻訳するのでしょうか。 例えば、次の文の英訳を考えてみてください。 ただし、あなたは英語を習い始めたばかりの中学生です。
(問1)わが家には家具は少ない。
文の意味はわかります。 しかし、「家具」の英語がわかりません。 しょうがないので和英辞典で「家具」を引いてみます。
かぐ 家具 furniture
|
だいたい答えが見えてきましたが、念のため“furniture”で英和辞典も引いてみましょう。
| fur'ni・ture [f'/e:nit/s/e] [名] [U] [単数扱い][集合的に] 家具(日本の「家具」より範囲が広く、時計やストーブ、ドライヤーなども含む。 (中略)We have little furniture. わが家には家具は少ない。 |
おっと、これはラッキー、完全に日本語が一致してしまいました。 従って、間1の答えは“We have little furniture.”です。
皆さまもこんな経験をお持ちではないでしょうか。 しかし、こんなにうまくいくことはめったにありません。 では、次はどうでしょうか。
(問2)あなたの家には家具があまりない。
これも問1の場合と同様に調べます。 今度は和英辞典の例文の方がよさそうです。 「ぼく」と「あなた」が違い、「あなたの」は英語では“your”、 「うち」と「家」は同じですから、 “There is little furniture in your house.”は容易に導き出せるでしょう。 これなら大成功の部類に入ります。
(間3)ぼくのうちには椅子があまりない。
今度は「家具」と「椅子」の違いです。 (首をひねっているあなた、話の都合上、このままもう少し読み進めてください。)
さて、「椅子」はもちろん「家具」の一種です。 それでは「家具」“furniture”を「椅子」“chair”で置き換えて、 答えは...待ってください、 その前に“furniture”には「集合名詞で数えられない」という解説がついています。 そこで、“little”を“few”に変えて、“椅子”を複数に訳して、“is”を“are”に変えて、 “There are few chairs in our house.”とする必 要があります。そうしなければペケになってしまい ますね。
皆さまはこれくらいの問だと瞬間的に答えてしま うと思います。辞書こそ引かないにしても、頭のど こかで覚えている対訳例文を使うことによって、お そらく今でもこれに近い形で翻訳しているのではな いでしょうか。
コンピュータによる翻訳にもこれらと同じ考え方で作られているものがあります。 「イグザンプルベース(example-based)翻訳」、「実例に基づく翻訳」、 「類推(アナロジー)による翻訳」などと呼ばれるものがそれです。 様々なバリエーションがありますが、手持ちの例文集の中から似たような文を探してきて、 その訳し方をお手本にするという点では、基本的に同じ考え方といっても良いでしょう。
