| 白井 諭 | 井上 健 | 中西 暉 | 真田英彦 | 手塚慶一 | ||||
| Satoshi SHIRAI | Takeshi INOUE | Hikaru NAKANISHI | Hidehiko SANADA | Yoshikazu TEZUKA |
| 1. まえがき | |
| 2. モデル設定 | |
| 3. 処理ホスト決定アルゴリズム | |
| 4. 伝送コストの計算 | |
| 5. 各方式による伝送コスト | |
| 6. 処理負荷の分散 | |
| 7. 故障の影響 | |
| 8. P,Dの存在地点がターミナルの位置に依存している場合の特性 | |
| 9. 格子形ネットワークにおける伝送コスト | |
| 10. あとがき | |
| 文献 |
分散処理は遠隔処理からの自然な発展形態である。 即ち,第一段階としては遠隔端末からのリモート・エントリを中心こした集中処理形態であり, 次いで第二段階は知能端末によるローカル処理と中央計算機による集中処理であり, これらを経て, やがてデータベースの分散を中心とする本格的な分散処理形態へと進展してきている。 この第三段階への発展は自然ではあるが 技術的観点からは多くの未知の要素をはらんだ新たな発展段階であるといえる。
分散処理システムを構成するに当って,分散すべき要素としては,
分散処理システムがユーザにとって経済性,効率, 有効利用率などの面で大きな利点を持っているようにみえるにも拘らず現実の発展が遅いのは, 新技術の採用という極めて危険な冒険が必要であり, 集中処理コストと未知の分散処理コストの比較という 困難な予測も敢えて行わねばならないからである。
このような多くの困難が予想されるにも拘らず分散処理システムの発展は不可避とみられる。 その主な原因は経営上の多くのニーズと運用上の利点にある。 例えば,経営上のニーズには,
分散処理の発展は未発達段階では遅遅としたものであろうが, このような背景のもとに分散処理に必要な技術的道具を提供することは重要な意味を持っている。 本橋では1つのホストで処理を行いえないジョブが現われた際の処理を担当するホストの決定法と 負荷分散や故障に強いシステムはどのようなネットワーク・トポロジを持てばよいかの 2点について検討を進めていくことにする。
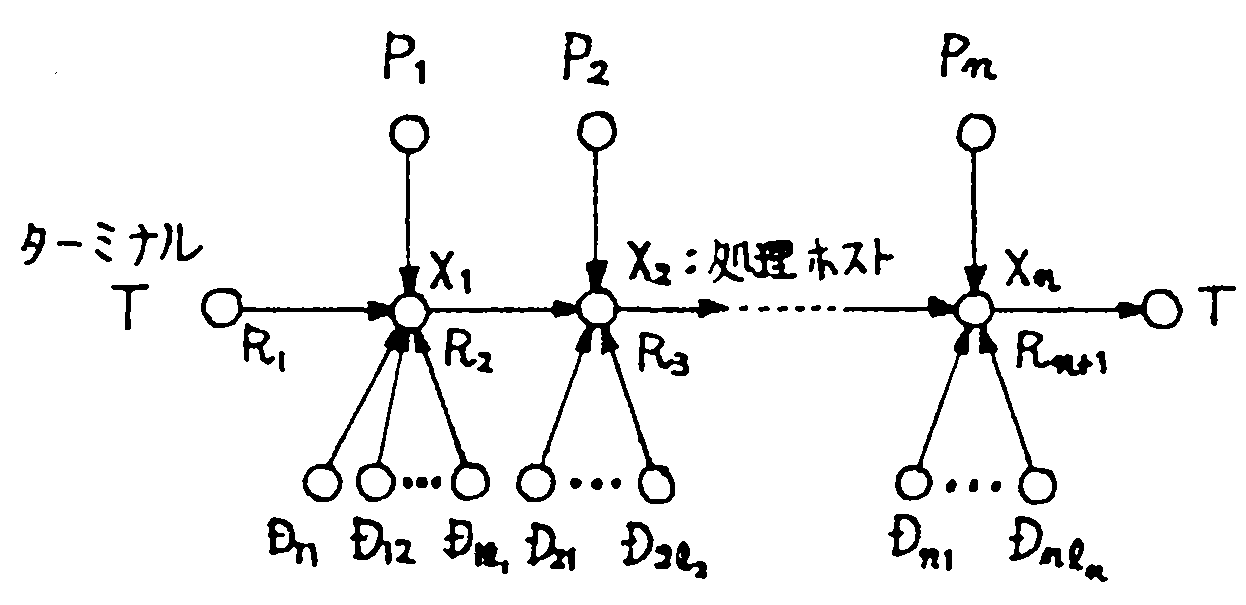
