|
(a)言語過程説(時枝・三浦)の言語モデル
|
(b)チョムスキーの言語モデル
| * | 鳥 | 取大学工学部知能情報工学科、680鳥取市湖山町南4-101 |
| TEL:0857-31-6743 FAX:0857-31-6743 Email:ikehara@ike.tottori-u.ac.jp | ||
| ** | 新潟大学工学部情報工学科、950-21新潟市五十嵐2の町8050 | |
| TEL:025-262-6745 FAX:025-261-2502 Email:miyazaki@info.eng.niigata-u.ac.jp | ||
| *** | NTTコミュニケーション科学研究所知識処理研究部、238-03横須賀市武1-2356 | |
| Tel:0468-59-2518 Fax:0468-59-3633 Email:Shirai@nttkb.ntt.jp | ||
計算言語学は学問として大きく発展してきたが、 その成果は現実の自然言語処理が抱える重要な問題に対してはとんど無力である。 その基本的な原因は、計算言語学が歴史的に言語の形式と内容を切り離し、 形式と論理の問題に抽象化してきたためと考えられる。
日英機械翻訳システムALT-J/Eでは、このような計算言語学の限界を克服するため、 現実の言語を実践的に扱う観点から多段翻訳方式を提案し、実現した。 本方式は日本の伝統的な文法の一つである時枝(三浦)文法(=言語過程説)を背景に考案した 方法であり、話者の存在を意識した主体的表現の扱いと表現構造の持つ意味の扱いに特徴がある。 技術的には、本方式は言語知識をベースとする意味解析技術に支えられている。 意味解析のための言語知識として 40万語の単語意味体系と1.5万パターンの構文意味体系を作成したが、 これらは約400種の文法体系と約3,000種の意味体系の体系で書かれており、 同じ意味体系でルールを書けばこれらの知識が動員されて翻訳が実行される構造となっている。
計算言語学はチョムスキーによる生成文法の提案以来大きく発展し、 その知見は計算機言語の設計に大きく役に立ってきた。 しかし、実際の自然言語処理の基本的問題ともいえる多義解消の問題に対してほとんど無力であり、 現実とのギャップは大きい。 この原因はどこにあるのであろうか。 理論の行き詰まりや限界はその理論の初期の前提に原因が内包されていることが多い。
従来、計算言語学は言語を整合のとれた理論的モデルで表現し、 統一的な手法で処理することを追求してきた。 しかし、現実の自然言語はそのように整合のとれたものではない。 自然言語は、人間社会において自然発生的に成長してきた慣習であるから、 それぞれの言語が成長してきた社会を反映している。 人間の社会はさまざまな歪みや矛盾を内包し、それを見る見方、捉え方はさまざまである。 自然言語は、このような社会的に異なる物の見方を反映しているため、 言語によって表現の枠組みには大きな違いがあり、 それをすべて統一的手法で処理することは困難である。 すべての実用的科学がそうであったように、言語においても、 汎用的な理論を考える前に、個別の言語の科学を打ち立てることが望まれる。
従来、自然言語処理には、人工知能的アプローチと計算言語学的アプローチが見られるが、 前者が言語の形式と同時にその表す現実の世界の内容を取り扱おうとしてきたのに対して、 後者は言語を現実から切り離し、形式の問題に集中してきたように思われる。 確かに計算言語学は構造言語学の抱えていた同形式異内容の問題の解決を試みた点で、 表現の内容を取り上げようとしたとも言える。 しかし、その方法は、 現実の表現から離れたところに深層構造と言う意味の存在を仮定するものであったため、 形式と内容は別物として扱われることになってしまった。 深層構造の存在を仮定し、それを表現の意味と説明したのでは、 意味を単に深層構造と言い換えたに過ぎないことになる。 また、深層構造の存在の仮定で、 現実の言語における対象と話者の関係が無視されているのも問題である。
言語翻訳家の中には、 「翻訳は、まず慣用句から慣用句への変換から始まる」と言う人もいるくらい、 慣用的表現もしくはそれに準ずる表現(以下では、 言い回しなどを含む広い意味で「慣用的な表現」と言う)の重要性が指摘されている。 言語表現では、使用頻度の高い表現ほど慣用の傾向を持つが、 このことは、言語が慣習であることをよく物語っている。 これに対して、計算言語学では、 慣用的なものは要素合成法の原則に外れるとして、対象外とされている。 慣用表現の例を引くまでもなく 実際の自然言語で要素合成法が成り立つと考えている人は少ないと思われる。 それにもかかわらず、この前提の持つ限界は、はとんど議論の対象とされていない。 限界を感じている人たちは、解決をあきらめ、議論を避けている嫌いさえある。
言語を社会的な慣習としての社会的規範の一種だと考えると、言語処理では、まず、 それぞれの言語で成り立っている社会的規範の中身を研究する必要がある。 日英機械翻訳では、日本語と英語の個々の現象に立ち入って、 日本語の規範と英語の規範との違いを明らかにしなければならない。 このような観点から、我々は、 実際の日本語の表現と取り組んできたと考えられる従来の言語学の成果に着目して、 新しい自然言語処理の方法論を提案する。 我々の研究の背景にあるのは、 本居宣長以来の国語学の伝統を汲む時枝(三浦)誠記の言語過程説である。 我々は、この考えに基づいて意味解析技術を基本とする多段翻訳方式を提案し、 その効果を確認するため、日英機械翻訳システムALT-J/Eを試作した。 本システムの特徴を要約すれば表1のようになる。
| 番号 | 項 目 | 特徴点 |
| 1 | 言語理論 | 言語過程説 |
| 2 | 翻訳方式 | 多段翻訳方式 |
| 3 | 基本技術 | 意味解析技術(Not意味理解) |
| 4 | 言語知識 | フルスケールの日本語意味大系 |
| 5 | 主な機能 | 意味解析型各種新機能 |
本論文では、自然言語処理の立場から、表1の順に従って、 まず、従来の計算言語学の考え方の問題点と、それに代わる言語過程説の意義を示す。 次に、ALTシステムの基本方式である多段翻訳方式の構成概念と本方式を支える意味解析の考え方、 ならびに意味解析に必要な言語知識ベースとしての日本語意味大系について述べる。
(1)計算言語学の背景
古代ギリシャ時代から、論理学には、弁証法論理学と形式論理学の2つのタイプのある。 アリストテレスに始まりヘーゲルによって集大成されたと言われる弁証法論理学は、 論理の内容、すなわち、対象の現実の存在をも考えるべきだとするのに対して、 プラトンに始まる形式論理学は、純粋にして理想的な世界を対象とすべきだとして、 形式とその表す内容を切り離した。
記号論理学、数理論理学、計算言語学はいずれも形式論理学の流れを汲んでいる。 計算言語学は、論理学の成果を自然言語処理に適用しようとしているが、 自然言語は、現実の複雑な世界を扱ったものであるため、その内容が問題となる。 従って、内容を超越する形式が主たる議論となっている形式論理学とは親和性に欠ける問題があり、 このことが、さまざまな問題の原因とも考えることができる。 特に、自然言語では、後で述べるように、 これらの論理学で大前提とされているフレーゲの原理(要素合成法の原理)の成り立たないことが、 大きな問題といえる。
(2)日本語と英語の発想法の違い