問1のような何の加工もしないで取り出すタイプのシステムは 「トランスレーションメモリ」と呼ばれます。 これまでにも解説されていますが、 トランスレーションメモリの使い道について簡単に述べておきます。 このやり方の主な狙いは翻訳業務の効率化と言えるでしょう。 例えば次のケースでは、さきほどの問1のようなラッキーなものが頻繁に見つかります。 ある製品の改良型が出た場合、それに伴ってマニュアルも改訂されます。 ものにもよるでしょうが、マニュアルの改訂といっても100%改訂されることはまれで、 60〜80%は前版と同一の記述であるといわれています。 もし、その製品が輸出されているとなるとマニュアルの翻訳をやり直す必要があるのですが、 同一部分に前回の翻訳を流用することにより、 翻訳の時間とコストの両方が大幅に削減できるというわけです。
また、問3のように、英語の都合をいちいち調べるのは大変ですから、 よく使われる表現に対して穴埋め型の翻訳をする場合もあります。 例えば、問1〜3の文がしょっちゅう使われるとするなら、 「X=|ぼく,わたし|のY=|うち,家|にはZ=|家具|があまりない」→ “There is little Z in X's Y”と 「X=|ぼく,わたし|のY=|うち,家|にはZ=|椅子,机|があまりない」一 “There are few Zs in X's Y”の2種類の雛形を用意しておけば、一気に翻訳できてしまいます。 このような翻訳の仕方はテンプレート翻訳と呼ばれます。
問2や問3を実際にコンピュータに解かせようとすると、いくつか問題が出てきます。 もっとも大きな問題は「何をもって似ていると判定するか」です。
さきほど、問2を解く際に、「ぼく」と「あなた」が違い、 「うち」と「家」は同じ、などとやりました。 「ぼく」と「あなた」は同じ語ではありませんが、代名詞であるという点では共通性があります。 また、問3では「椅子」は「家具」の一種であるという関係に着目しました。
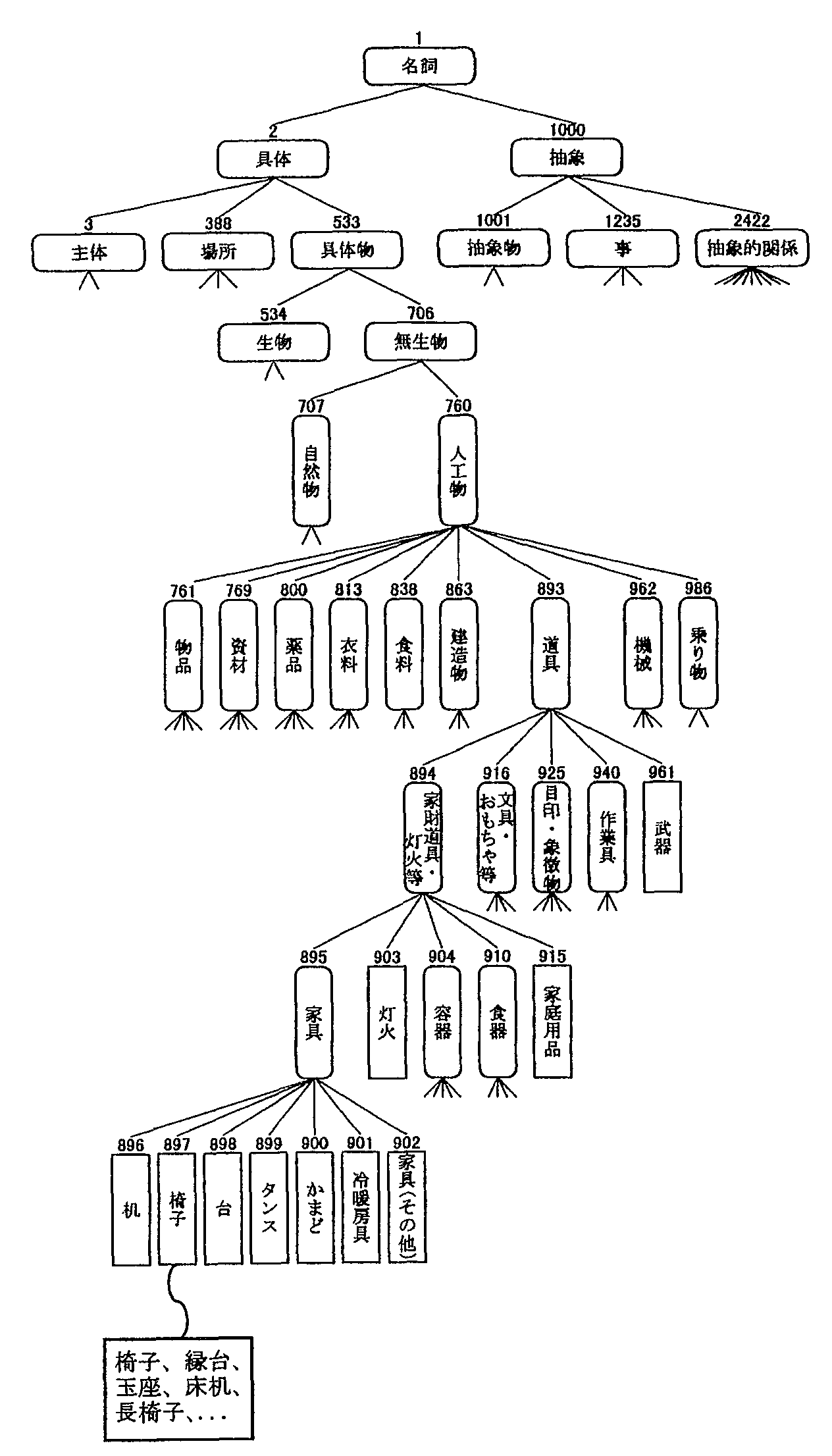
機械翻訳でも同様のことをやりたいのですが、 コンピュータは「ぼく」と「あなた」の共通性などは知りません。 そこで、同義語や共通性のある語をあらかじめ束ねておいたもの、 シソーラスを使って類似判定を行ないます。 シソーラスは、単に単語をグループ化するだけでなく、 共通性の度合いに応じて段階的に大きなグループにまとめられています。 類似性の判定では、このグループの離れ方で類似度を測ります。 例えば、図のようにシソーラスが作られているとします。 「椅子」と「縁台」は距離0、「椅子」グループと「家具」グループは距離1、 「椅子」グループと「机」グループは距雑2などとなります。
|
|
