| 1. はじめに | |
| 2. 本システムの目標 | |
| 2.1 人手に代わる実用システムをねらう | |
| 2.2 新聞記事を対象とする。 | |
| 3 システムのあらまし | |
| 3.1 基本方式の検討 | |
| 3.2 システム構成 | |
| 4. 名詞抽出法 | |
| 5. 処理の高速化 | |
| 6. システムによる検証 | |
| 7. むすび | |
| 謝辞 | |
| [参考文献] |
データベースは,大量の情報の中から必要な情報を必要な時に取り出すことのできる手段として, 社会・経済活動,学術研究,国民生活の発展・向上を図るためにますます重要となってきている。 利用者がこのような文献情報の中から希望する文献を検索するためには, 文献の内容をあらわしたキーワードを索引語としてもちいる方法が有効である。 従来は,インデクサと呼ばれる専門家が,膨大な時間と労力を費やし, 文中からキーワードを抽出するという作業をおこなっていた。 (たとえば,新聞記事データ・ベースの場合, 新聞の発行からオンライン検索が可能となるまで,約1週間かかるといわれている)。 また,抽出されるキーワードには,作業者の主観が入り,均一な品質を保つことが困難であった。
筆者らは,このような問題を解決するため,日本文の新聞記事を対象として, 与えられた文章からキーワードを抽出する索引語自動生成システムを試作した。
従来,索引語自動生成の研究は英文を中心に古くから進められ, 欧米ではすでに実用システムが稼動している[1]。 一方,日本文に関しては,字種が多く分かち書きされないなどの問題があり, 分野を特定した論文の表題や,特許請求範囲文などの特殊な文章を対象とした実験的なものが ほとんどであった[2]。
本システムでは,従来の人手による作業の中で蓄積された選択基準の知識を生かすため シソーラスなどのキーワード辞書をもちいた統制キーワード方式を採用した。 また.新しくキーワード抽出に適した高速名詞抽出法,接辞処理による未知語のカテゴリ推定, 高速辞書インデクスアクセス法などを提案することにより, 実用レベルのシステムを実現することができた。
本システムにより,従来の人手による手法で問題とされてきた, 索引生成作業の経済性,即時性およびキーワードの均質性などの問題が解消できる。 ここでは,機械的処理だけでは不十分な点については,人手による後作業で補うようにしている。 このように,現段階では専門家の援助をするシステムという色彩が強いが, 十分実用に耐えることが確かめられている。
抽出されたキーワードの適否については, 実際に抽出されたキーワードをもちいてデータべースを構築し, 実際に検索してみて希望する文献が検索できたかどうかによって評価するのが適切である。 しかし,ここでは,人手による作業にかわるシステムを実現するという立場から, 現用のデータベースにおいて 専門のインデクサが抽出したキーワード並の精度を得ることを目標とした。
さて,人手によって抽出されたものと比較する以上, 100%の精度をねらうということは意味がない。 複数のインデクサが同一の記事に対して付与したキーワードのうち 共通するものの割合が適合率の目安となる。 また実際に検索をする場合は通常複数個のキーワードを組み合せて使用するため, 利用者にとって見かけ上の精度となる検索文献の適合率,再現率はキーワード自体の適合率, 再現率*よりも増加する傾向にある。