分散処理システムに依頼されたジョブの処理に必要な情報として, ジョブ・トランザクションR,アプリケーション・プログラムP,データDの3者を考える。 そしてジョブを図1に示すように, サブジョブがその実行にそれぞれ特定のPとDを必要とするサブジョブの直列処理要求とする。 目的関数としては情報の総伝送コスト,即ち距離及び情報量に比例すると仮定する。 なお,実際に処理を行うに当り情報の位置を知るためのディレクトリ問題があるが, ここでは一応解決されていて容易に位置を知ることができるものとする。 また,各ホストにおける処理コストの違いについても考えない。
|
|
1つのホストにR,P,D3者が同時に存在しない場合, サブジョブの処理ホストをいずれに選んでも情報の伝送を行わねばならないが, どの情報の伝送を許すかにより,基本均には次の3方式が考えられる。
| (A) 渡り | 歩き方式:Pを保持するホストを処理ホストとする方式 | |
| (B) 呼び | 寄せ方式:Rを保持するホストを処理ホストとする方式 | |
| (C) 適応 | 方式:R,P,D共に伝送しうるものとし, それぞれの位置を考慮して最も有利と思われるホストを処理ホストとする方式 |
(C)による最適解はダイナミック・プログラミング(DP)の手法により求められるが, 計算が複雑であるので,簡易手法(C1)を提案する。
| 推定法:あるサブジョブを処理したホストからみて, 伝送コストが最小となるように次のサブジョブの処理ホストを決定する。 なお,最後のサブジョブの処理ホストは ターミナルの位置も考慮したうえで決定する。 |
(A)(B)(C1)の式による表現は次のとおりである。
| Xi :サブジョブiの処理ホスト(1 ≦ i ≦ n) | |
| | Ii | :情報 Ii の大きさ | |
| HIi:情報 Ii を保持するホスト | |
| d(Hi, Hj):ホストHi, Hj 間の距離 |
| (A) Xi = HPi | (1) | ||||||
| (B) Xi = HRi = HRi-1 = … = HR1 = Tターミナル・ホスト | (2) | ||||||
| (C1) Xi = { Hj | | min j | ( | Ri | d(Xi-1, Hj) + | Pi | d(HPi, Hj)+ | Σ li | | Dili | d(HDili,Hj) [ + | Rn+1 | d(Hj,T) ]最終段のみ加える | (3) | ||