さて、問3のところに話を戻します。 問1や問2では、 問1のところで示した「家具」や“furniture”の項目に載っていた例文を使いました。 首をひねっていたあなた、そうです、 問3は...おそらく「椅子」や“chair”で辞書を引くのです。 すると「家具」の例文を探し出せないかも知れません。 少なくとも英語を習い始めたばかりの中学生では無理でしょう。 従って、さきほどの問3の解説は、前提のところが間違っていたことになります。
では、コンピュータの場合は? しかし、ご安心下さい、コンピュータはこういう探索は大変得意です。 「情報検索」という技術に依存するのですが、 覚えている例文であればたちどころに探し出してくれるでしょう。 その意味で、問1〜3はコンピュータにとっては同じような出題と言えます。
さらに、「椅子」の例文が辞書に入っていなかったらコンピュータは問3をどうするか。 その前に、人間にも別の翻訳の仕方が必要になります。
では、人間は問3をどのような別の方法で翻訳するのでしょうか。
まず、「ぼくの」は“my”、「うち」は“house”、「椅子」は“chair”、 「あまりない」は“not many”または“not much”、「ない」は“there be not”、 または「○○に××がない」は“there be not XX in ○○”という対訳情報を 辞書から書き写します。 そしてこれを順序よく組み立てて、 “There are not many chairs in my house.”を作り出します。
単語や熟語の訳を調べて組み立てる。 機械翻訳ではこのやり方が最も一般的に行なわれています。 「ルールベース(rule-based)翻訳」と呼ばれ、 現在の多くの機械翻訳は解析・変換・生成を順に行なう「トランスファー方式」に基づいています。
否、機械翻訳の歴史はもともとこちらのやり方からスタートしました。 1957年にソ連が人工衛星、スプートニクの打ち上げを成功させたのがきっかけとなって、 アメリカではコンピュータを使って単語置き換えにより ロシア語から英語へ自動的に翻訳しようという挑戦が始められました。 これが実質的な機械翻訳の第1ページと言えるでしょう。
置き換えの単位は単語から句へと改良が進められますが、 当時のコンピュータの力不足や前々回本欄にあるような「人間の気づかない暖味さ」問題のため この試みはいったん挫折します。 そのときの反省から、意味を扱う技術の研究や開発が進められ、 そして今日のような機械翻訳につながっていると言えるでしょう。
トランスファー方式が出た以上、「中間言語方式」にも簡単に触れておきます。 中間言語というと、例えば、ある番組の日本人レポータがどこかの国に行って 現地の人にインタビューするとき、質問=日本語→英語→現地語、回答=現地語→英語→日本語、 のようにしてやり取りをする場面の英語が思い浮かびます。 中央アジアなどでは、英語と現地語の間に、 さらにロシア語が入る二段構えになることもあるようです。 まるで伝言ゲームですね。 この二段構えの方は置いておくことにして. . .
