| 1 はじめに | |
| 2 処理概要 | |
| 2.1 骨格構造捕捉処理 | |
| 2.2 英語合成処理 | |
| 3 実行例 | |
| 4 おわりに | |
| 参考文献 |
従来、ルールベースの機械翻訳システムは形態素・構文解析、意味解析、変換、 生成の各フェーズを経るトランスファー方式を基本に実現されてきた。 しかし、翻訳結果を得るという目的に限れば、深い解祈が必要のない場合も多いことが 指摘されている[1][2][3][4]。 我々も、 多段翻訳の考え[1]に基づいてトランスファー方式を発展的に見直し、 慣用表現,機能動詞結合など、意味解析型翻訳[5]の拡張を進めてきた。 しかし、使用頻度の高い「なる」「する」などの一部の和語動詞や、 仮定法などの英語の特殊な表現に対応する日本語を翻訳する場合には、 その表層条件が構文木上に散在しているため、 従来の結合価をもとにした解析・変換では十分に取り扱うことができなかった。
現在我々は、グローバルな条件を取り扱うために、 任意の日本語構文木を直接翻訳する機能(広域直接翻訳)の 日英翻訳システムALT-J/E[1]への組み込みを進めている。 散在している条件を参照するには、 構文木上の任意の要素を参照できるルール照応機能が必要である。 また、意味解析のためには構文木を名詞句などの単位に分割する必要があるが、 このルールはその分割前に適用されなくてはならない。 そのため、意味解析を行なわない構文木への直接ルール照応を導入する。
広域直接翻訳の照応機能は木と木のパタンマッチであり、 この機能のみでも翻訳実験システムを構築することは可能であるが、 実用的な翻訳システムに採用するには以下の点で不利である。
上記は従来の意味解析型翻訳の利点の裏返しである。 両者の利点を組み合わせるために、広域直接翻訳は構文木上の長距離依存関係を含むなど、 意味解析型翻訳の能力を超える表現を主に扱う。 これらの表現を文の骨格構造と呼ぶ。 対して、意味解析型翻訳は葉の部分の翻訳を担当する。 この場合、どのように両者に親和性を持たせるかが問題となる。 本稿では、従来の意味解析型翻訳と広域直接翻訳の融合方法の実現について報吉する。
広域直接翻訳処理の目的は、英語表現に対応する日本語の構造の捕捉である。 捕捉すべき範囲が単一の句や節とは限らないため、柔軟なルール記述ができることが必要である。 本処理では、木構造表現されたルールを用い、係り受け本溝造との照応を行なう。
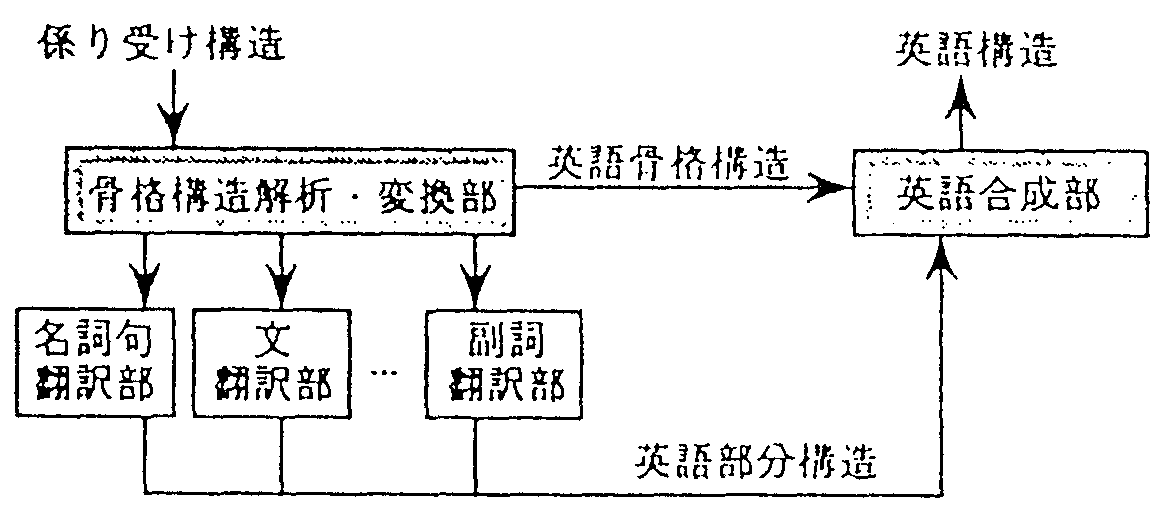
処理構成の概略を図1に示す。
|
|
係り受け解析された日本文は、「骨格構造解析・変換部」でルールと照応され、 骨格溝造と部分横造に分割される。 骨格構造に対しては直接英文構造が出力され、部分構造は、 その種類に応して従来の翻訳処理が実行される。英語合成部で両者を合成し、訳文とする。
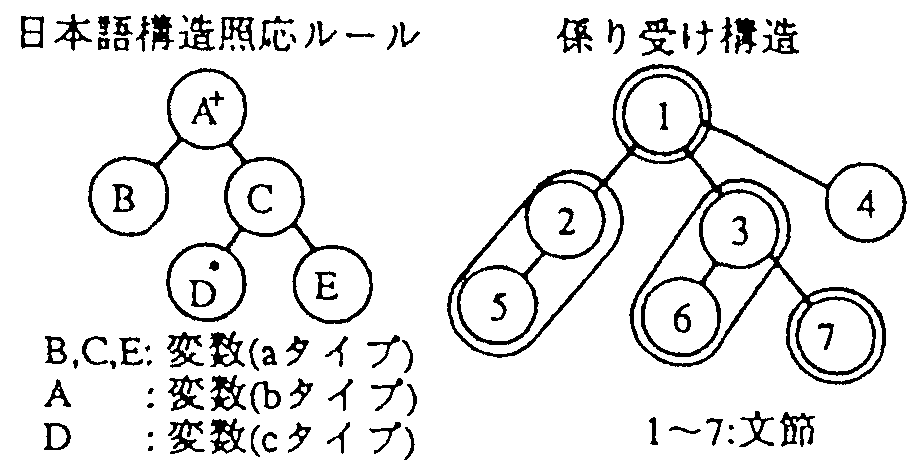