以上の点を考慮し本システムでは人手によって抽出されたものとくらべて, 再現率70%,適合率50%を精度の目標とした。
本システムは新聞記事データベースの索引自動生成を目標として構築する。 新聞記事をキーワード抽出の対象として見ると, 論文や特許請求文などに適用されてきた手法がそのまま使えるとは限らない。 そこで.新聞記事の特性を考慮に入れ,次のような方針でシステムを設計した。
(1) 字面上の処理で抽出する。
特許清求文や論文の標題などには文型や言い回しに特徴的なものがあるが, 新聞記事は対象が多岐に渡るため文型が多様で構文と意味の解析をすることは容易ではない。 そこで,字面上の処理だけでキーワードを抽出することとする。
(2) 記事全文を対象とする。
新聞記事の見出しは,記事の内容をもれなく正確に表現する,ということよりも, 読者の注意を引くことに重点がある。 またニュースに関する知識をある程度前提として書かれている場合が多い。 このため, 見出しの中にその記事のキーワードとなるべき語がすべて含まれていることは期待できない。 したがって,記事全文を対象として解析をする必要がある。 この場合,標題や抄録などで使われる「不要語の除去」といった簡便な手法だけでは 不適当な語が多数混じってしまうため,これに代わる方法を考える。
(3) 用語の変化に適応できるようにする。
新聞記事で使われる用語は,時事用語を始めとして,新しい吉葉が非常に多い。 またキーワードとして重要な語となることの多い人名や会社名などを もれなく辞書に登録しておくことも現実的ではない。 このため,辞書になかった語も救済できるような拡張性が要求される。
従来の人手によるキーワード抽出作業は,キーワード辞書を参照しておこなわれていた。 この辞書はキーワードとなる語を集めたもので, 専門家の過去の経験と知識を蓄積したものといえる。 本システムではこの知識を生かすためキーワード辞書による統制キーワード方式を採用した。 ここで辞書に登録されている語は名詞もしくは複合名詞とする。 実際のシステムでは名詞句をキーワードとする場合もまれにあるが,ここでは考えない。
次に,キーワードとなる語は必ずしも原文中に含まれているとは限らない。 このような揚合,インデクサは文中の語から類推してより適切なキーワードを見いだすわけである。 この機能の械械化を図るため,詣の概念的包含関係, 類似関係などを定めた辞書(シソーラス)をもちいる。 また,固有名詞などのように相互関係を持たない語は 「重要語辞書」と呼ぷ単純な辞書に登録することにした。
| たとえば.シソーラスに,「コンピュータ」の同義語として「電子計算機」が, 上位語として「電子機器」が登録されているとする。 文中に「電子計算機」が出現した場合, キーワード候補として「コンピュータ」と「電子機器」が抽出される。 |
以上から,本システムでは原文から名詞を抽出してキーワード辞書と照合し, 一致した語を抽出すればよいことになるが,なおいくつかの問題がある。 以下,主な問題点について論じる。
(1) 原文中から抽出された名詞が複合名詞の場合, キーワードが複合語内に埋もれている場合がある。 これを抽出するため,ここでは接辞辞書をもちいて接頭,接尾語の除去をおこなう。
|
(2) 原文を対象とするため, 記事の内答および長さによっては抽出される語数が多過ぎることがある。 そこで,ここでは抽出されたキーワード候補を絞りこむ際優先順位が決定できるよう, 出現回数や現文中の出現位置などの情報を付与することとした。