日本語と英語の言語の違いについて考える。 英語は比較的内容と独立した5文型を持つなど、文の形式が発達しており、 スーツケース型の言語と言われている。 このことが、表現形式を第一義とする形式主義の研究の基礎となったと考えられる。 構造言語学が未解決とする同形式異内容の問題の解決を狙ったチョムスキーも、 このようなヨーロッパ言語の中に閉じていたためか、 形式論理学の限界を超えることはできなかった。
これに対して、日本語は、表現の形式が比較的自由で、 英語のような定まった文型のない言語であり、風呂敷き型言語ともいわれる。 すなわち、内容の形が表現の形に表れるから、 日本語処理では、形式よりもむしろ内容が重要と考えられる。 このような観点から、日本の伝統的な言語学では、本居宣長以来、 日本語表現の内容と形式の関係に着目した文法が考えられてきた。 その最も代表的な文法が時枝文法であり、 対象が話者に認識される過程と認識が言語表現に対応づけられる過程をモデル化している点で 言語過程説と呼ばれている。
(1)生成文法との比較
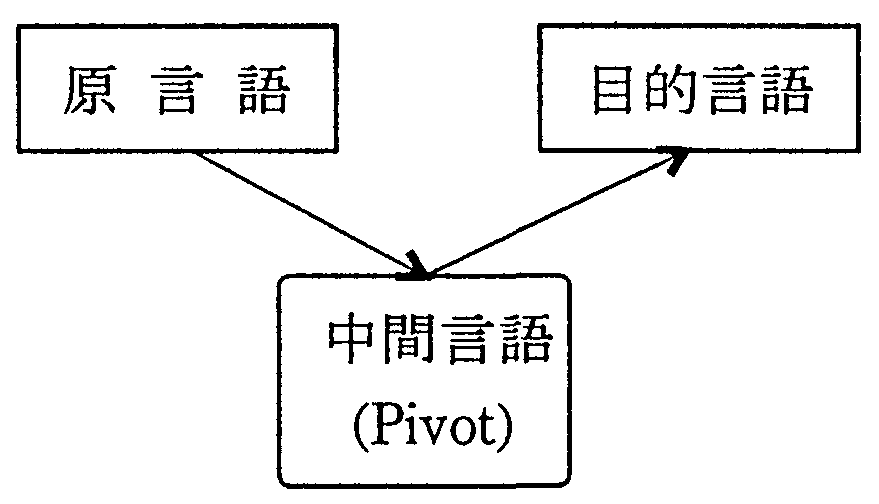
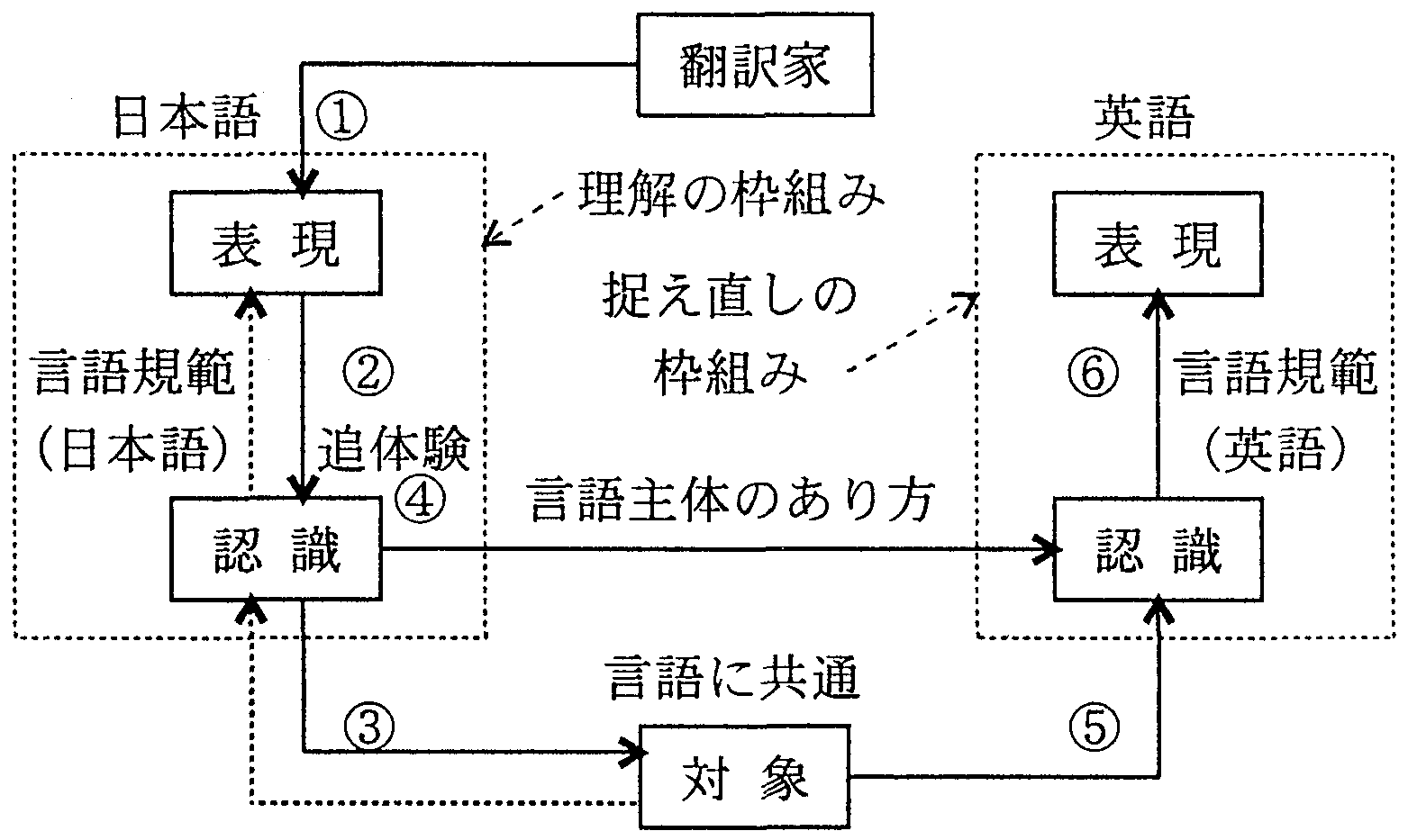
図1に、言語過程説とチョムスキーの生成文法との言語モデルの違いを示す。 言語過程説では、言語は、「対象」、「認識」、「表現」の関係からなる 複合的な過程的構造体として説明される。 話者の理性と感性を通して得られた対象に関する「認識」は、 言語の持つ約束(慣習)に従って「表現」に結び付けられる。 「対象」が「認識」に反映するプロセスは反映論の領域であるが、 「認識」が「表現」に結び付けられるプロセスは、言語学の領域である。 言語の持つ約束は、それぞれの社会に自然発生的に育った社会的慣習といえるものであり、 広い意味で文法と呼ばれる。 従って、言語過程説から見れば、 自然言語処理の研究では、社会的約束である文法の構造と体系を明確にし、 それを応用して言語処理の方法を考えることが中心となる。
(a)言語過程説(時枝・三浦)の言語モデル
|
(b)チョムスキーの言語モデル
|
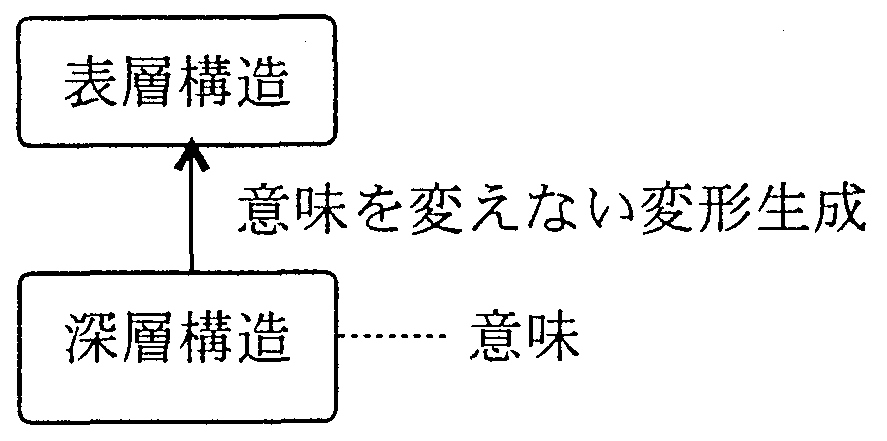
これに対して、チョムスキーは、言語を「表層構造」と「深層構造」の二重構造で説明した。 「深層構造」の存在を仮定したのは、表現の意味を説明するためで、 表層は同じ構造でも意味の異なる表現が存在する理由を 「深層構造」の違いとして説明しようとしたためである。
この説では、表現の意味は「深層構造」だとされているが、 肝心の「深層構造」は例示されたにとどまり、定義が与えられなかった。 このため、表現の意味を説明する目的でその表現の意味を仮定するという奇妙な理論になっている。 その後、チョムスキー自身、さまざまな修正を行ったが、 依然として「深層構造」の存在が仮定されている。 同様、生成文法の流れを汲む最近の計算言語学の多くの文法理論も、 「深層構造」の存在を仮定している。
ところで、「深層構造」を本来の意味から変えて「話者の認識した内容」だと解釈する考えがある。 この考えは、言語過程説と似ているが、対象とそれに対峙する話者の関係を見落としている点、 「認識」と「表現」の関係を依然として生成としている点の2つの点で、 言語過程説とは大きく異なる。 特に、言語処理では、後者の点は重要である。 「認識」と「表現」の関係を「対応関係」と捉えるか、「生成」と捉えるかによって、 文法体系がまったく異なったものになり、言語処理の方法も変わってしまう。 実際、現実の言語は、意味的にさまざまな解釈が許容されるが、 これを生成の方法で解釈するのは困難である。
(2)言語の過程的構造
ここで、言語過程説では、「対象」、「認識」、 「表現」がどのような因果関係を持つものとして説明されるかを見よう。
言語の対象世界は、図2の左欄に示すように、 「話者(主体)」とそれ以外の「対象(客体)」とから構成される。 話し手以外の対象は、実体と属性と関係の3つの要素に代表される。 話し手は、対象世界と同時に自分自身のことがらについても認識する。 話者自身については、2つの認識の仕方がある。 一つは、概念化されない話者自身の感情や意志に関する直接的な認識である。 もうひとつは、話者自身を対象化し、概念化した認識である。 話者自身を対象化するときは、観念的な自己分裂が行われ、 自己分裂した話者が、自分を他の対象と同様、客体化して捉えられる。
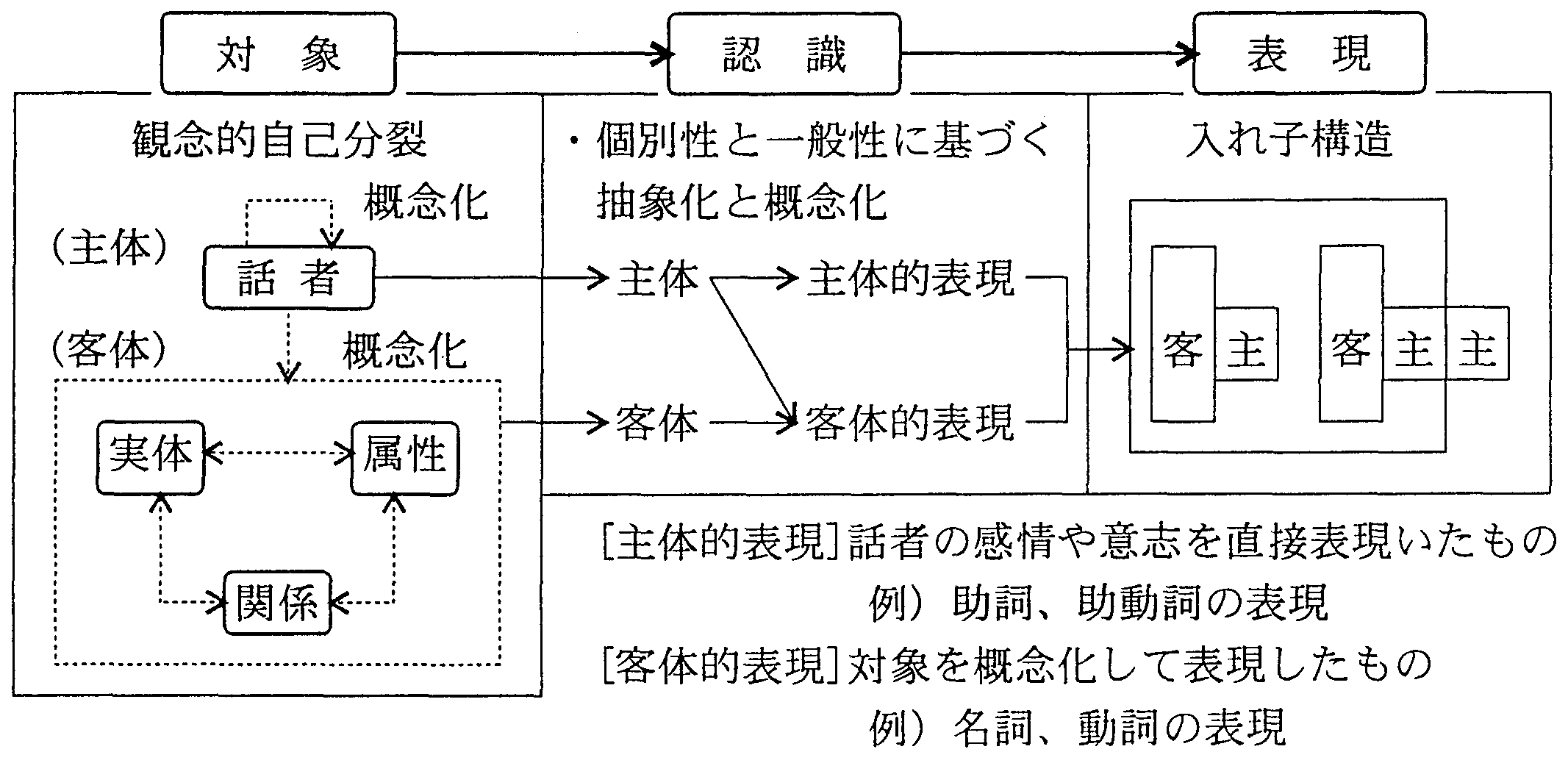
|
「主体」と「客体」に関する「話者の認識」は、図2の中央に示すように、 「主体的表現」と「客体的表現」の2種頬の言語表現に対応づけられる。 「主体的表現」は、主体の対象に関する感情や意志を直接表現するもので、 日本語では、助詞、助動詞などの付属語(辞)が使用される。 これに対して、「客体的表現」は、概念化された対象の姿をあらわすのもで、 名詞や動詞などの自立語(詞)が用いられる。 表出の段階では、図2の右欄に示すように、 「客体的表現」とそれに対応する「主体的表現」がペアを構成し、 入れ子構造の表現が形成される。 入れ子構造が形成される過程で、実体の取り上げ方は助詞で、 それを含む対象世界の取り上げ方は助動詞で表される。
「言語表現の意味」については、今まで、言語学、 哲学の分野において多くの議論がなされてきたが、いまだ定説がない。 また、自然言語処理の分野でも意味解析、意味理解、意味処理などと称する数多くの研究が、 意味を定義しないまま行われている。 哲学的には議論の分かれる議論を言語処理の立場から改めて考察することは重要な意味がある。 また、それ以上に、自然言語処理を一つの科学として打ち立てていくには、 その処理対象とする「言語表現の意味」について、 科学的基準として使用に耐える定義を明確にする必要がある。 そこで、ここでは、言語処理に適用することを念頭に、 言語過程説の立場から「言語表現の意味」について考える。
言語過程説によれば、言語を構成する言語実体は、 「対象」、「話者の認識」、「表現」および「聞き手の理解」の4つである。 従って、言語表現の意味が言語実体であるとするなら、意味は、上記の4つのいずれかとなる。
そこで、意味が形式から生れるものと考えると、構造言語学と同様の問題、 すなわち、「同形式異内容」の説明で行き詰まる。 そこで、形式は内容から生れると考えれば、「対象意味論」か「認識意味論」のいずれかになる。 しかし、この場合、「対象」や「認識」は誤っていないとすると、 誤って書かれた表現の意味も正しいことになり矛盾が生じる。
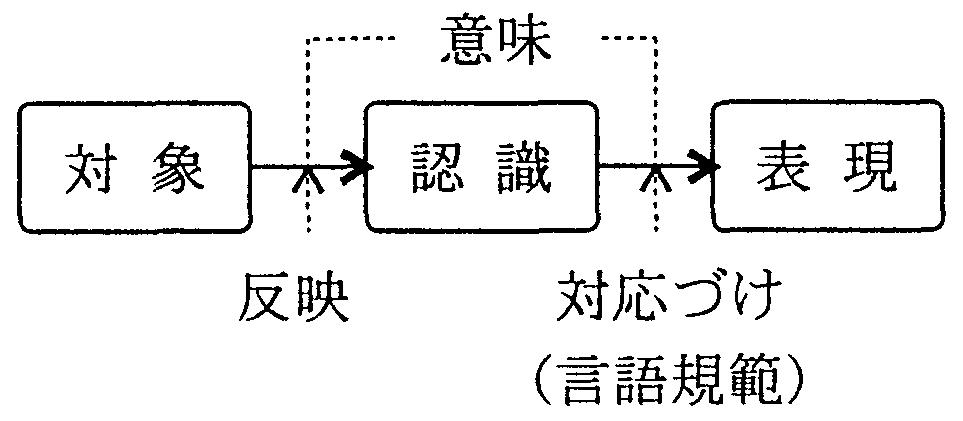
このような点から、時枝誠記は、言語実体を意味とはせず、 話者と聞き手の双方にある「把握の仕方」を意味とした。 確かに、話者と聞き手の把捉の仕方は共通する点が多いが、 それは、両者が同じ言語規範に支えられているためであるから、 「把握の仕方」は、「言語規範の適用の仕方」と言うことになる。 そこで、三浦つとむは、これを機能論的説明だとして改め、「関係意味論」を提唱した。 すなわち、彼は、「表現」に結合された「対象」と「認識」の関係を意味としている。
ところで、時枝と三浦の意味論の関係を考えると、 言語処理では「言語規範の適用の仕方」を考えなければ 「対象に結合された対象と話者の関係」は明らかにならないから、 両者は、言語処理上、同一線上にあるといえる。 しかし、後で述べるように、計算機上、関係はボインターで表現されるのに対して、 「適用の仕方」は表現が困難であるので、ここでは、後者の考えを採用する。 ただし、「対象」は直接「表現」結合されるのではなく、 話者の目を通して得られた「認識」が「表現」に結合されるのであるから、 ここでは、より限定的に捉え、「表現」と「認識」の関係を意味と考える。
