| + | NTT情報通信網研究所知識処理研究部 |
| ++ | 新潟大学工学部情報工学科 |
| 1. まえがき | |
| 2. 従来の翻訳方式の問題点 | |
| 3. 多段翻訳方式の基本的考え方 | |
| 4. 意味処理の考え方 | |
| 5. あとがき |
既に多段翻訳方式を提案し、日英機械翻訳実験システムALT−J/Eを試作したが、 ここで、言語過程説を自然言語処理に応用する立場から、 本システムが言語の基本的な問題をどう捉えているか、について論じ、 今後の言語処理の方向について触れる。
(1)要素合成法の問題
従来の機械翻訳の問題点は前編集の必要性とその内容、などに端的に現れている。 すなわち、一つの単語は一つの意味でしか使用しないこと、 多義の生じ易い助詞、助動詞などは使用法を一通りに制限すること、 省略された単語はあらかじめ補うこと、慣用的な表現は一般の表現に書き換えることなど、 単語対単語の逐次翻訳の限界を越える現象の問題である。
この問題を理論的側面から見ると、要素合成法の原則と関係していると考えられる。 要素合成法は「表現全体の意味は表現の部分の意味の和である」ことを仮定するものであり、 計算言語学の原則と言えるもので、計算言語学をペースとする現在の機械翻訳の 単語対単語の逐次訳の技術を支える理論的背景とも言える。 しかし、このような便利な原則は自然言語では成り立たないものであり、 成り立たないことを承知しながら、捨てられないところに現在の計算言語学の問題がある。
(2)深層構造の問題
従来、生成文法の深層構造を信じる立場から、 英語、日本語等の言語に共通する意味言語(中間言語)なるものの存在を仮定した 翻訳方式の追求が行われてきた。 しかし、言語過程説の立場に立てば、異なる言語間で共通するのは「対象」だけであり、 言語間において対象の見方、捉え方が異なる以上、「認識」以降は言語によって異なることになる。 「対象」でもなく、また「認識」でもない「深層構造」の存在は否定される。 この点から、深層構造を仮定した従来の翻訳方式は見直されるべきであろう。
(1)話者認識の表現の扱い