係り受け関係は、各ノードに文節がある本構造として表現できる。 これと照応できるように、各ノードに変数を持つルールを用意する。 変数の値は係り受け木構造の一部分である。各ルールはそれぞれが英文生成規則を持つ。
変数には3種類ある。
(a) 英語に翻訳される変数
(b) 英語に翻訳されない変数
(c) ノードの上位変数に組み込まれる変数
(a),(b)変数に対応した文節は、それぞれの変数の値となる。 (c)に対応した文節とどの変数にも対応しなかった文節は以下のように扱われる。
自由要素はそれが副詞要素であり、かつ、 英語構造が文である場合には文修飾の副詞として扱うが、それ以外では、 このルールの適用は行なわれない。
例えば、図2の例では、A=1, B=2+5, C=3+6, E=7 となり、 4は自由要素である。
|
(a)の変数には名詞句、文などの型が指定されてあり、 それぞれの型に応じて、従来の翻訳処理で翻択される。
英文生成規則には、英語の骨格構造と変数の接続方法が記述されており、 従来翻訳の結果が埋め込まれる。 接続規則には、変数の役割と変形規則を記載し、必要に応じて品詞変換を行なう。
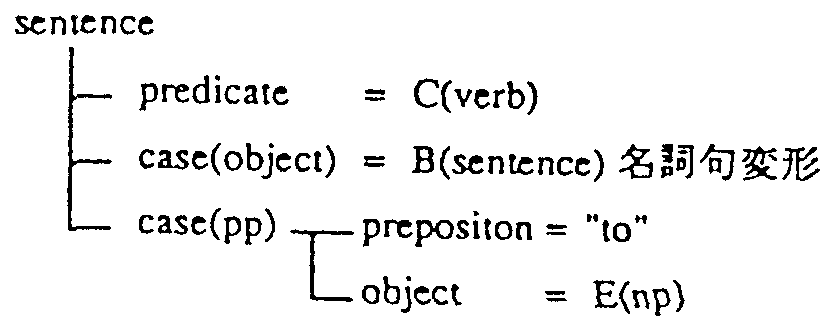
|
本処理を、「〜はまるで〜かのように話す」の翻訳に適用する場合を考える。 仮定法のような英語の特殊な構造に対応づけるべき日本語の表現は、 従来のような直訳的手法では扱えず、 「まるで」や「あたかも」のように文構造上の中心部分(主動詞や必須格)以外にある情報を 手がかりにする必要がある。 この例では「まるで」と「かのように」に着目して図4,5のようなルールが記述できる。
| ||||||||||||
| |||||||||||||||
例文
(1) 彼の父はまるで何でも知っているかのように早口で話す。
を翻訳した場合、各変数は
| B | = | 彼の父 | |
| C | = | 何でも知っている | |
| 自由要素 | = | 早口で |
となり、それぞれの変数が従来方式で訳され、
| B | = | his father | |
| C | = | know everything | |
| 自由要素 | = | fast |
以下の訳文が得られる。
(2) His father talks fast as if he knew everything.
日英機械翻訳機能試験文[6]から、 動詞「なる」を含む文を抽出し、適用可能性の机上検討を行なった。 3300文中「なる」を含む文は146文あり、そのうち、 現在ALT-J/Eで合格訳文1が得られるのは 約60文である。 残りの約85文のうち、40文ほど(例えば下例)が本処理で取り扱える見込みである。
| 原文 | : | 今月になってから | |
| 人手訳 | : | since the beginning of this month |
日本語構文木からの直接翻訳と意味解析型翻訳を融合させた翻訳処理について報告した。 現在、本方式のプロトタイプを評価中であり、 今後、方式の機能拡充及びルールの収集を進める予定である。