(3) 辞書が完備されていない場合,抽出したキーワード候補の品質が低下する。 そこでここでは,候補とならなかった名詞の中から, ストップ・ワード辞書をもちいて不適当な語を除き, 残された語を分析不能語として出力することにした。
| ストップ・ワードの例=昨日,場合,中 |
分析不能語には, 接辞語からその語のもつ属性(人名,企業名など)が推定できるときはその属性を付与する。 これをもとに,人手による後編集で,分析不能語の中からキーワードを選びだすことができる。 また,そのとき選択した語をキーワード辞書に登録していけば辞書の拡充が容易におこなえる。
(4) 前項の分析不能語出力機能をもちいて, キーワード辞書のない場合も適当な量の原文の中からキーワードとなる語を選びだし, 辞書を作ることができる。 本システムでは,これを支援する辞書作成プログラムも試作した。
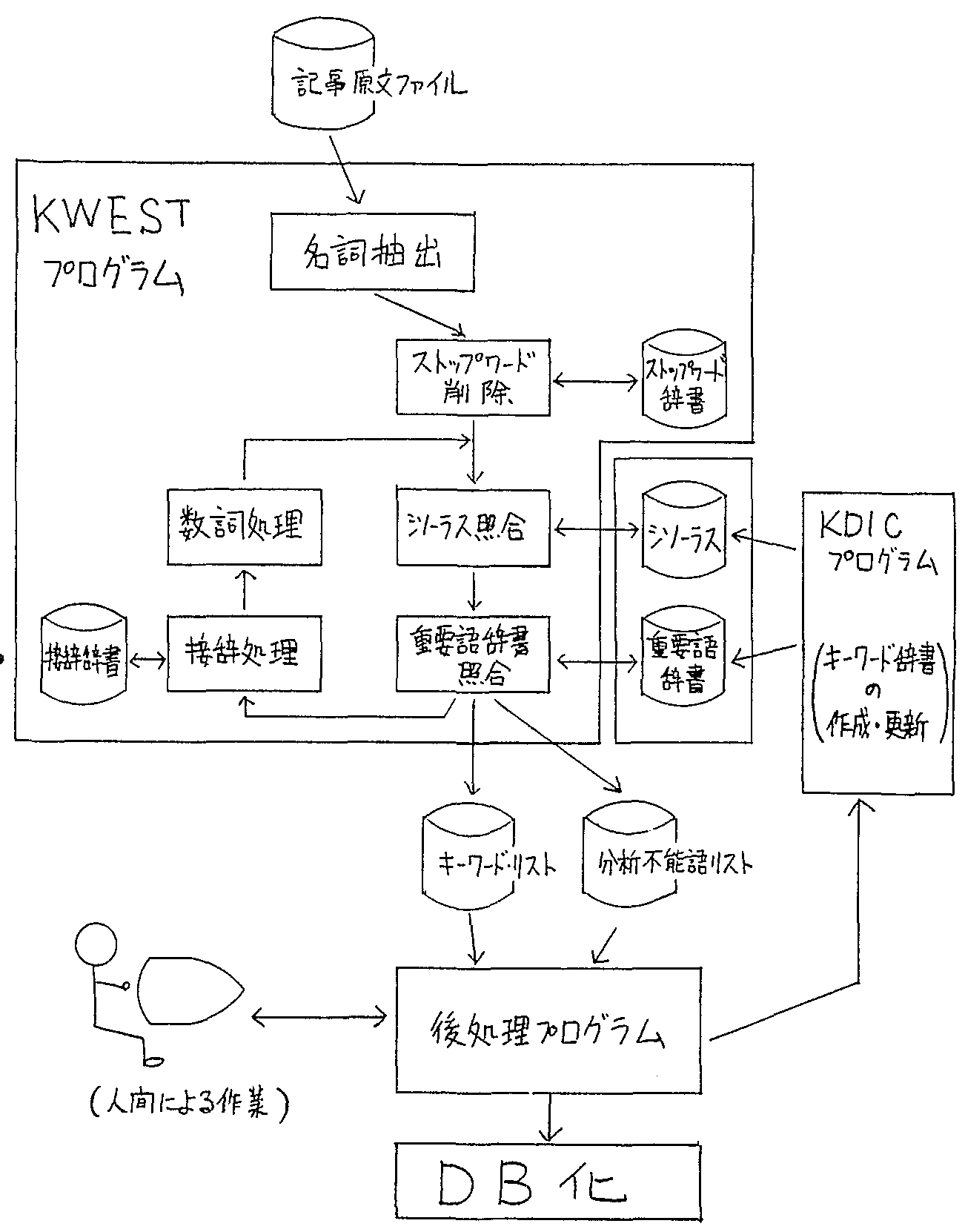
本システムは,図1に示すとおり, 入力原文からキーワード候補を抽出するプログラム(KWEST), キーワード辞書の作成をするプログラム(KDIC), および最終的にキーワード候補を人手によって選択する後処理プログラムからなる。
|
|
従来,日本文の単語解析法として,単語の接続カテゴリと分割数最小法, 係り受け解析法を併用した精度の良い(99%以上)方法が 提案されている[3]。 この方法をもちいれば文中から正確に名詞を抽出することができる。 しかし,この方法は本システムにおいて着目している名詞以外についても 精密な解析をするものであり,処理コストがかかるため, ここでは助詞の働きに着目した選択的名詞解析法を考案した。
この方法は,記事作者の題材の取り上げ方が助詞の使い方に表われることに基づいており, 助詞の種類で名詞のキーワード候補へのなりやすさを判定するものである。
[基本ルール]
「漢字列」または「漢字列+ひらがな1字」の次に「は・も・が・を・に・へ」か 「句読点」があらわれるものだけを抽出する*。
[補助ルール]
1)「XのY」,「XやY」における漢字列Xの取捨は,漢字列Yに従うものとする。
2)漢字列に「で」,「と」が連接しているときは無条件で捨てる。
これにより,重要な名詞のみが選択的に抽出されるため, 後の名詞解析に渡される語の数も少なくなり,一層の高速化が可能となる。
索引語自動生成をはじめ自然言語処理全般に,処理速度を高速化しようとするときに, 最も大きな要因となるのが辞書検索にともなうディスク・アクセスの時間である。 実用的なシステムをめざせば,それにともない辞書の巨大化は避けられず, ディスク・アクセスの高速化の重要性が増す。
本章では.ディスク・アクセス回数の削減の方法および高速辞書アクセス方式についてのべる。
(1) 辞書アクセス順序の最適化
本システムでは,シソーラス,重要語辞書,ストップ・ワード辞書, 接辞語辞書などを順に検索していく。 辞書に登録されていた語についてはそれ以降の検索はおこなわれない。 したがって,ヒットする可能性の高い辞書から順に照合していき, 検索する語数を早めに減らしていくと効率が良い。
ストップ・ワードは,辞書が比較的小規模(7000語程度)であっても, 抽出された名詞の30〜40%の高いヒット率になるため,これを最初におこなうこととした。 そのあとは,図1に示すように,接辞語辞書,シソーラス,重要語辞書の順でアクセスする。
(2) インデックス辞書アクセス