対象に対する話者の認識を考える際、言語表現の枠組みの中で、 対象と話者の認識の関係が最も特徴的に現れるところが、 主体的表現と客体的表現の遅いであると考えられる。 また、日英両言語を考えた際、主体的表現の表現方法は両言語で大きく異なるため、 主体的表現と客体的表現が混在したまま両言語を対応づけるのは容易ではない。 したがって、機械翻訳においては両表現を分離し、 それぞれに適した方法で目的言語に対応づけることが適当と考えられる。
(2)表現構造と意味の関係
対象とそれに対する認識は立体的な構造を持ち、 その構造は表現の構造に対応づけられることによって聞き手の理解が図られる。 表現の意味が、表現に結び付けられた対象と認識の関係であると考えると、 これらの構造も意味を構成する要素であり、 表現の構造と意味を分けて捉えるのは適切でないことになる。
しかし、機械翻訳において、 すべての表現を分解不能の意味の単位として捉えることは工学的に不可能である。 多段翻訳方式では、この矛盾を調和させる仕組みとして、 表現構造の段階的な抽象化を提案している。 意味のまとまる構造の単位を見いだして、 言語の約束をその単位毎に言語知識として整理していく方法である。 このような知識を言語対毎に用意すれば、言語間の変換時に生じる曖昧性だけでなく、 言語解析上の曖昧性の解消にも極めて有効と考えられる。
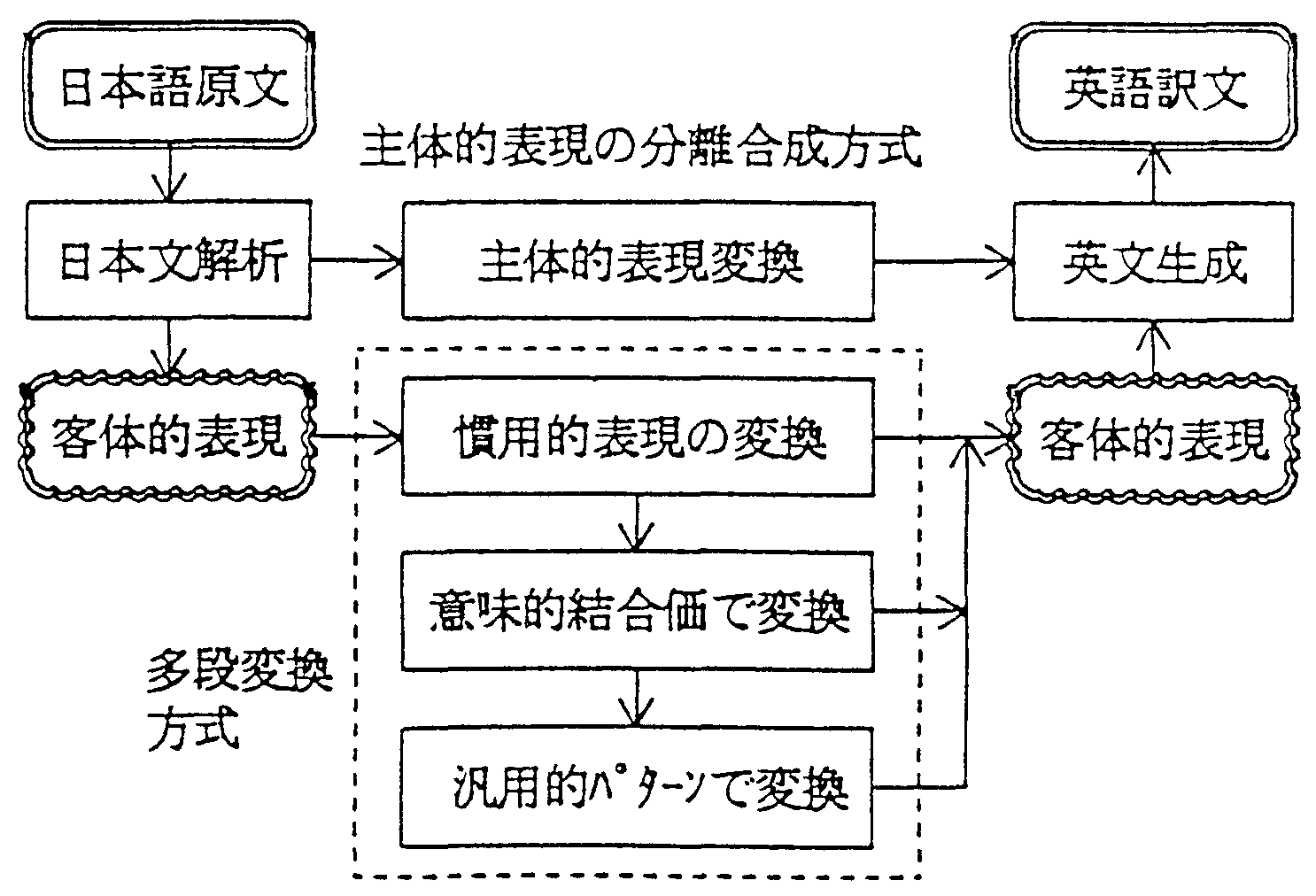
(3)多段翻訳の方式構成
以上の考察に基づき、ALT−J/Eでは図1の多段翻訳方式を提案した。 現在のところ、この方式は4つの変換パスから構成される。 すなわち、日本語から英語への変換に主体的表現に対する一つのパスと 客体的表現に対する三つのパスの合わせて四つの変換パスである。 パスの数は表現構造の抽象化のレベル数に依存して決まるものであり、 研究の進展に応じてパスを増やしていく予定である。
|
|
(1)知識とアルゴリズム
