| 1. はじめに | |
| 2. 翻訳の基本方式 | |
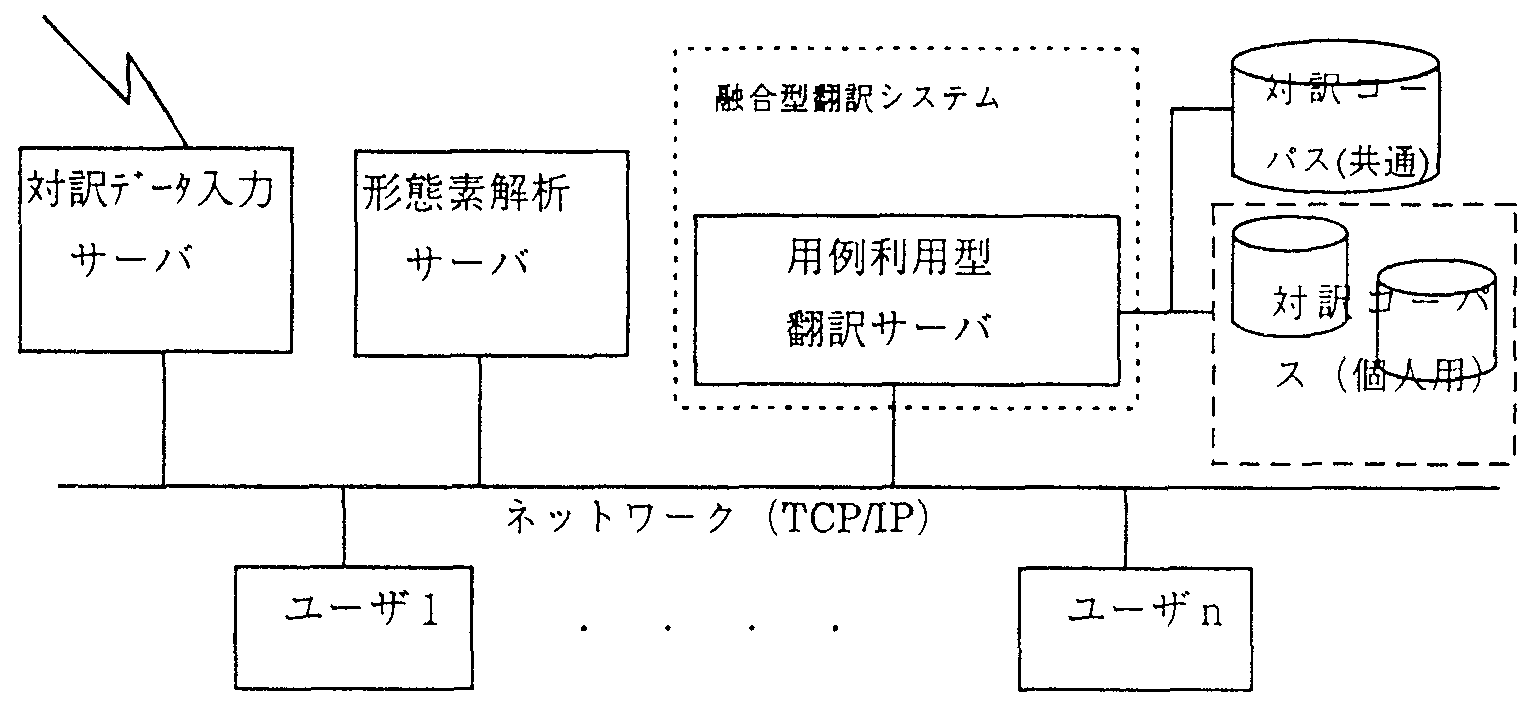
| 3. システム構成 | |
| 4. むすび | |
| 謝辞 | |
| 参考文献 |
用例利用する翻訳の利点として, (1)慣用的表現や意訳表現, あるいは業務分野特有な表現等の対訳文を活用でき、 また、(2)日英、英日等の双方向翻訳への展開が期待できる。 しかし、従来は1:1対応の対訳コーパスに 単語やフレーズなどのタグが付与されていることが前提となっているため、 大規模な対訳コーパスの生成が困難であった。 文の緩い対応付け(厳密ではないが、ある程度直訳的な対応付け)のみが行われた 対訳コーパスを用いて翻訳するのが可能となれば適用領域が拡大する。 本稿では、用例利用型日英翻訳として、下記を視野に入れたシステム構成を提案する。
| 対 | 訳コーパスの構成: 対訳コーパス(文対応のみ)の和文と英文は別々のファイルに格納され、英文用ファイルには和文とのリンク情報を含む。さらに、和文の任意の位置から検索できるN-gram形式のインデックスファイルを作成する。 |
| 候 | 補文の検索: N-gramインデックスにより入力文の形態素がある割合以上含まれる対訳コーパスの和文を候補文として抽出する。 |