機械翻訳の中間言語は、先のインタビューの英語と同じ役割を果たすわけですが、 決して似ているわけではありません。 中間言語は人間が使う言葉ではありませんので、 人間の気づかない暖昧さの問題は原則として持たないはずです。 また、中間言語なのですから、いったん中間言語に変えておけば、 どの言語に翻訳する場合にも共通に使える、というのがこの方式の利点です。
しかし、先の英語と似てないかというと、似ているところもあります。 いったん別の言語に変えるわけですから、 そのとき伝言ゲームと同じ問題が起きる可能性があります。
「山」“mountain”と「丘」“hill”は一見村応しているようですが、 厳密には対応関係がずれています。 中間言語ではこれらの対応のずれが生じないように設計すること、 その際、日英両言語だけでなく他の言語の都合も考える必要があるわけです。
そんなわけで、厳密に中間言語たるものはまだ存在していないようです。
トランスファー方式や中間言語方式による機械翻訳については、 これまでにも何度か本欄に取り上げられていますので、 これくらいにして話を先に進めることにします。
人間はどんな勉強をして翻訳できるようになっていくのでしょうか。
まず最初にやるのは単語を覚えることです。 もちろん、和英辞書や英和辞書を使えばある程度はカバーできますが、 とても効率は上がりません。 「家具 furniture 名(詞)U(ncountable)」。 筆者も単語帳を作ってバスや電車の中でめくっていた覚えがあります。 「一般的に in a general way」のような熟語も重要です。
単語をたくさん知っているだけでは十分ではなく、その使い方も知らなければなりません。 「ここはどこ?」は“where am I?”だ、 といった慣用的なものは一つずつ覚えていくしかありませんが、 「○○に××がある」“there be ×× in ○○”のようなものであれば ぐっと応用範囲が広がります。 (だから、おまえは英語ができないんだ、というツッコミはさておき、) 学校英語ではこのような単語や熟語を覚えるだけでかなり通用したような気がします。
しかし、それだけではだめで、同じ意味であることを見抜くことが徐々に必要になってきます。 例えば、和英辞典を引いても載っていないときどうするか。 同じような意味の別の言葉で引いてみるということは、皆さまもごく普通にやっているでしょう。 英会話のようにいちいち辞書を引けないときは、さらに一段とこのワザが大事になります。
学校英語では、あるいは実用的には、この路線でやっていけるわけですが、 翻訳家ともなると事情が違ってきます。 なんとか意味が伝わればいい、というのでは翻訳家失格で、 多彩な表現を正しく、しかも単調にならないように翻訳しなければなりません。 しかし、そのようなトレーニングに向く整理された対訳はそれほど多くあるとは思えません。
ここから先は筆者の推測に過ぎませんが、 おそらく日本語の表現のバリエーション、英語の表現のバリエーションが 翻訳家の頭の中には無意識のうちに整理されているのではないでしょうか。 そして、ある表現を代表的な表現に置き換え、その代表的な表現の日英を対応付け、 そして英語の表現のバリエーションに展開する、 そのようにして翻訳しているのではないでしょうか。 もちろん、代表的な表現の日英対応づけされたもの自体を、 一般の人よりはるかに豊富に蓄えているでしょうけれど。

|
コンピュータが勉強する場合も同様です。 単語の対訳、熟語の対訳といったところから覚え始めます。 それには、人間が使っている英和辞書や和英辞書を片っ端から覚えさせればよいでしょう。 コンピュータの強みは何といっても教えられたことを決して忘れないこと、 例えば、めったに使わない技術用語の訳語でも即座に正確に思い出してくれます。 しかし、送り仮名1文字違ってももうわからないという脆さを同時に持ち合わせています。 脆さを防ぐには...現状ではあらゆるバリエーションを丹念に教え込んでやる必要があります。 これを自動化しようとする試みもありますが、 あらかじめ教えられたパターン以外に対応できない点で、 やはり人間のような柔軟さは持ち合わせていません。