自然言語処理は、初めから終わりまで曖昧性との戦いと言っても過言ではない。 前述の前編集は曖昧性から逃れる手段でもある。 処理上生じるこれらの曖昧性の主たる原因は、知識の欠如である。 判断に必要な知識の欠如が曖昧性を生むのであり、 アルゴリズムの工夫だけで解決するものではない。 曖昧性の種類とその解決に必要な知識の種類との関係を見定めて、収集整理することが必要である。
(2)意味処理のための知識
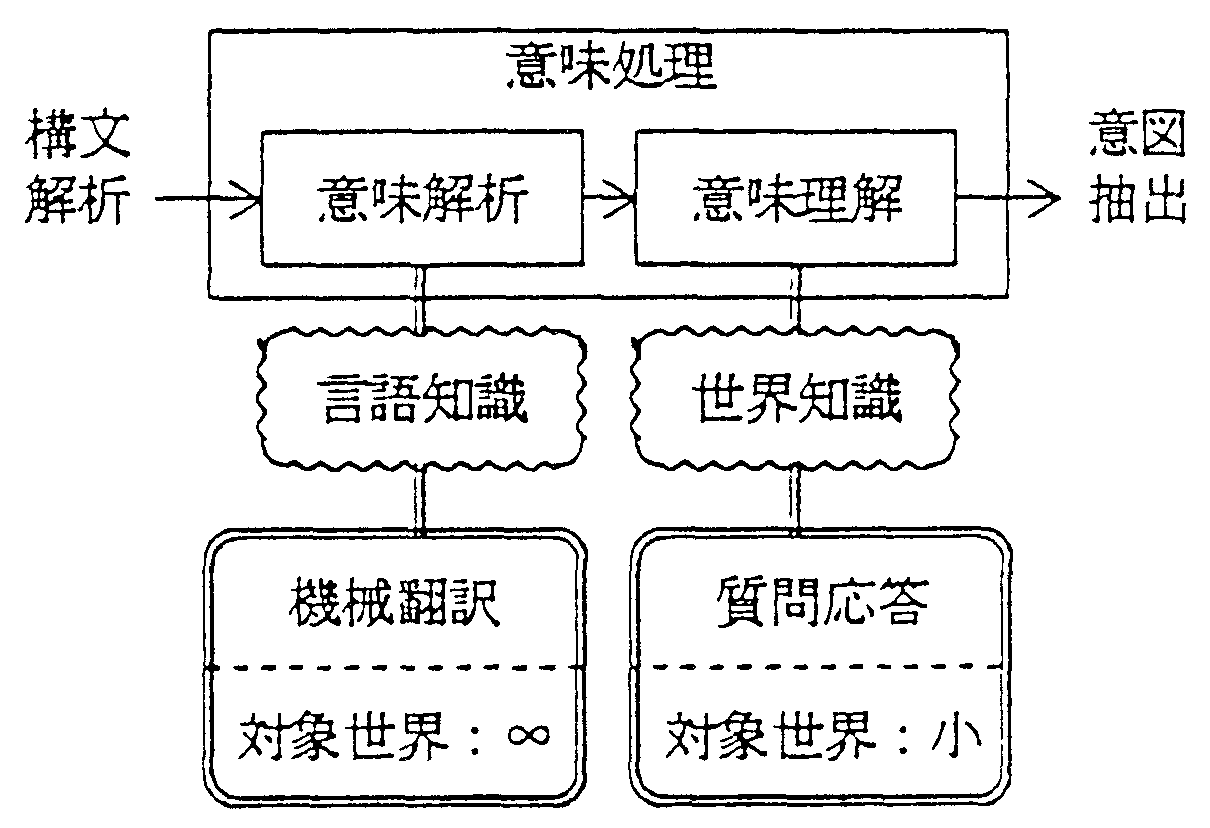
従来、意味の定義無しに意味処理を論じる研究が多い。 意味の定義無くして意味処理は科学と言えるだろうか。 ここでは、表現に結び付けられた対象と認識の関係を言語表現の意味とする立場から、 意味処理を意味解析と意味理解に分ける。 意味解析は表現に使用された言語上の約束を特定する処理であり、 意味理解とは表現に結合された話者の認識を 聞き手の認識の中(計算機上)に再構成する処理である。 意味解析は言語知識(言語に関する約束)をベースとする処理であるのに対して、 意味理解では世界知識(一般知識や専門知識)を必要とする。
機械翻訳では対象とする文書の内容を限定するのは困難なため、 意味理解に基づく翻訳の実現は困難であるが、 翻訳結果を見るのは目的言語の分かる人間であることを考えれば、 意味解析でもかなり役に立つ翻訳が実現できる可能性があると考えられる。 日本語表現に使用された約束を特定し、それを英語の約束に対応づけて英語表現を生成し、 内容の理解はそれを読む人に任せる考え方である。 ALT−J/Eはこのような考え方から、意味解析をベースに機械翻訳を実現している。
|
(3)言語知識の体系化
言語知識を大別すると、主体的表現に関する約束と客体的表現に関する約束になる。 両者の規模を考えると、前者は比較的量が少ないため、 プログラム内のテーブルとしてまとめることとしたが、 後者は規模が大きいため、辞書として体系化することとした。
さて、客体的表現として表現される対象世界を考えると、 対象世界は実体、属性、関係の3種である。 (話者自身は対象化されると実体として表現される。) このうち実体と関係は言語表現上、名詞として表現されるのに対して、 属性は主として用言によって表現される。 そこで、言語知識としては名詞の意味的用法に関する知識を単語意味辞書、 用言の意味的用法を構文意味辞書として整理することとした。 用言の意味的用法を単なる用言意味属性辞書とせず、構文意味辞書とした理由は、 属性が実体のある側面を表現するものであり、 実体との関係において意味と用法が定まるものであるためである。