「表現と」と「認識」の関係は、現実の言語表現に固定されたもので、 話者の認識であっても表現に対応づけられていないものは意味ではない。 また、聞き手によって異なる意味になることもないため、 客観的であり、意味処理のターゲットに使える利点がある。 関係は、計算機処理ではポインターで表現されるから、意味はポインターそのものである。 従って、計算機処理では、図3に示すように、 表現と話者の認識を対応づけるポインターを張ることが意味処理だと言うことができる。
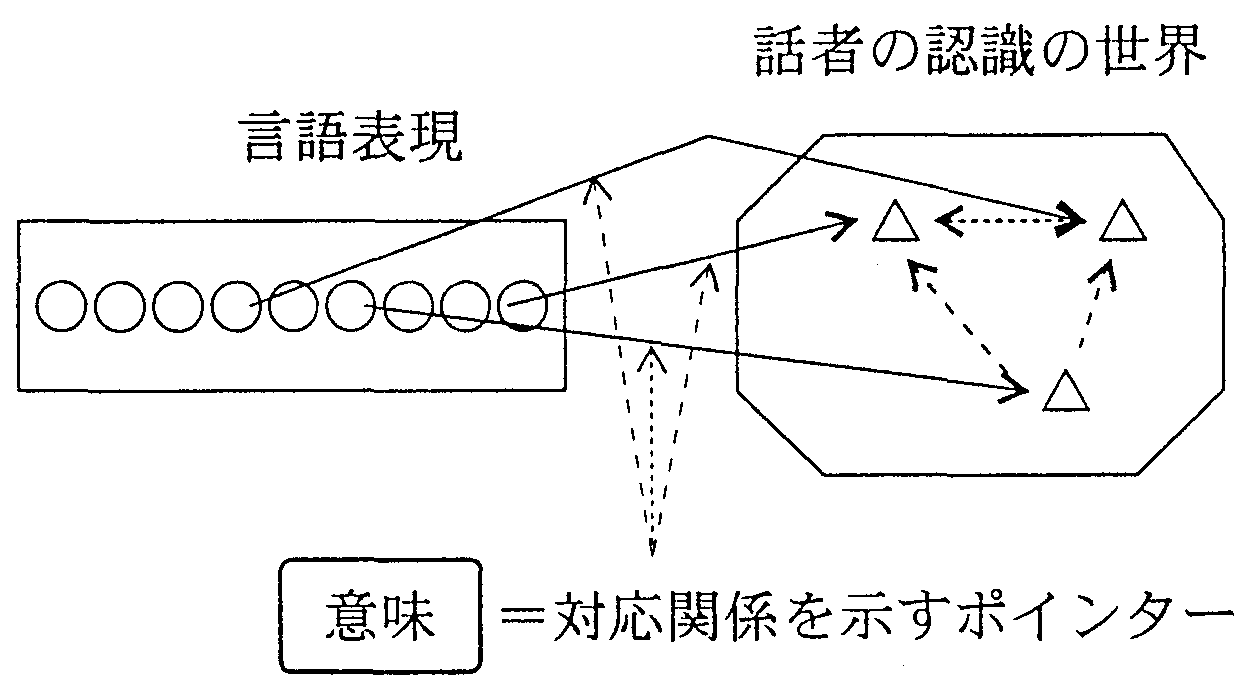
|
関係意味論は、最近の「状況意味論」の主張するところであるが、 このような三浦の意味論とは本質的な点で異なっている。 「状況意味論」では、与えられた表現がもたらす情報量に着目し、 ある文脈で、すでにある情報量が得られているとき、新たに別の表現が与えられたとすると、 その表現の意味は、 元の状態の情報量と新たに与えられた表現を理解した後の状態の情報量との差であるとしている。 この議論は、同一の表現でも、 それがおかれた場所によって情報量が異なる点を扱うことができる点で優れているが、 表現の意味と表現が置かれた場の問題を区別していない点に問題がある。 表現の置かれた場は、与えられた表現の意味を解釈するための手がかりを与えるものである。 実際の言語表現には話者の特定の認識や意図が表されているにもかかわらず、 表現の意味と場の問題を区別しなければ、言語表現の意味は、 その表現単独では定義できないものになってしまう。
(1)意味処理の内容
ここでは、言語表現が与えられたとき、それを理解するプロセスを考える。 すでに2.2節で述べたように、言語表現には、 「客体的表現」によって話者の目を通して認識された対象の姿が表され、 「主体的表現」によって、その対象に関連する話者の感情や意志が表現されている。 従って、言語意味理解とは、言語表現から、 それに表された対象に対する話者の認識を追体験することと言える。 しかし、追体験される程度は、その人の知識にも依存する個人差があり、 工学的にも、どれだけ追体験できたかを示すことは難しい。 ここでは、追体験できたかどうかは、表現の内容に関する質問と応答によって判定されるものとし、 ある言語表現が与えられたとき、 その内容に関する通常の質問に応えられるような世界が計算機内に構築できたとき、 意味理解ができたと考える。
そこで、計算機内にそのような世界を構築する方法を考える。 前節では、「言語表現」と「認識」を結び付けるのは言語上の約束であり、 実際の表現に使われた約束が意味であることを述べた。 文やテキストでは、このような約束が沢山使われているが、 意味理解するためには、まず、実際の文に対して、この約束を特定することが必要である。 次に、文中で使用された約束が特定されたとすると、 この約束は、計算機上は、ポインターで表現されるから、 その片方の端には言語表現が結合されているが、 もう一方の端には、話者の認識や対象の姿の断片が結合されるはずである。 通常、文やテキストではこのような約束が複数使用されているから、 話者の認識を再現するには、 断片的な対象の姿や話者の認識をつなぎあわせて総合的な世界を構成すれば良いことになる。
そこで、計算機による追体験のプロセスを図4に示すように、 意味解析と意味理解の2つのステップに分ける。

|
第1のステップは、実際の言語表現に使用された「意味的な約束」 (表現構造上の役割を示す「文法的約束」と区別する)を決定する処理で、 これを「意味解析」呼ぶ。 第2のステップは、意味解析で決定されたボインターの片側に結び付けられた断片的な情報から、 話者の認識した世界を再現する処理で、これを「意味理解」と言う。
(2)意味解析の内容
意味解析の例として、以下の文の表現で使用された約束について考えよう。
(a)その店は 高い 油を 売って いる。
単語「高い」の意味的約束を辞書で調べると、 「高貴な」、「高価な」、「気高い」、「上に長い」、「多い」などがある。 このうち、この文で使用されている約束は、 「この語は「高価な」と言う意味で使う」という約束である。 「油」にも、「油脂(オイル)」、「アルコール」、「脂肪」、「油蝉」を表すなど、 いろいろの約束があるが、ここでは、「油脂(オイル)」を表すという約束が使われている。 このように、意味解析では、言語の持つ多くの約束の中から、 実際の文に使用された約束はどれであるかを決定する。 意味解析は、一語、一語、眺めただけではうまく行かないことが多い。 次の文を見よう。
(b)背の 高い 男が 仕事中 油を 売って いる。
「背の高い」を直訳すれば、"back is high"となるが、英語ではその意味は"tall"である。 従って、「背」と「高い」の持つ約束を別々に考えたのでは、"tall"は出てこない。 同様のことが「油を売る」についても言える。 「油」と「売る」の組み合わせで「怠ける」ことを表すことが分かって初めて、 それに相当する英語の表現、"idle away one's time"と対応づけることができる。
このように、意味的約束は、単語単位に考えるだけではだめである。 対象の持つ構造も話者の認識に反映し、それが表現に対応づけられるのであるから、 表現の構造も意味の一部である。 従って、「意味解析」では、意味的約束の成り立つ構造上の範囲、 すなわち、表現構造上の意味の単位を明確にすることが重要な処理となる。 このように、表現構造の持つ意味を扱うことは、 計算言語学の前提とするフレーゲの原理を克服することを意味する。 すなわち、要素合成法の限界を超える処理を実現することが、 「意味解析」の大きな課題だと言える。
ところで、「意味解析」で使用される知識は、言語の意味上の約束であるから、 それぞれの言語に特有の知識である。 従って、「意味解析」を実現するには、「言語知識」として、 対象とする言語の意味的約束とその適用条件を体系化しておくことが必要である。
(3)意味理解と世界知識
既に述べたように、「意味理解」は、 ボインターの先端に示された断片的な世界の部分をつなぎあわせて、 話者の見た世界とそれに対する話者の判断や意志を再現する処理である。 断片的な世界の部分を統合して一つの対象世界を再現するには、 表現されなかった世界の部分を補完する必要がある。 従って、「意味理解」を実現するには、あらかじめ、対象世界に対して、 話者と共通するある一定の背景知識が必要である。 聞き手が話者と共通する世界知識を持たないときは、 話者の認識を追体験し、対象世界を再現することはできない。
前節で、「意味解析」では言語知識が必要とされるのに対して、 「意味理解」では対象世界に対する世界知識が必要であることを述べた。 「意味解析」と「意味理解」の関係を図5に示す。
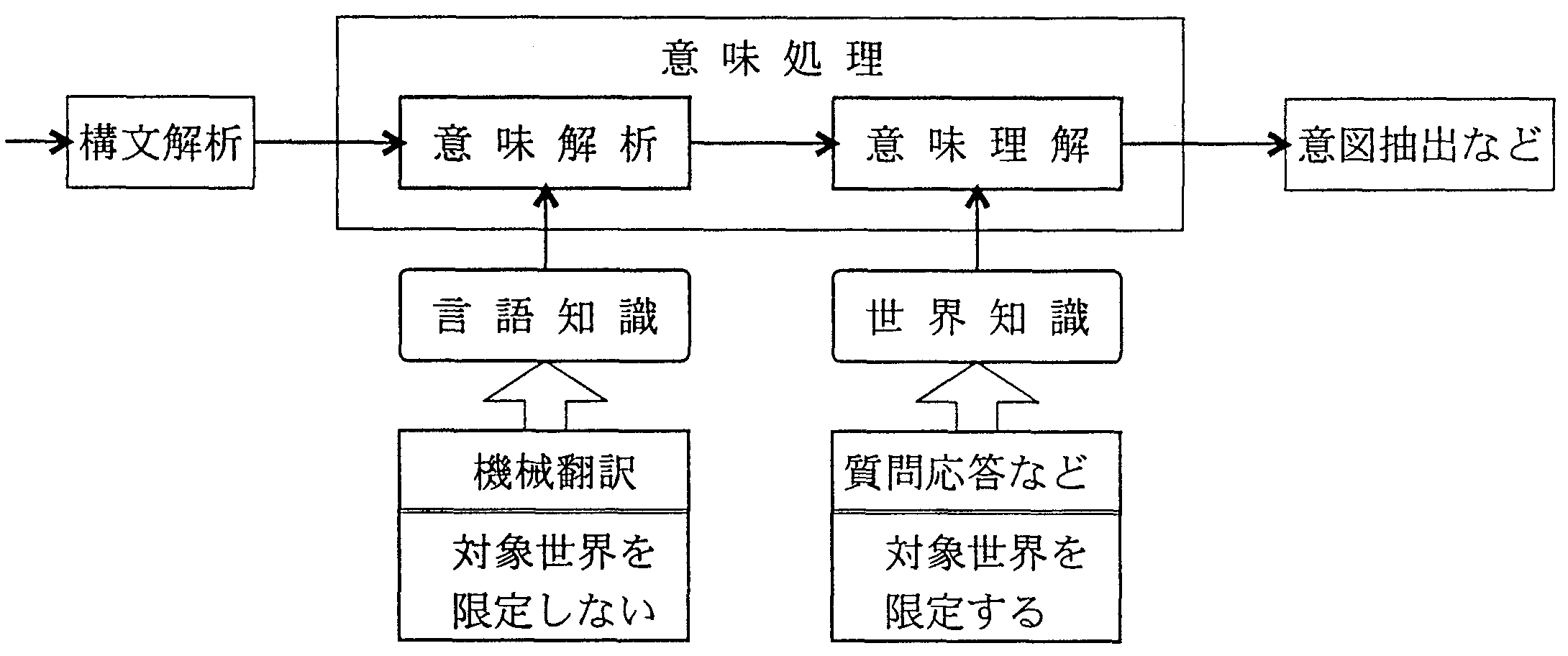
|
言語知識に比べて、世界知識は膨大で、 あらかじめ、そのすべて計算機上に準備することは不可能に近い。 特に、機械翻訳では、翻訳対象とされるテキストの対象分野は広く、 広範囲な世界知識を必要とするため、「意味理解」の実現は困難である。
ところで、機械翻訳の結果から原文の意味を理解するのは人間であることを考えると、 計算機自身が原文の意味を理解しなくても、「意味解析」のレベルで翻訳すれば、 人は翻訳結果から元の意味をはば理解できる可能性がある。 すなわち、日本語の「意味解析」によって日本語表現に使用された意味上の約束を特定し、 それに相当する英語の意味上の約束を用いて、日本語表現を英語表現に置換えれば、 読者はその結果から元の日本語の内容を理解できることが期待される。 ALT-J/Eでは、「意味理解」のための世界知識ベース構築の困難さを避けるため、 このような仮説の元に翻訳方式を設計した。