次の段階、言い換えになると、さらに状況は絶望的です。 というよりも、その前に人間の気づかない暖味さのため行き詰まってしまいます。 それはなぜか。 ひとことで言ってしまえば、コンピュータは人間のような常識を持たないからです。 それなら、常識を数えればいいではないか。 そこが問題です。 常識を定式化する研究も進められていますが、 当たり前のことを定式化するのはかなり大変な仕事であるということだけ指摘しておきましょう。 1つだけ例を挙げると、「大阪と京都へ行く」と「社長と京都へ行く」における「と」の区別です。 こういったことをあらゆる場合について整理することが必要です。
では、機械翻訳にとっての現実的な勉強方法はあるのでしょうか。 現時点での(そして当分の間の)ほとんど唯一の答えが対訳例文を覚えるということだと、 筆者は考えています。 文をさばこうとするとどうしても人間の気づかない暖昧さの問題に直面します。 対訳例文だと、結論しか示されていないわけですが、どう訳せばよいかはわかるわけです。 その点で、実例に基づく翻訳は常識の問題を避けて通ることができるアプローチであると思います。
常識を定式化するのは大変だと申し上げましたが、 一方で、対訳例文が大量に集まれば統計処理などの手法により 常識的な事項を半自動的に抽出できるのではないかということが期待されます。 この点からも対訳例文を集めることの重要性は高いと思います。 実例による翻訳は、似ていると判定されない限り適用されないわけですから、 方式としては脆いとも言えます。 もちろん、類似判定にも改良の余地はあるでしょうが、 人間のような柔軟さは当分期待できないでしょう。 それに対して、トランスファー方式による翻訳はなんとかして答えを出してくれるわけですから、 タフな方式であると言えるでしょう。 この両者の協調、そして、 機械翻訳の主要な知識源である対訳例文集(対訳コーパス)の構築に期待したいと思います。
以上のお話で、機械翻訳は人間の翻訳の仕方をまねたものであること、 そして、機械翻訳を成長させるには対訳例文を集める必要があることを ある程度お分かりいただけたと思います。 むすびの前に、もう少しおつき合いください。
翻訳における人間とコンピュータの基本的な違いは何でしょうか。 人間は、たとえ英語を習い始めたばかりの中学生だとしても、日本語はよく知っています。 しかし、コンピュータは英語はおろか日本語すら知らないのです! 知らない言葉から知らない言葉への翻訳----そう、それが概械翻訳の実態なのです。
それを踏まえると例文集に対する見方も当然変わってきます。 人間は(ある段階以上からは)表現を豊かににするために例文集を利用し、 コンピュータはとにかく訳を付けるために「対訳」例文集を必要とすると言えるでしょう。
機械翻訳は色々な意味で対訳例文を必要とします。 対訳例文は翻訳家のノウハウによって得られます。 翻訳家という専門家から知識を得て成り立つのですから、 見方を変えると機械翻訳はエキスパートシステムの一種です。 しかし、一般のエキスパートシステムと違って、 機械翻訳は極めて広い言語表現の範囲をカバーすることを義務づけられてきました。 「適用範囲を限らなければ使えない」というのが機械翻訳に対する一般的な評価だと思いますが、 これは「適用範囲を限れば使える」ということです。 筆者も機械翻訳にかかわる1人として、 まずはそのような意味で使える機械翻訳を作りたいと考えています。