(4)単語の意味属性体系
実体を対象として概念化して表現するとき、捉え方によって、 対象の持つ種々の側面が捨象され話者の見方に応じた側面から使用する名詞が選ばれる。 対象の概念化においては、対象の持つ特殊性と個別性が捨象されており、 対象の持つ特性か一つのまとまりとして認識される。 意味素性の考え方の中には、還元論的な立場から、名詞の持つ意味を、 より細かい意味の単位の束として説明する試みもある。 しかし、名詞の表すこのような概念は認識のまとまった一つの単位であるから、 これ以上分解できない単位として扱うことにし、 概念化の視点(用法)を意味カテゴリーによって分類する。
このような考えで体系化された約3,000種の意味属性と 約100種(詳細は500種)の文法属性によって、 40万語の単語意味辞書と1.5万文型の構文意味辞書を記述した。 従って、同じ属性体系を使用して解析や変換のルールを書けば これらの知識が動員されて対訳が実行される構造となっている。
以上述べたように、多段翻訳方式は思想的には言語過程説を背景に提案した方法で、 話者を意識した主体的表現の扱いと表現構造の意味を考えた点に特徴がある。 また、技術的には、本方式は言語知識をベースとする意味解析技術に支えられているが、 このレベルの技術ではやはり限界(翻訳率約80%程度)があると判断され、 この限界を超えるためには、 一般知識や対象分野知事を背景とする意味理解の技術への拡張が必要と考えられる。 しかし、一般的対象に対して意味理解を実現するのは困難であるので、 意味解析の限界点を見きわめた上で、 常識や世界知識を援用した意味理解の研究を進めることも必要である。 また、訳文の品質を高めるためには、話者の認識により接近する必要があり、 そのためにはさらに、意味属性の多次元化や話者の視点移動の解析、 話者認識の構造化等に取り組むことも必要である。