ALT-J/Eでは、まず、「意味解析」技術を実現して、それによる機械翻訳を試作実験し、 「意味解析」のレベルでの機械翻訳の限界を明らかにする。 次の段階で、「意味解析」では翻訳困難な現象に絞って世界知識を準備し、 「意味理解」の研究を行う方針とした。
以上の通り、機械翻訳では、「意味解析」を基本技術と考えたが、 質問応答システムやコンサルティングシステムの場合は、「意味理解」の技術が必須と考えられる。 その場含も、世界知識ベースの構築がネックとなるが、 このネックは、対象範囲を飛行機予約や会議案内などのように 狭い領域に限定することによって避けることが可能と考えられる。
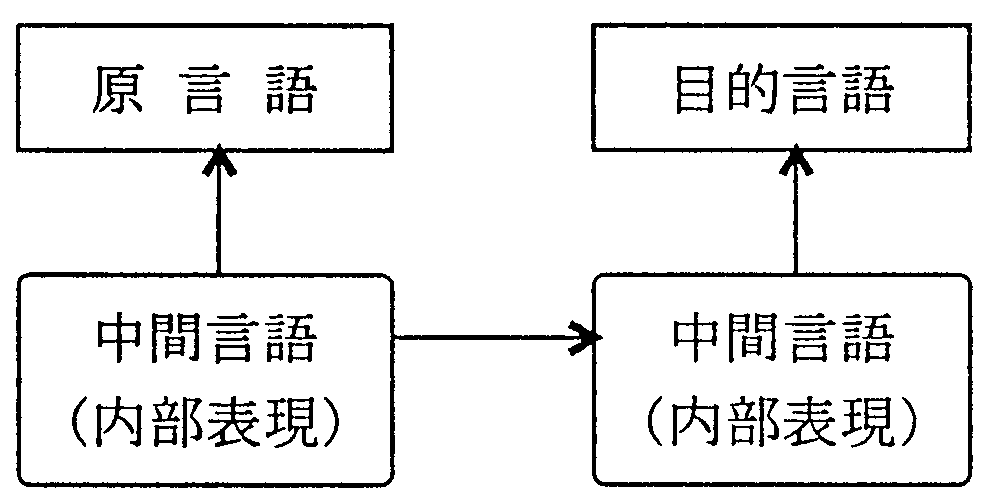
従来の機械翻訳方式は、図6に示すように、 「トランスファー方式」と「中間言語方式(インターリンガ方式)」の二つに大別される。 「中間言語方式」はユニバーサル言語の存在を仮定し、 すべての言語をそれを介して翻訳しようとするものである。 多言語翻訳に適していると考えられるため、多くのシステムがこの方法の実現を目指している。 しかし、現実に「中間言語方式」が実現された例はない。 これは、すべての言語を内包するような中間言語の表現が設計できないためである。
(a)中間言語方式(インターリンガ方式)
|
(b)トランスファー方式
|
自然言語は、その言語を使用する地域や社会の人々の物の見方、 捉え方を反映したものであるから、「中間言語方式」を実現するには、 すべての言語の持つ概念化の方法や思考パターンを含む中間言語を設計すれば良い。 しかし、あらかじめ、すべての言語の表現を網羅するような言語を設計することは不可能である。 また、もし逆に、このような言語ができたとすると、 その言語はすべての言語の表現法含んでいることになるから、 原言語、目的言語の表現のいずれもが、 そのままユニバーサルな言語の表現そのものだと言うことになり、 翻訳は、同一言語内での言い替えと変わらなくなる。
そこで、第2の方法として、すべての言語に共通する概念化と思考パターンだけを取り出して、 それを中間言語とする方法が考えられる。 科学技術分野のテキストや同一言語族の言語間などでは、 比較的世界的に共通した概念と思考のパターンをもつと考えられるから、 この方法は近似法として成り立つ可能性がある。 しかし、言語によって概念化の異なる対象は、中間言語で表現できないことになり、 日常的な文への適用は困難である。
第3の方法としては、概念化の方法や思考パターンをある一定の方法で形式化した 新しい言語を設計することが考えられる。 しかし、このような言語をすでに存在する言語と独立に設計することは困難である。 現実に、「中間言語方式」を志向するシステムは、第3の方法を志向しているが、 実際は、英語など世界の有力な言語の内部表現を そのシステムの中間言語として採用しているに過ぎないから、 実質的には、以下で述べるようなトランスファー方式となっている。 従って、英語とは語族の異なる日本語や中国語間の翻訳の場合、 英語を基本とする中間言語方式は、トランスファー相当の方式を2回適用する結果となり、 翻訳品質の向上は難しい。
これに対して、「トランスファー方式」は、ユニバーサルな言語を仮定せず、 それぞれの言語間で表現をトランスファーするものであるため、現実的といえる。 しかし、「トランスファー方式」の中にも、 原言語の「深層構造」を目的言語の「深層構造」にトランスファーする考え方がある。 原文の情報を正しく保持できるよう設計することの困難な深層構造を わざわざ設ける必要はないため、 ここでは、原言語の中間表現から目的言語の中間表現へのトランスファーを考えることにする。
ところで、中間言語方式が同一言語族間の翻訳で近似的になりたつ可能性のあることを考えると、
多言語翻訳を実現する方法として、図7に示すように、
中間言語方式とトランスファー方式を組み合わせて使用する方法が考えられる。
すなわち、同一言語族の相互間では、中間言語方式を、また、異なる言語族では、
それぞれの言語族を代表する言語間でトランスファー方式を実現しておき、
代表とされなかった言語間の翻訳は、それぞれの言語族の代表言語を介して翻訳する方法である。
この場合、降着膠着言語の代表を日本語、屈折言語族の代表を英語と考えると、
日英機械翻訳は、言語族間を結合する翻訳パスで、トランスファー方式で実現されることになる。
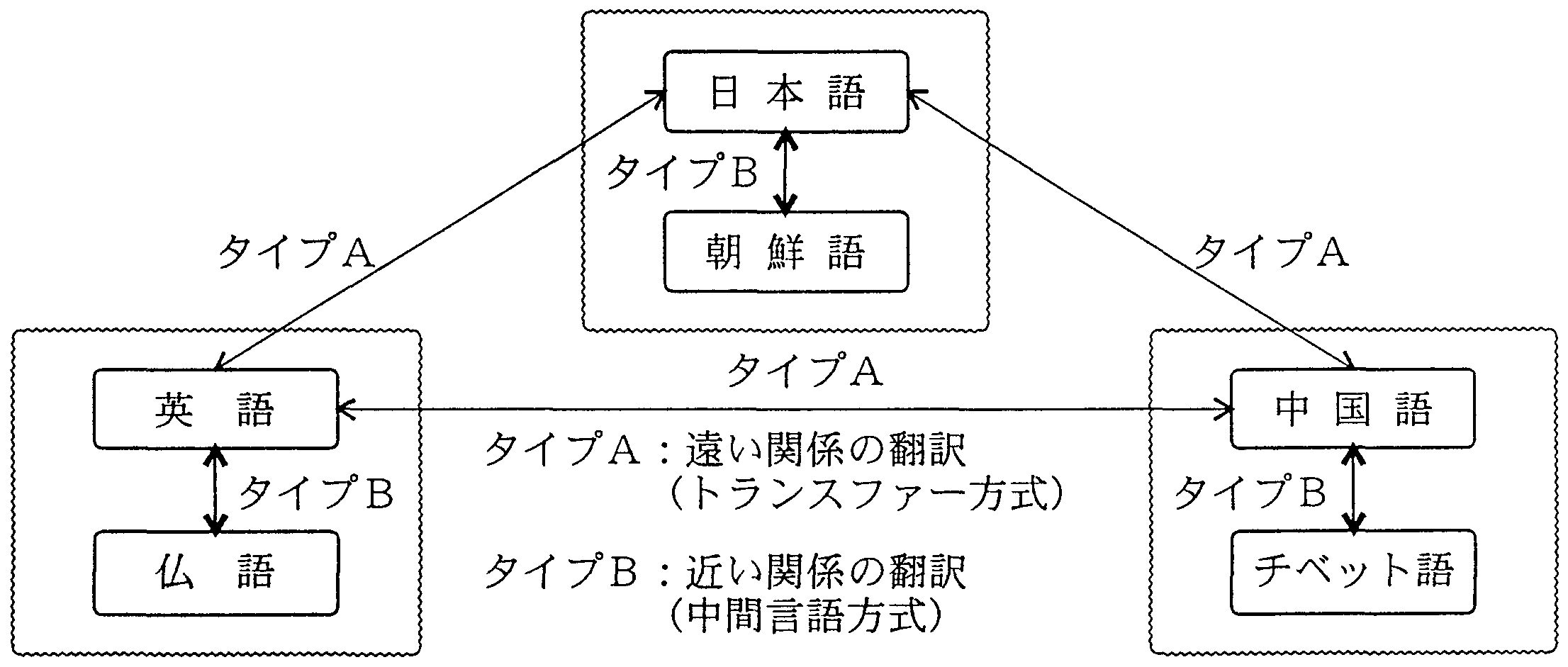
|
(1)人間による翻訳の手順
ここで、人間の翻訳家による日英翻訳を考える。 翻訳家に与えられるのは、日本語のテキストである。 このテキストには、著者の目から見た見た対象の姿と、それに対する著者の感情や意志が、 日本語の約束に従って、結び付けられている。 話者の目を通して得られた対象の姿は客体的表現によって表され、 それに対する話者の判断や意志は、主体的表現によって表される。 そこで、翻訳家は、まず、日本語の表現の枠組みを念頭において、 著者の認識とそれを通して対象の姿を追体験する。 次に、英語の世界に頭を切り替え、対象の姿とそれに対する著者の感情、 意志を英語の枠組みに中で改めて表現する。 この手順を図8に示す。 このように、人手による翻訳では、単に日本語の単語を英語の単語に置換えるのではなく、 対象と話者の関係を目的言語の枠組みの中で捉え直して表現する点に特徴がある。
|
(2)多段翻訳方式の構成概念
上記の翻訳家による翻訳手順をシミュレートしようとしたのが多段翻訳方式である。 本方式の構成概念を図9に示す。 ここで、「多段翻訳」の用語は、以下に述べるように、 原文の表現が複数の段階に抽象化され、それぞれの抽象化された段階に応じて、 目的言語の表現に変換するステップを持つことを意味している。
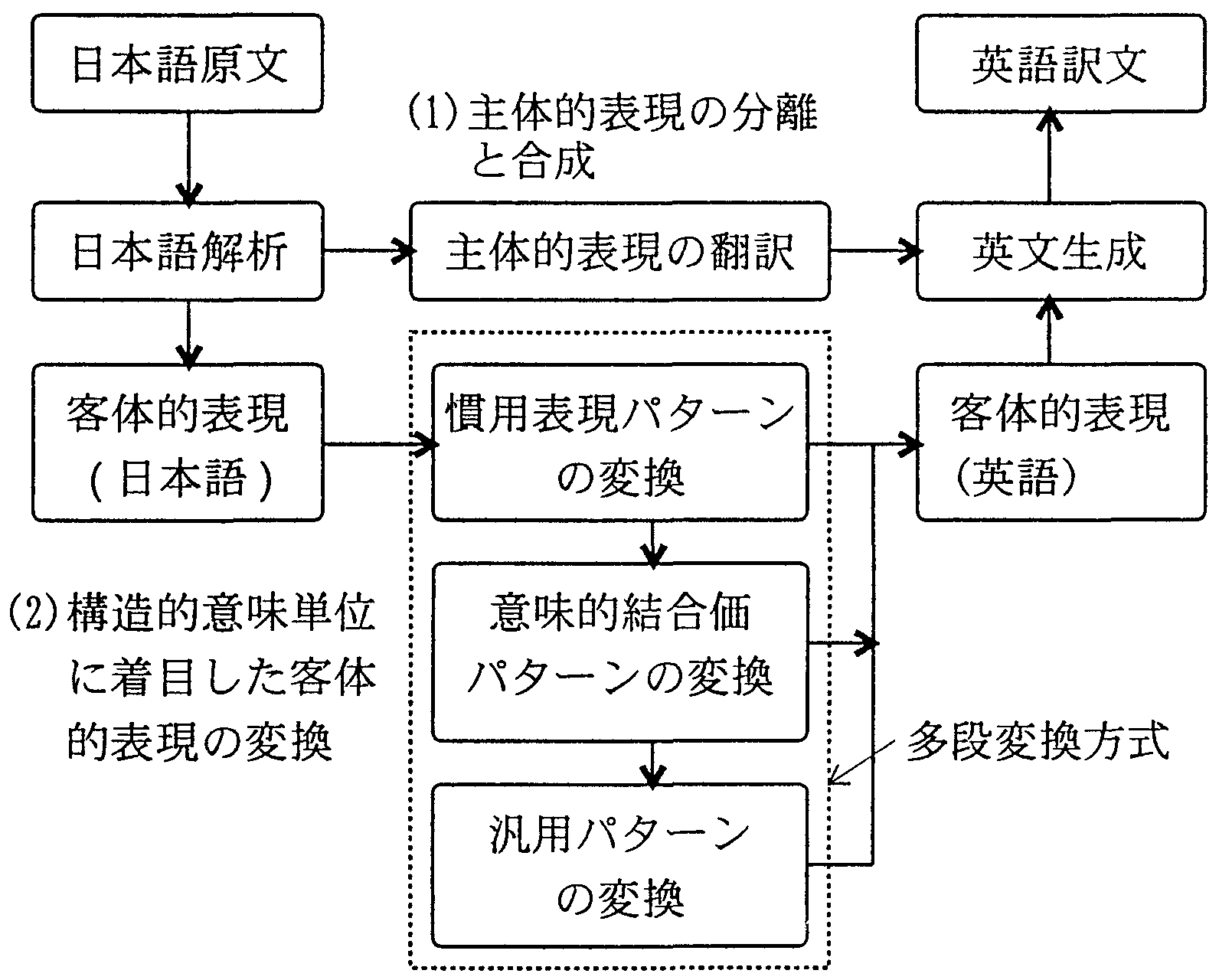
|
2.2節では、言語表現を構成する主体的表現と客体的表現の役割について述べた。 また、3.2節では、表現の構造も意味を持つことの重要性について述べた。 多段翻訳方式は、図10に示すように、これらの2つの点を設計概念としている。
図8と図9の類似性からも見て取れると思われるが、 第1のポイントは、主体的表現と客体的表現に関するものである。 日本語と英語は、主体的表現の枠組みが大きく異なっている。 そこで、本方式では、図11に示すように、 与えられた日本語表現を主体的表現と客体的表現に分離し、 主体的表現の表す内容は、客体的表現が英語に変換された後の英語に組み込むこととする。
| |||||||||||||
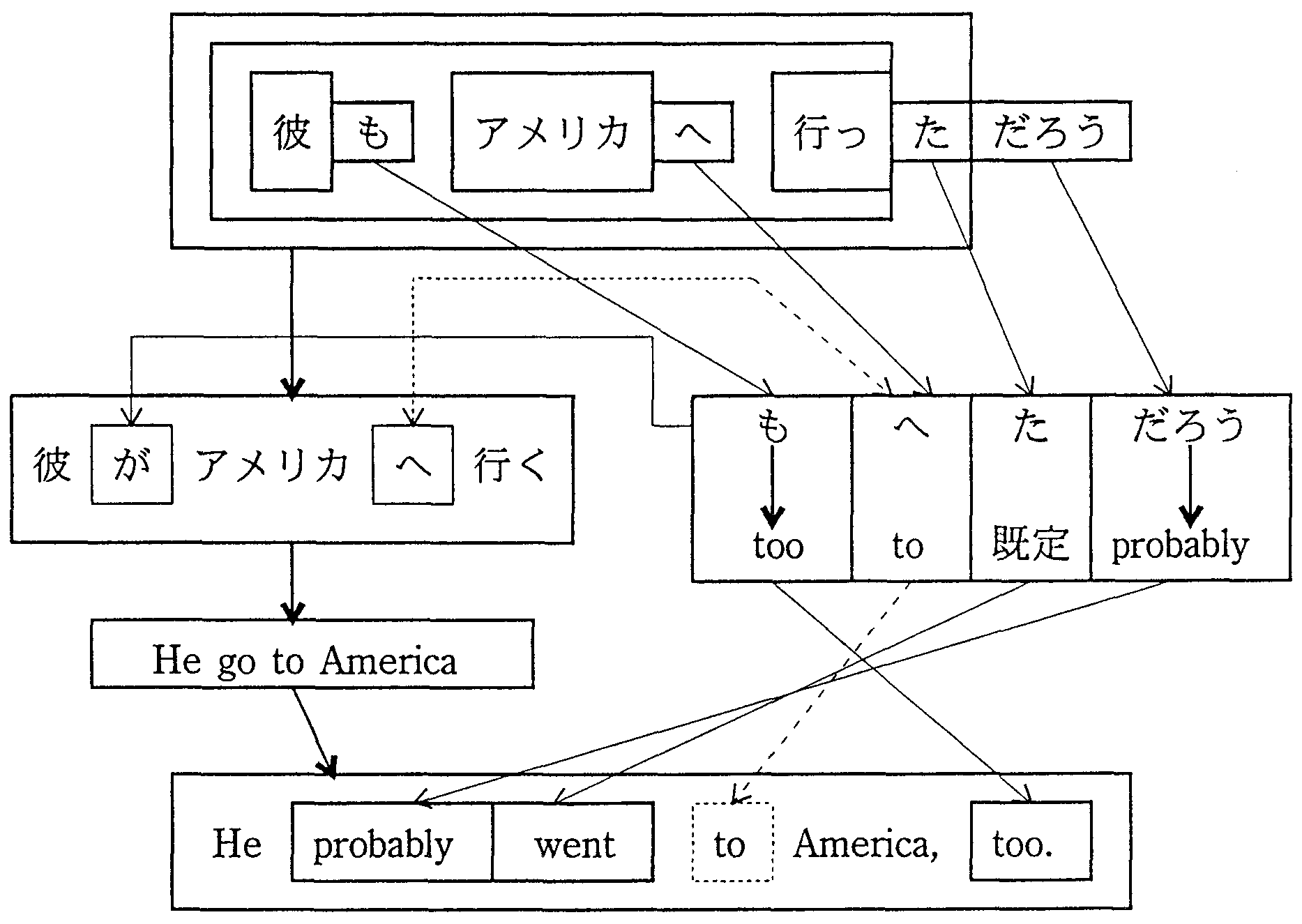
|
第2のポイントは、表現の抽象化に関するものである。 意味解析では、意味を持つ構造の単位を取り出すことの重要性を述べた。 これは、言語表現を分解して抽象化するとき、 これ以上分解しては意味を失うような表現の範囲を見つけ、それを意味の単位とすることである。 ALT-J/Eでは、このような抽象化の単位として、図12に示すように、3つの段階を設けた。
第1の段階は、慣用表現に関するものである。 特定の単語が共起することによって意味的約束の成り立つ表現がこれに相当する。 第2の段階は、ある特定の単語とあるグループに属する単語が結合することによって 意味的約束の成立するような表現である。 第3の段階は、ある特定の単語グループの単語と他の単語グループの単語が共起することによって 成立する表現である。 表現が最も抽象化されないのが第1の段階であり、最も抽象化されるのは、第3の段階である。 単語の結合の強さは、この順に弱くなる。