抽出された名詞は,各辞書と照合していくが, 実際にいずれかの辞書にヒットする割合はわずかである。 そこでストップ・ワード辞書,接辞辞書,シソーラス,重要語辞書の各辞書ごとに, 先頭1文字を見出しとするインデックス・ファイルを用意し,これを主記憶上に置く。 このインデックスを調べることにより,辞書に登録されていない語の大部分は, 辞書本体へのディスク・アクセスによる確認が不要となる。
(3) 一括辞書アクセス
抽出された名詞をコードの昇順にソートしておき,この順に辞書引きをする。 辞書もやはり昇順にソートされているので,ファイルヘのアクセスはブロック単位でおこなう。 一回のアクセスで近傍にある辞書項目はまとめてロードされるため, ディスク・アクセス回数を減らすことが可能となる。
辞書を引きにいく名詞が,コード順でまばらに散らばっているときは, (2)の方法の効果により,無駄なディスクアクセスをせずにすむ。 また,ある付近に集中している場合は(3)の効果により一括してアクセスすることができる。
選択的名詞抽出処理法により,従来の形態素解析法の約60倍の速度で,名詞抽出が可能となった。 また,辞書アクセス法の改善により, 名詞を原文の出現順にISAMにより辞書引きする方法に比べて ディスクアクセス回数を1桁程度削減できる見通しを得た。 これにより,数百記事を処理したとしても,即日処理でき, コストも従来の人手による方法にくらべ,大幅に削減できる。
また,キーワード精度については,辞書に依存するところが大きい。 しかし,固有名詞以外の一般語キーワードの再現率については ほぼ目標値が達成できる見通しが得られた。 固有名詞キーワードについては,すべての固有名詞を辞書に登録しておくことは困難であるが, 接辞によるカテゴリ推定により,分析不能語の中から容易に抽出することが可能である。
選択的名詞抽出法,接辞処理,高速辞書アクセス法などにより, 実用上十分な速度と精度をもった索引語自動生成システムを実現することができた。
選択的名詞抽出法では,助詞の働きに着目し, きわめて単純な処理で重要度の高い語だけを抽出することが可能となった。 接辞処理では,複合語化した名詞を掘りだすとともに, 辞書に登録されていない語についても,抽出できるようになった。 また,高速辞書アクセス法では,実用をめざした大規模な辞書でも, 高速に検索が可能となり,処理時間の短縮化が可能となった。
評価精度のうち,再現率は,後処理のひとつである自動絞りこみに依存してくる。 適合率を下げないよう,不要な語だけを捨てるような方法が必要となるわけだが, これについては検討中である[4]。 今後さらに,十分な辞書をそろえた実際の環境で評価・改良をしていく予定である。
本研究を進めるにあたり,有益な助言と御討論を頂いた, 当研究所村岡洋一データ通信方式研究室長,ならびに池原悟調査役に感謝します。
| 再現率= | 抽出されたキーワード中の適切なキーワードの数 |
| -------------------------------------------------------------------- | |
| 抽出された全キーワード数 | |
| 適合率= | 抽出されたキーワード中の適切なキーワードの数 |
| -------------------------------------------------------------------- | |
| 本来抽出されるべきキーワード数 |