| 候 | 補文の評価: 候補文と入力文の動詞の部分や各文の形態素の並び順(を格に格等)、さらにはパターン対辞書利用による英訳文等、の一致性を考慮した類似度により類似文を選択する。
(注)類似の定義: 入力文と候補文の文間距離の基本概念は, 候補文の形態素を入力文の形態素の並びに極力一致するようバブルソートした際の スワップ回数とした。 文間の類似度は、入力文と候補文の間の双方向からの距離、 複数動詞の順序関係や活用変化からの距離、 および「をに」格の品詞の一致の有無・順序関係の距離等を考慮した総合的な値とした。 |
| 英 | 文の生成: 入力文と類似文での差異を識別し、該部分に対して辞書またはルール型翻訳により英訳を取得し、置換修正する。 |
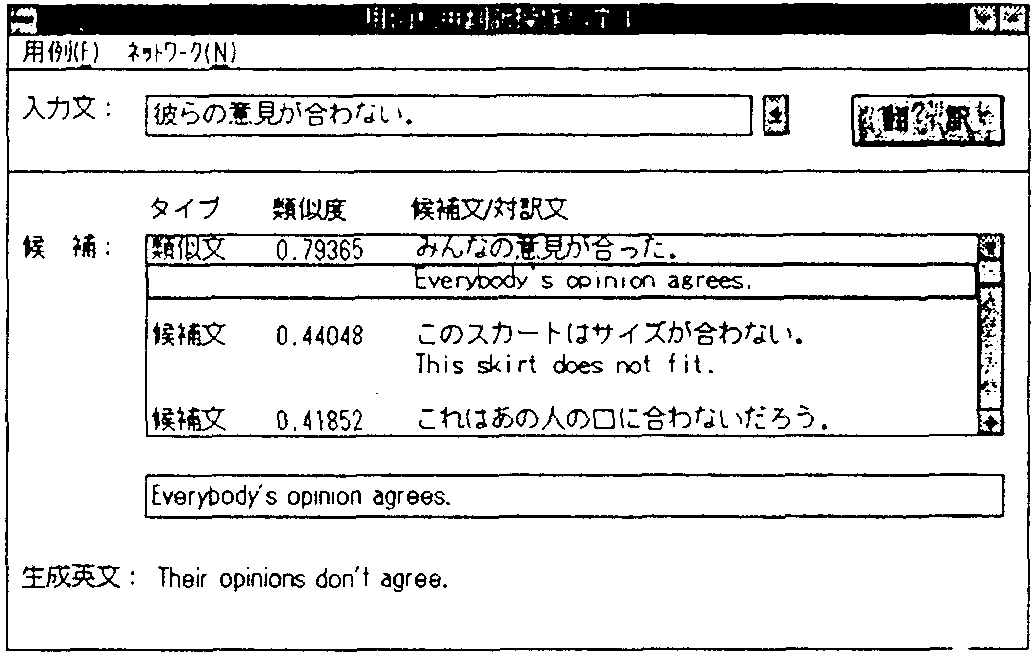
構成: システム構成を図1に、GUIを図2に示す。
|
|
|
特徴: 主な特徴を以下に述べる。
緩い対訳データで動作可能なこと、多くのユーザが同時利用できることねらいに、 ネットワーク対応の用例利用型日英機械翻訳システムを開発および評価中である。 現在、文の解析は形態素解析のみであるが、 今後は類似判定の適正化、構文解析や意味解析等の導入、 さらに英文生成の改良を進める予定である。
ご討論くださったNTTアドバンステクノロジ(株)の田邉 俊明氏に感謝する。