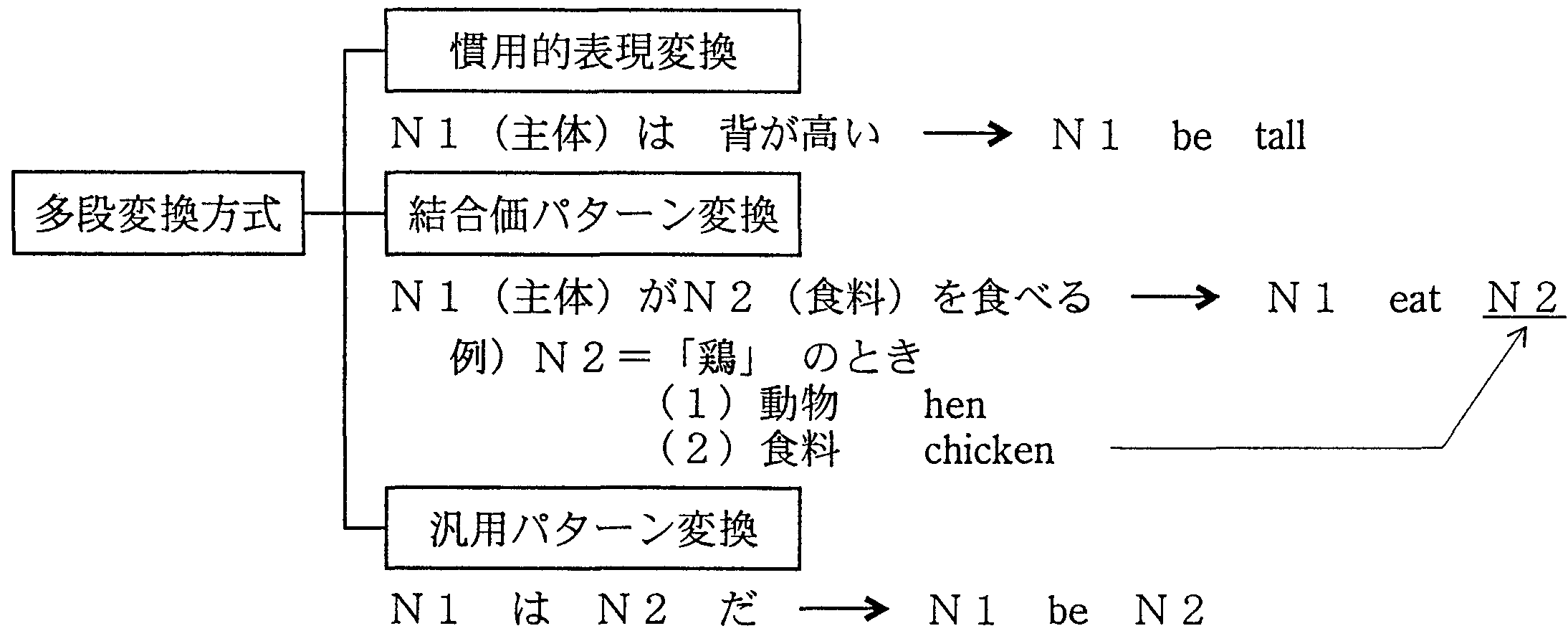
|
翻訳の精度は、具体的な表現を指定した翻訳規則を使うほど高くなると予想されるから、 翻訳規則は、第1、第2、第3の段階の順に適用される。 この方法では、第1、第2段階の翻訳規則の整備の不十分な間は、 第3段階の翻訳規則が多用されるため、全体として良い訳文品質は期待できないが、 第1、第2段階の翻訳規則が整備されるにつれて、訳文品質も向上すると予想されるため、 段階的な性能向上が期待でき、実用的である。
以上述べたように、ALT-J/Eの翻訳パスは、 主体的表現の翻訳のパスと客体的表現に関する3つのパスの合計4つのバスから構成されているが、 現在、いくつかの新しいパスを追加中である。
(3)多段翻訳方式の工学的意義
多段翻訳方式を工学的な見地から見ると、 論理的に可能であっても現実的には不可能である方式を近似的に可能とする方法であり、 一種の調和の手法だと言うことができる。 言語表現と話者の認識が言語規範で結合されることを考えれば、 最も精度良い翻訳を実現するには、あらかじめ、可能な表現のすべてについて、 対応する話者の認識をリストアップしておけばよい。 すなわち、日英機械翻訳では、すべての日本語表現について、 対応する英語表現を1対1の関係でリストアップして辞書に登録し、 翻訳実行の際は、与えられた日本語表現を辞書で検索して、対応する英語表現を出力すればよい。
論理的には可能であっても、言語表現の多様性を考えると、 この方法は、登録すべき表現の数が無限大となるため、工学的には不可能であり、 何らかの抽象化が必要である。 しかし、従来のように抽象化を推し進め、単語レベルまで分解して翻訳し、 その結果を合成したのでは、元の意味が失われるため翻訳の精度が上がらない。 すなわち、自然言語では、フレーゲの原理が成り立たないため、要素合成法の方法では限界がある。 そこで、多段翻訳方式は、表現に表された話者と対象の関係に着目すると同時に、 構造的な意味の単位という概念を導入し、まとまった意味を持つ構造の単位毎に変換する方法で、 意味の喪失と変換規則の爆発を防ぎ、この矛盾の解決を図ったと言うことになる。
このような方法は、論理学的には問題のある方法かもしれないが、 工学的な方法としては常套的なもので、なんら特異な方法ではない。
(4)多段翻訳方式における意味解析の役割
多段翻訳方式の実現において最大の問題は、意味の単位と見なせる表現の単位を取りだし、 実際の文に適用する仕組みを実現することである。 従来のシステムにおいても、慣用的な表現の扱いが重要であることが認識されており、 その収集と登録が行われているが、要素合成法を基本とする翻訳方式の枠組みでは、 慣用的なものはあくまで例外的なものとして扱われている。 すなわち、慣用的な表現は字面で辞書などに登録し、それと同じ字面の表現は、 通常の表現の翻訳に先立って例外的な約束を用いて翻訳される。 しかし、与えられた表現が慣用的な意味で使用されているか、 文字どおりの意味で使われているかは、その表現の文中での使用条件によって決まる問題である。
例えば、「私は彼の尻尾をつかむ」の「尻尾をつかむ」は、 慣用的な表現で「弱点を見いだす」の意味であるが、 「私は猫の尻尾をつかむ」では、文字通り「尻尾をつかむ」の意味である。 慣用的な表現を例外扱いするこれらのシステムでは、翻訳品質を向上させようとして、 慣用的なものを登録すればするはど、文字どおりの意味との区別がつかなくなり、 副作用が発生するため、翻訳品質の向上は望めない。
多段翻訳方式は、まさに、 このような慣用的な表現を大量に搭載したシステムを実現しようとするものであるから、 この間題を解決しなければ、方式の実現は困難である。 問題は、与えられた表現がどの意味(約束)で使用されたかを決定すること、 すなわち、すでに述べた「意味解析」技術を実現することである。
自然言語処理は、はじめから終わりまで曖昧さとの闘いともいえる。 機械翻訳でも解析の過程、変換の過程、生成の過程で、さまざまな曖昧さが現れる。 しかしこれらの曖昧さは、どれが正しいかを判定するための情報のないことが主たる原因であり、 判断に必要な情報が存在するときは曖昧さは発生しない。 従って、曖昧さを克服するには、まず、それぞれの曖昧さの種頬と性質をよく観察し、 どのような情報が欠落していることが見定めることが重要である。 欠落している情報が分かったら、それを原文中から抽出できるかどうかを調べ、 抽出できないときは、外から補うか、あらかじめシステムに持たせておくことが必要となる。 このような知識をシステムに持たせる方法としては、通常、辞書やルール集が用いられる。
従って、自然言語処理システムの処理方式は、解析規則をトップダウンで適用するか、 ボトムアップで適用するかなどの方法の違いよりも、むしろ、 処理の過程で生じる解釈の暖味さとそれを解決するための情報もしくはそれを入手する手段を どのように配置するかで決まると言ってもよいと考えられる。 この点から見れば、機械翻訳で最大の暖味さの問題は、 表現に使用された意味的約束の多義性の問題であり、 これを解決する枠組みが多段翻訳方式であった。 また、この方式を実現するに必要な技術が、「意味解析」であり、 意味的約束の多義性を解決するための言語知識が、本章で述べる日本語意味大系である。
なお、多段翻訳方式の翻訳規則を構成する点からみると、主体的表現の翻訳に関する知識は、 比較的コンパクトにまとめられるため、テーブル形式を中心とする翻訳規則として整備したが、 客体的表現の翻訳に関する知識は、大変膨大になるため、 これを日本語意味大系として整備することとした。
以下、本章では、ALTの日本語意味大系開発の背景と実現されて辞書の概要を述べる。
言語の表現対象は、図13に示すように、 実体、属性、関係の3者からなる客体の世界と話者自身を示す主体に分けられる。 ここでは客体化された主体も実体に含め、 言語の表現対象として、実体、属性、関係の3者を考える。 「関係」には、実体間の関係、属性間の関係、実体と属性の関係の3種があるが、 概念化された後は、言語表現上、実体(観念的実体)概念として扱われる。 そこで、言語表現上の対象世界の構成要素を、実体と属性の2つで捉えることにする。
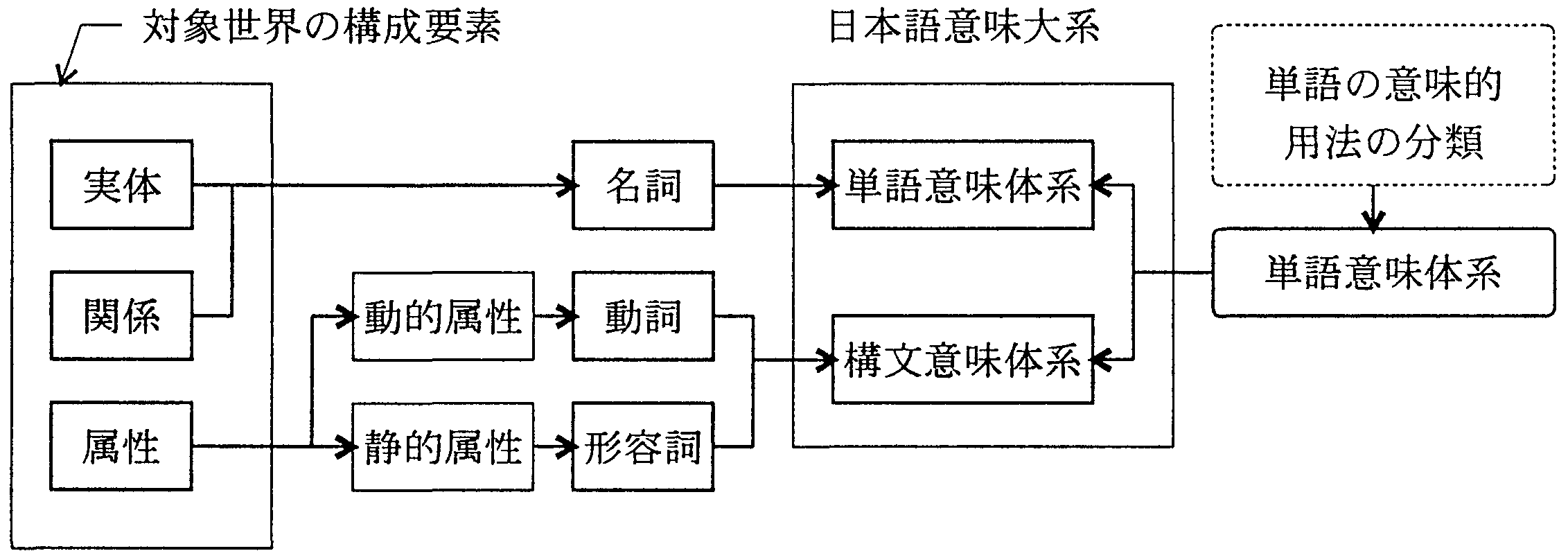
|
実体と属性の言語上の表現方法について見ると、 物理的実在であるか、仮想的存在であるかを問わず、 実体は何れも言語表現上、概念化の過程を経て名詞として表現される。 また、属性は動的なものと静的なものに分けられ、 動的な属性は動詞で、静的な属性は形容詞で表現されるが、 まとめれば言語表現上は用言に対応する。
以上から、ALT-J/Eでは、「意味解析」のための知識(言語知識)として、 名詞と用言に関する約束(用法)を体系化し、それを用いて日本語意味大系をまとめた。
(1)単語の意味的用法
従来、単語の意味(語義)を扱う方法として、 意味標識(semantic marker)、意味素(semantic primitives)、 意味素性(semantic feature)などを用いる方法が考えられている。 その違いは必ずしも明確とは言えないが、大きくみて、 単語の意味をさらに細かな要素に分ける立場と、 単語の意味を対象の持つ特徴の総体で捉える立場に分けられる。 そこで、どのような立場から単語の意味を扱うべきかについて考える。
さて、話者の認識の結果として得られた実体の概念は表現上、単語(名詞)に対応づけられる。 単語と概念の対応関係は必ずしも一対一とは限らず、 複数の概念が一つの単語に対応づけられることが多い。 通常、単語の意味と言われているものは、 このような単語と概念の対応関係に関する約束のことであり、厳密には語義と言われる。 このように単語のレベルでみると、 「意味解析」は言語表現中の単語がどのような約束(語義)で使用されたかを調べることであるが、 単語辞書に記載された語義情報だけでそれを決めることは困難であり、 現実の表現上での用法に関する知識が必要と考えられる。
そこで、概念化の過程と概念を単語に対応させる方法について考えてみると、 これらは、対象とする実体の見方、捉え方に大きく依存し、 同一の対象でも見方、捉え方によって使用される単語に違いが生じることが分かる。 例えば、妻が夫を表現するとき、夫婦の関係で見れば「夫」となり、家の関係で見れば「主人」、 恋人の関係でみれば「彼」、一人の人間と見れば「山田太郎」などとなる。 また逆に、一つの単語を一つの語義で使ったしても、その表す概念はさまざまである。 例えば、単語「学校」は「教育を受けるところ」と言う語義を持つが、 現実の表現で使われたときの用法はさまざまであり、 「学校」のどんな側面が取り上げられるかは場合によって異なる。 「ある特定の場所」を示したり、「機関」や「組織」としての側面が取り上げられたりする。
このように話者が自分の認識に対応させて取り上げた対象概念の持つさまざまな側面は、 言い換えれば、対象の見方、捉え方であり、それに対応して使用された単語から見れば、 その単語の「意味的用法」と言うことができる。
そこで、概念化された対象と単語との対応関係を、 対象の見方、捉え方に着目して分類する基準として、「単語意味属性」を考える。 「単語意味属性」は、対象を概念化する際の視点、 すなわち、単語の「意味的用法」を整理したものであり、 「単語意味体系」は、それを体系化したものである。 従来の意味標識、意味素、意味素性のいずれの考え方とも異なる。 「単語意味属性」が分かれば、その単語がどの語義で使用されたかを判断できるので、 意味解析では、重要である。
例えば、単語「東京」は「行政区画」の一つ、「駅・港」の一つ、 「地域」の一つなどとして取り上げるために使われるから、 「東京」の意味属性は「行政区画」、「駅・港」などとなる。
なお、「意味的用法」は言語規範の一部であるが、 以下では、「文法的用法」と区別して使用する。 すなわち、「文法的用法」は、表現の要素が文を構成する上で、 どのような構造的役割を持つかを表す用語として用い、 「意味的用法」は、上記で述べたように、 単語や表現が文中でどのような対象や話者の認識を表すか分類する用語として使用する。
以上の議論では、言語の部分的表現の意味は全体の表現の中で決まるのと同様、 単語の語義についても部分には分けらないあるまとまった概念を表すものと考えている。 すなわち、語義で表わされる概念は、認識の単位として一定のまとまりを持った総体であり、 意味素や意味素性のように分解されるものではない。 ある単語の語義で特定の概念が表現されたとき、 その語義の持つ概念のどの側面が取り上げられたかは、その語の用法によって決まる。 逆に、語の用法が分かれば、その語がどの語義で使用されたかも判断できると期待される。 なお、意味属性を表す言葉もやはり通常の単語(名詞)を用いて表現しているが、 通常の単語は多義性があるのに対して、意味属性を表す言葉は、一語一義で使用する。
(2)単語の意味体系
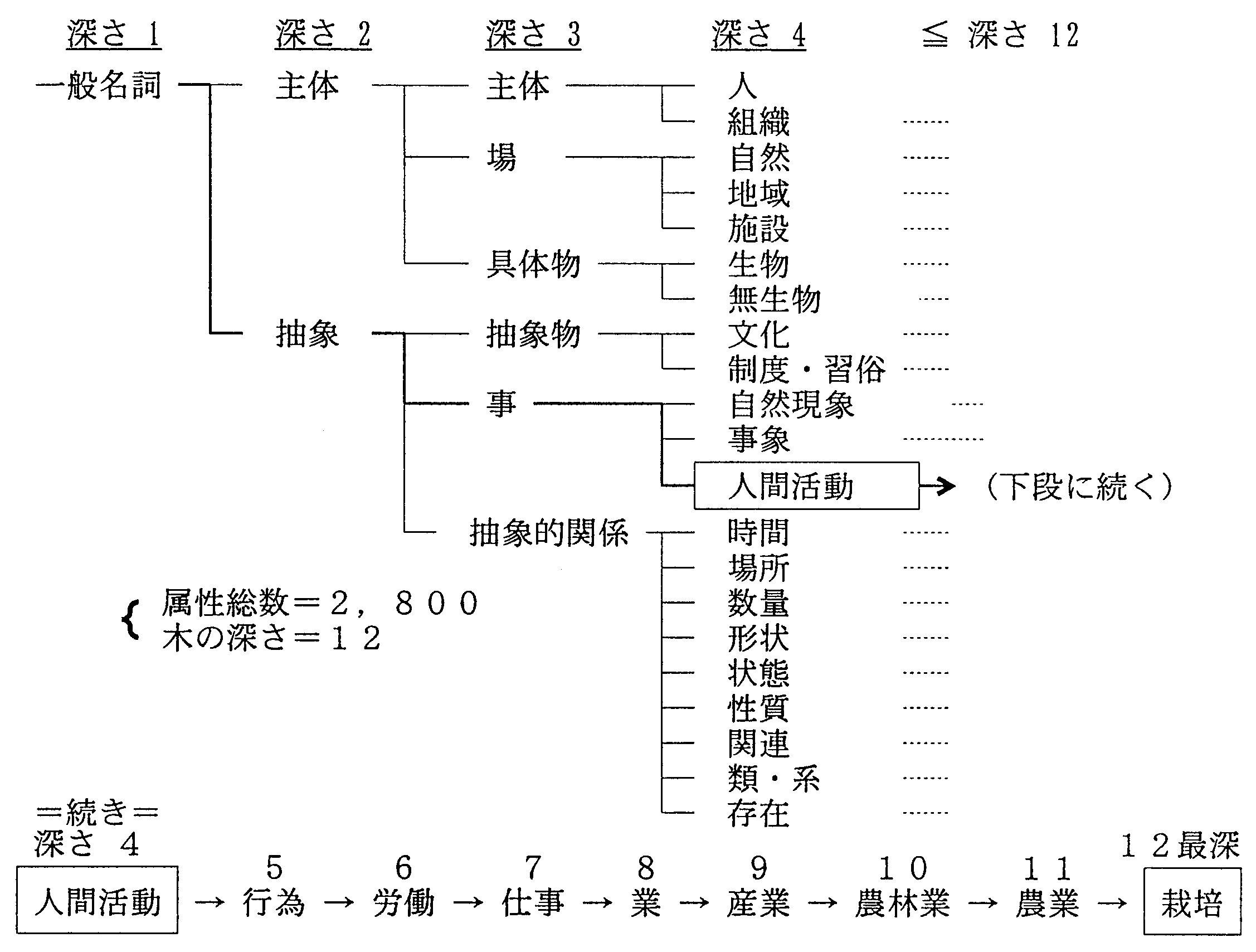
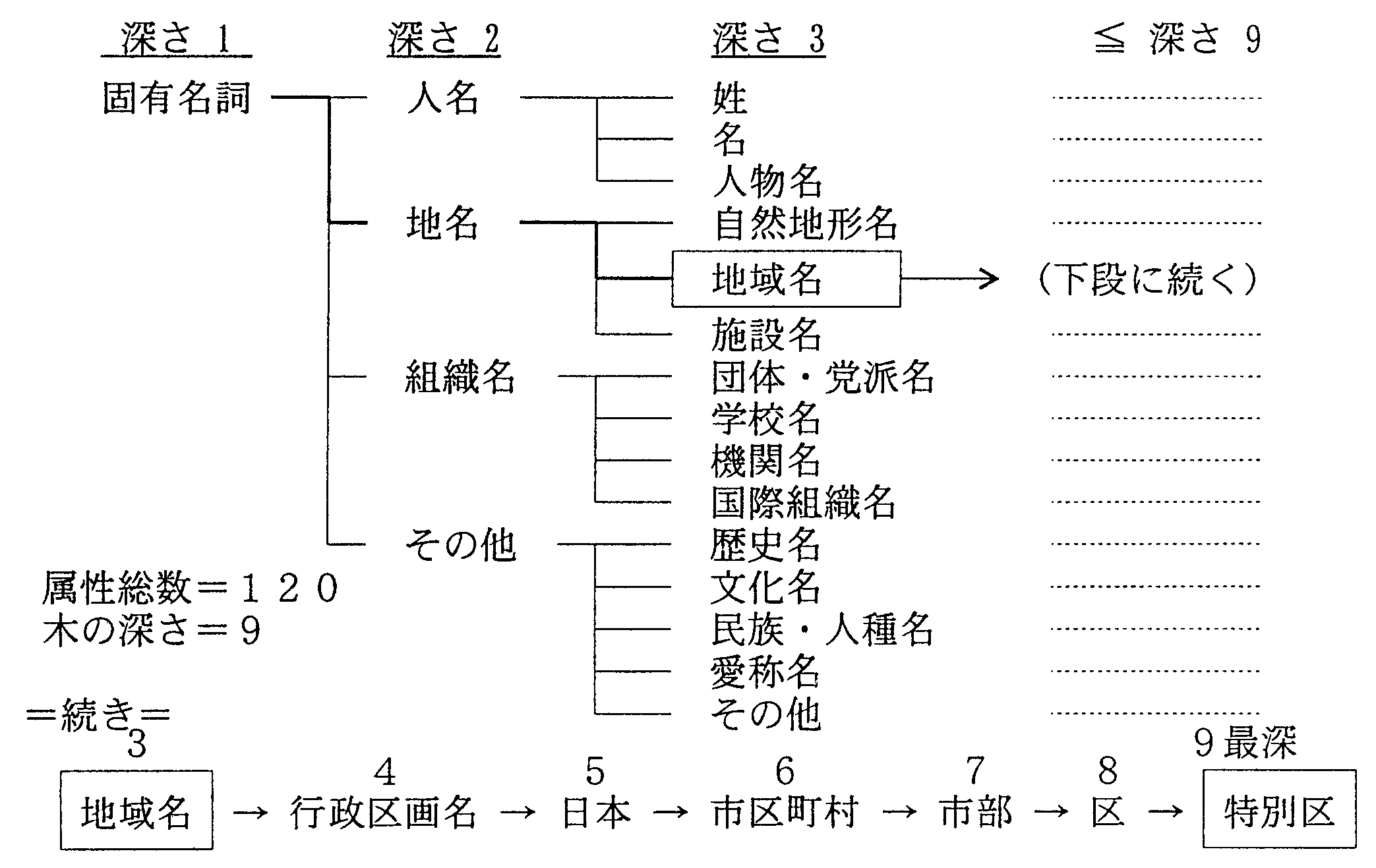
以上の考えに基づいて、下記の通り、単語意味属性を一般名詞意味属性と固有名詞意味属性、 用言意味属性に分けて、木構造の形に整理した。
| (a) | 一般名詞意味体系(12段 約2,800ノード) | |
| is-a関係、has-a関係に着目して、単語が一般名詞的に使用されるときの用法を木構造の形式にまとめたものである。単語意味体系等で、名詞全般の意味属性を記述するために使用される。 | ||
| (b) | 固有名詞意味体系(9段 約130ノード) | |
| 一般名詞意味属性のうち、固有名詞に該当する部分をより詳細化したもので、複合語解析などで使用される。 | ||
| (c) | 用言意味体系(約100ノード, 用言の意味と働き) | |
| 用言の持つ本来の意味と それが文中で使われたときの働きに着目して用法を分類したもので, 構文意味体系に登録された用言の用法の記述などで使用される。 |
|
|
固有名詞を含む複合語等の解析では、固有名詞について、 一般名詞意味体系より細かい精度の意味体系が必要になるため、 部分的に細分化した別の意味体系とした。 一般名詞意味体系が 構文意味体系とのパターンマッチを中心とする意味解析で使用されるのに対して、 固有名詞意味体系は固有名詞を含む表現(複合語=複合名詞)の解析で使用される。 用言の意味体系は、 その用言の意味を抽象化したカテゴーリを分類する観点とその用言が実際の文中に使用された時、 どのような作用もしくは機能を持つかの2つの観点から決定した。 個々の用言が使われるときの使用条件と語義の関係は構文意味体系にまとめられるので、 構文意味体系に登録された各パターン対は、原則として1つの意味を持つことになる。
一般名詞と固有名詞の意味体系の上位ノードの一部を図14、図15に示す。 一般名詞意味体系は8〜9段の付近で最も横に広がり、10段以降は収束するのに対して、 固有名詞意味体系は4段目で横の広がりが最大となるが、 そのままは収斂せず7段目以降で収斂している。 これは、「人名」、「組織名」のノードが4〜5段目で収斂するのに比べて、 「地名」のノードが深くなっているためである。
一般語12万語、固有名詞20万語、専門用語5万語、 その他3万語の合計約40万語の日本語辞書に含まれる名詞約37万語を対象に、 前述の意味属性を付与し、単語意味体系を作成した。
一般名詞には一般名詞意味属性のみを付与するのに対して、 固有名詞には一般名詞意味属性と固有名詞意味属性の双方を付与した。 これは、固有名詞も単独で格要素として使用される場合、 構文意味体系と直接パターンマッチが図れるようにするためである。
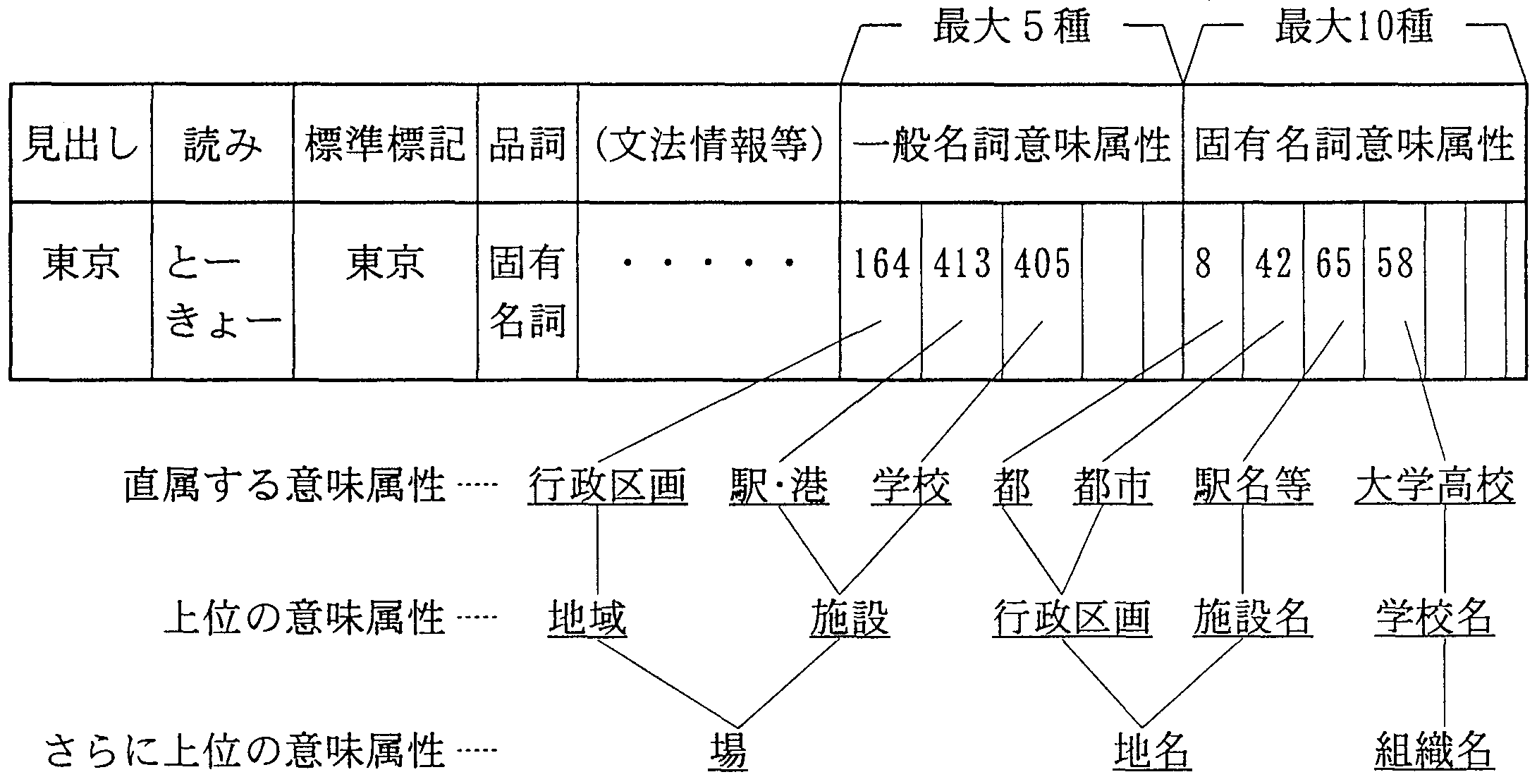
単語意味体系に登録されたレコードの例を図16に示す。 図では単語「東京」に対して、3つの一般名詞意味属性と4つの固有名詞意味属性が付与されている。
|
なお、図では、単語「東京」の固有名詞意味属性として、 「駅名」、「大学高専」などが付与されているが、これは固有名詞辞書項目として、 実在する主な駅や学校などの知識を持つことに等しい。 従って、意味解析の範囲を超えて、 「東京」+「駅」などの複合固有名詞の示す対象が実在するかどうかの判断にも使用できる。 これに対応して、固有名詞の「東京」には、一般名詞意味属性としても、 「行政区画」、「駅・港」、「学校」が付与されている。 これは、例えば、「列車は東京(駅)を出た。(leave)」、 「船は東京(港)を出た。(depart)」、 「彼は大学は東京を出た。(graduate from)」等での訳し分けに使われる。
単語当たりの意味属性の数は平均約2件である。 語数からみれば多数を占める漢語の大半が、意味属性を一つしか持たないのに対して、 和語は多数の意味属性を持つことが多く、用法が多彩であることを示している。
(1)構造化された認識の表現
5.1節で述べたように、名詞が実体概念を表現するに対して、用言は単独で実体の持つ性質、運動、 変化などの属性の概念を表すが、これらの属性は実体に付属したものであるため、 表現の上では何らかの実体概念との関係で用いられることが多く、 立体的な対象世界を一次元的な言語表現に結び付けるための枠組みを与えている。 すなわち、対象世界の持つ立体的な構造は、話者の認識過程において、 実体間の関係や実体と実体の持つ属性との関係などとして捉えられ、 言語表現上、単語間の関係として対応づけられる。 このうち、実体と属性の関係、属性を介して関連づけられる実体間の関係は、 用言を用いて構造化される。
実体と属性の関係に関する認識においても、話者の視点に沿って個別性と特殊性の捨象が行われ、 用言の種類と用法が決まる。 例えば、人がある地点間で移動する事象を「来る」と見るか、「行く」と見るかは、 話者の視点に依存する。構文意味体系では、このような実体と属性の関係の捉え方を用言の用法、 すなわち、名詞と用言の関係として整理した。
なお、用言を介さない実体と実体間の関係に関する構造的な認識についても重要であるが、 まだ、抽象化のめどが立たないので、ここでは、今後の課題としている。
(2)表現構造の持つ意味の単位化
既に述べたように、日本語の表現構造の持つ意味の単位として、 まず、最も基本と見られる用言と名詞との結合関係の構造を取り上げ、 日本語の構文意味体系として整理することとした。
用言と名詞の意味的関係を対応づける方法としては、格文法の方法があるが、 格文法では、深層構造として、深層格の存在が仮定されている。 現実には、用言と名詞の関係を、 格文法が主張するように比較的少数の意味的関係として抽象化することは困難であるので、 ここでは、結合価文法の枠組みを使用する。 結合価文法は、記述能力が高く、 用言と名詞が助詞を介して結合される関係構造が比較的自由に記述できる。
各用言に対応する格要素は、単語意味属性を使用して抽象化するが、用言自身の意味の単位、 すなわち用言の意味の分解精度としては、日英機械翻訳の立場から、 日本語の各用言に対して英語側の訳語が決まる範囲の精度で記述する方針とし、 格要素の意味属性は訳し分けのできる最小限の深さで記述する。 また、文型の抽象化レベル(一般性、個別性)に着目して、以下の2つのタイプに分けて整理する。 また、各結合価パターンには対応する英語の文型パターンを対応させ、構文意味体系に登録する。
| a) | 一般文型(一般パターン) | |
| 用言の字面をキーとする意味的結合価パターンによる表現。 用言の字面と1つ以上の格要素から規定される。 ただし、格要素は名詞と格助詞から構成されるが、 そのうち、名詞は意味属性が規定される。 | ||
| b) | 慣用文型(慣用パターン) | |
| 一つ以上の格要素が意味属性でなく、 直接名詞の字面で規定されるほかは、a)と同じ。 ただし、パターンの適用条件が格要素に対する制約条件として記述されることがある。 例えば、「怠ける(idle away one′s time)」と言う意味での「油を売る」の「油」は、 「オイル」や「石油」などの単語に置き換えることができないため、 意味属性を指定して一般化することができない。 ここでは、このように、固定的に決められる名詞要素(格要素)を1つ以上持つ文型を 慣用文型に分類している。 |
このようにして用言毎に整理された結合価パターンの体系を使用すれば、 表現構造が用言を中心とする意味単位毎に捉えられるため、構文解析上の曖昧性が減少する。 また、機械翻訳では、日本語の表現構造と対にして英語の構造を記述するため、 「意味解析」の終了した時点で、同時に英語の表現構造も決まっていることになり、 改めて変換過程を持たなくて済む利点がある。
図17に、構文意味体系の登録された動詞「掛ける」の結合価パターンの例を示す。 図では、慣用的な文型については、決め手となる格要素の種類と字面を列挙するにとどめた。 また、簡単のため主な文型を示すにとどめたが、 この動詞に関する結合価パターンは現在時点で、約90種類に上っている。
|
( )内の数字は意味属性の深さ(段数)を示す。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ALTの単語意味属性システムと他の同種のシステムの結合価パターン対の記述能力を表2で比較する。 場合1は、意味属性が30-50通りに分類されたもので、 従来の日英機械翻訳システムでの適用例である。 場合2は、約500通りの分類が試みられたもので、EDR辞書の例である。 場合3が、ALT-J/Eシステムの例である。
| 場合 | 属性名称の数 | 相当する段数 | パターン対記述能力 | 記事 | |
| 和語動詞 | 漢語動詞 | ||||
| 場合1 | 50件 | 約4段 | 31% | 59% | 従来の標準的な例 |
| 場合2 | 500件 | 約6段 | 57% | 86% | EDR辞書の当初計画 |
| 場合3 | 2,800件 | 8〜9段 | 100% | 100% | 本論文の例 |
表2は、ALT-J/Eシステムの場合の記述能力を100%と仮定したときの、 場合1、場合2の記述能力を示している。 この比較より、場合1、場合2のパターン記述能力は、それぞれ31%、59%で、 単語意味体系の分解能が低いときは、多くの重要なパターン変換規則が記述できないことが分かる。 場合2でも、和語系の用言のパターン記述能力は60%以下である。 実際の日本文では、和語系の用言は、使用頻度が高く、使用される意味も多彩であるので、 この分解能が低いことは、大きな問題である。
また、場合3では、2,800種類の意味体系を使用しているが、 パターン記述実験では、日英機械翻訳では、 名詞の単語意味属性を約2,000通り以上に分類する必要のあること、また逆に、 この程度の分類精度があれば、必要なパターン対は、ほぼ書けることが分かった。
ALT-J/Eで実現された日本語意味大系をまとめると図18のようになる。 図で示すように、ALTでは一般名詞意味体系体、固有名詞意味体系、 用言意味体系の3種類の意味体系によって日本語の意味的用法に関する知識は記述されるが、 これらの意味体系は、言語知識データベースとしての辞書だけでなく、 その他の日本語解析、翻訳規則の記述にも使用される。 そこで、 単語意味体系が言語処理用のプログラミング言語として果たす役割について指摘しておきたい。
|
一般に、プログラミング言語では、処理対象となるデータの性質を表す言葉として、 「実数」、「正数」、「文字列」などの言葉が使用されるが、 このような言葉は、そのプログラミング言語が対象とするデータの性質に依存して決められる。 それと同様、意味体系によって定義された言葉は、 日本語処理のプログラムを記述するための言葉である。
そこで、言語処理の解析技術を記述する言葉と言語知識を記述する言葉の関係を示すと 図19のようになる。 日本語解析や翻訳処理のプログラムと規則が 言語知識を記述する言葉と同一の言葉で記述されるため、 プログラムの動作中に解析規則や翻訳規則が使用されると、 自動的に言語知識ベースの情報が参照されて処理が進むことになる。
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
ALTでは、すでに、単語意味属性のほか、 文法的性質を記述する言葉として約400種の文法属性を体系化し、 日本語単語に関する文法的知識を単語辞書として整備している。 従って、日本語の単語意味体系とそれに基づく日本語意味大系の完成は、日本語処理の文法的、 意味的処理双方を記述するためのプログラミング言語が実現されたことを意味する。 従来、意味解析の研究においては、実験環境の整備が困難で、 現実の文章を対象とした実験的研究は、はとんど行われていなかったが、これにより、今後は、 機械翻訳に限らず広く日本語処理において、実用規模での様々な実験的研究が可能である。
なお、上記の議論で、文法的性質を記述する言葉で書かれた処理は、狭い意味での文法解析処理、 意味的用法を記述する言葉で書かれた処理は、意味解析処理と言うことができる。
単語意味体系と構文意味体系を用いた日英機械翻訳実験システムALT-J/Eの試作実験によって、 用言の訳し分けと、用言を介した名詞の訳し分けにおける効果が確認された。 約15,000種の結合価パターンを用いた翻訳実験では、 慣用文型として登録された表現も、それが慣用的な意味で使われているか、 それとも文字通りの意味で使われているかの判断が容易になり、副作用の問題は、ほぼ解決した。 このように、多段翻訳方式の当初の目標は、はばクリアされ、 慣用的表現や準慣用的ともいえる結合価バターンを大量に登録して行ける枠組みが完成した。 今後は、不足する表現パターンを拡充していけば、訳文品質が向上するものと期待できる。
図20に動詞「出す」訳し分けの例を示す。 また、図21にALTによって実現された意味的多義解消の例のいくつかを示す。 これらの例から、日本語意味大系の実現は、用言に限らず、 日本語の持つさまざまな意味的多義の解消に効果的であることが確認できる。
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
このほか、 日本語意味大系を用いた意味解析によって新たに実現された機能のいくつかを以下に示す。 これらの項目は、従来、前編集や後編集の対象項目と考えられていたが、 試作実験の結果、自動化が大幅に進む見通しとなった。
| (a) | 日本語自動書き替え型翻訳機能 |
| 英語に直接対応する表現がなくて直訳できない表現や 直訳できても英語としてみれば不適切な表現となる日本語表現を、 翻訳し易い日本語表現に自動的に書き替えて翻訳する。 例えば、「彼はバスに乗って学校へ行った。」は、 動詞の数を減らすよう「彼はバスで学校へ行った。」に書き替えて、 "He went to school by bus." と訳す。 このような替え用の規則の適用条件が精密に書けるようになり、 副作用の心配が減少したため、効果的な書き替えが可能となった。 | |
| (b) | 複合語翻訳機能 |
| 複合語(名詞連続型)には一般名詞を結合したもの、接頭、接尾辞を持つもの、 サ変名詞を含むもの、固有名詞を含むものなどがあり、その構造は多彩である。 単語意味体系はこれらの複合語を構成する単語間の意味的な関係の解析において、 大きな役割を持つことが分かった。 また、サ変名詞などの用言性名詞を含む複合語では、他の名詞が格要素となる場合が多く、 その解析においては構文意味体系が有効である。 例えば、「イラスト入りカード」、「豆入りご飯」、 「ミルク入りコーヒー」などにおける「入り」は動詞「入る」の格要素の関係から、 それぞれ、 "illustrated card"、"beans in nee"、 "coffee with milk"などと訳す。 | |
| (c) | 文脈処理による文要素補完型翻訳機能 |
| 日本語では、主語、目的語といえども、 聞き手の知っていることは極力省略する傾向があるのに対して、 英語では、主語、目的語は省略しない。 このため、主語の省略された文は受け身に訳すことなどが行われていたが、 受け身への翻訳では、文中での話の流れが変わり、読み辛いだけでなく、 文自体の意味も変わってしまうことがあり、問題となっていた。 これに対して、用言意味属性の付与された結合価パターン対を用いると、 複数の文間の意味的関係を追跡することが容易になり、 省略された格要素を前後の文から補完することができるようになった。 | |
| (d) | 決定詞、数の表現生成 |
| 日本語では、英語の冠詞(a, the)や所有格などの示す個別性と単位観に関する 認識に大きな違いがあり、決定詞や数の表現の生成が大きな問題であったが、 単語意味体系を用いて名詞単独で持つ個別性と単位観から名詞句としての個別性と 単位観を決定することにより、のこの問題はおおよそ解決した。 | |
| (e) | 広域変換機能 |
| 本論文で述べた多段翻訳方式の4段階の変換パスは、 一用言の支配する範囲を対象とするものであったが、これに5段目のパスを加え、 複文、重文など、複数の用言を持つ文構造まで拡大しようとした機能で、 表現の意味をより大きな単位で捉えることを狙ったものである。 例えば、「私は歩いて学校へ行った。」では、「歩く」と「行く」を組み合わせて、 I walked to school. などのように翻訳する。 また、「私は鳥取に来て半年になる。」は現在完了とし、 "I have lived in Tottori for a half of a year." などと訳す。 |
機械翻訳の研究においては、各単語がどんな意味(約束)で使われているか、 慣用的な意味と文字通りの意味をどのように区別するか、主語(主題)の無い文や、 複数ある文をどんな文型で訳したら良いか、などが大きな問題である。 特に、良く使われる言葉や表現ほど多くの意味を持つ傾向があるため、 訳し分けの問題は、大変重要である。 これに対して、従来の計算言語学の成果はこのような現実の問題には、 ほとんど無力であったと言える。 自然言語を社会的慣習として自然発生的に成長してきた手段であるから、 一語一語に異なる歴史があり、それを背景とした文法的、意味的な使われ方ある。 その約束を発見し知識として整理することができなければ自然言語処理の実現は困難である。 言語処理規則を適用するアルゴリズムも大切であるが、規則そのもの方がもっと大切である。 アルゴリズムや言語モデルに合わせて知識を集めるのではなくて、 知識に合わせてアルゴリズムを考えるのが順序であろう。 このような考えから、本論文では、従来の計算言語学の問題点を指摘し、 新しい機械翻訳方式としての多段翻訳方式の意義を述べた。
多段翻訳方式は思想的には言語過程説を背景に提案した方法で、 話者を意識した主体的表現の扱いと表現構造の意味の扱いに特徴がある。 技術的には、本方式は言語知識をベースとする意味解析技術に支えられている。 意味解析のための言語知識として40万語の単語意味体系と1.5万文型の構文意味体系を作成したが、 これらは約400種の文法的属性と約3,000種の意味的属性の体系で書かれている。 同じ単語意味体系で日本語解析規則や翻訳規則を書けば、 これらの言語知識が動員されて翻訳が実行される構造となっているため、 単語意味属性は言語処理プログラミング言語としての役割をも合わせて持つ。
このように、単語意味体系と日本語意味大系の実現によって、 様々な意味解析が実現できるようになったので、 今後は、名詞句と複合語の意味解析、長文翻訳における大域的英語表現の生成技術、 名詞の意味による訳し分け、副詞的表現の翻訳などの問題について、 より精度よい処理を実現していきたい。 特に、名詞の意味の扱いをより精度よく行うには、 本論文で示した単語意味体系では不十分であることが分かったので、 今後は、多次元シソーラスや類語弁別ネットワークの試みを行う予定である。 また、意味解析の限界を越えるため、話者の視点解析,認識構造のモデル化、 世界知識の導入など、意味理解の基本的枠組みについても研究を進めたい。