(A)或いは(B)では,処理ホストはP,Dの位置が与えられたなら一意的に決定されるので, それぞれ式(4),式(5)により計算できる。 各サブジョブの処理ホストの位置が互いに独立に決定されることを考えれば, 各サブ・ジョブの処理コストを個別に計算し, それらを組み合わせることによりP,Dが色々な位置にあるときの 平均コストを容易に計算することができる。
ところが(C)では全てのP,Dの位置が処理ホストの位置に影響してくるので計算は煩雑である。 (C1)では原則的には式(6)で計算されるが, この場合はみかけ上1つ前の処理ホスト位置に影響をうけるだけなので, 1つ前の処理ホストの位置,即ちRの存在地点をパラメータとして与えることにより, 各サブジョブの処理コストを独立に計算し,それらを組み合わせることにより, 比較的容易に平均伝送コストを求めることができる。 しかしながら,(DP)にはこのような方法も適用できないため, シミュレーションによって求めることにした。 次節以降で示す(DP)による最小伝送コストはサンプル数500でシミュレーションしたものである。 なお,(A)(B)(C1)の伝送コストを同様にシミュレーションによって求めてみたところ 計算結果と一致したので,(DP)の精度も十分高いと思われる。
伝送コストの計算式
| (4) | ||||||||||||||||||
| (5) | ||||||||||||||||||
| (6) | ||||||||||||||||||
| 平均伝送コストの計算式 | P(Ii,Hj):情報IiがHjに存在する確立; m:ネットワークのノード数 | ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||
| (7) | ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| (8) | |||||||||||||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
| (9) | ||||||||||||||||||||||||||||||||||||||||||||||||||||
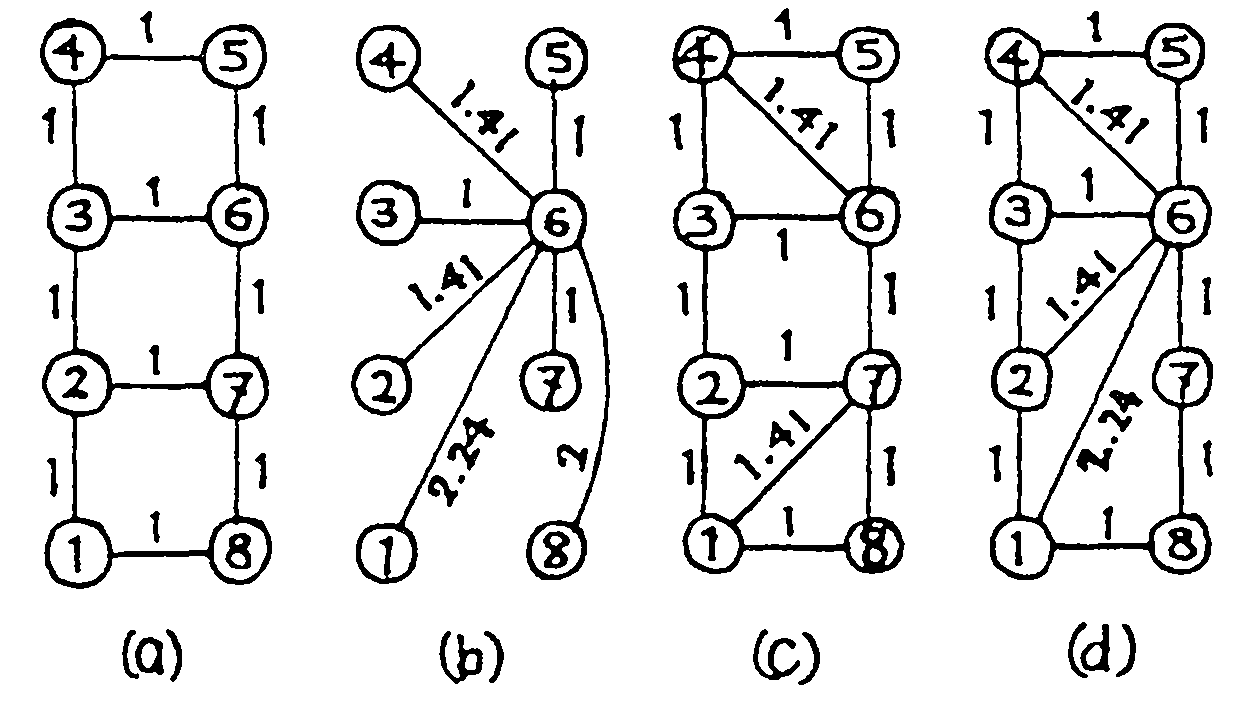
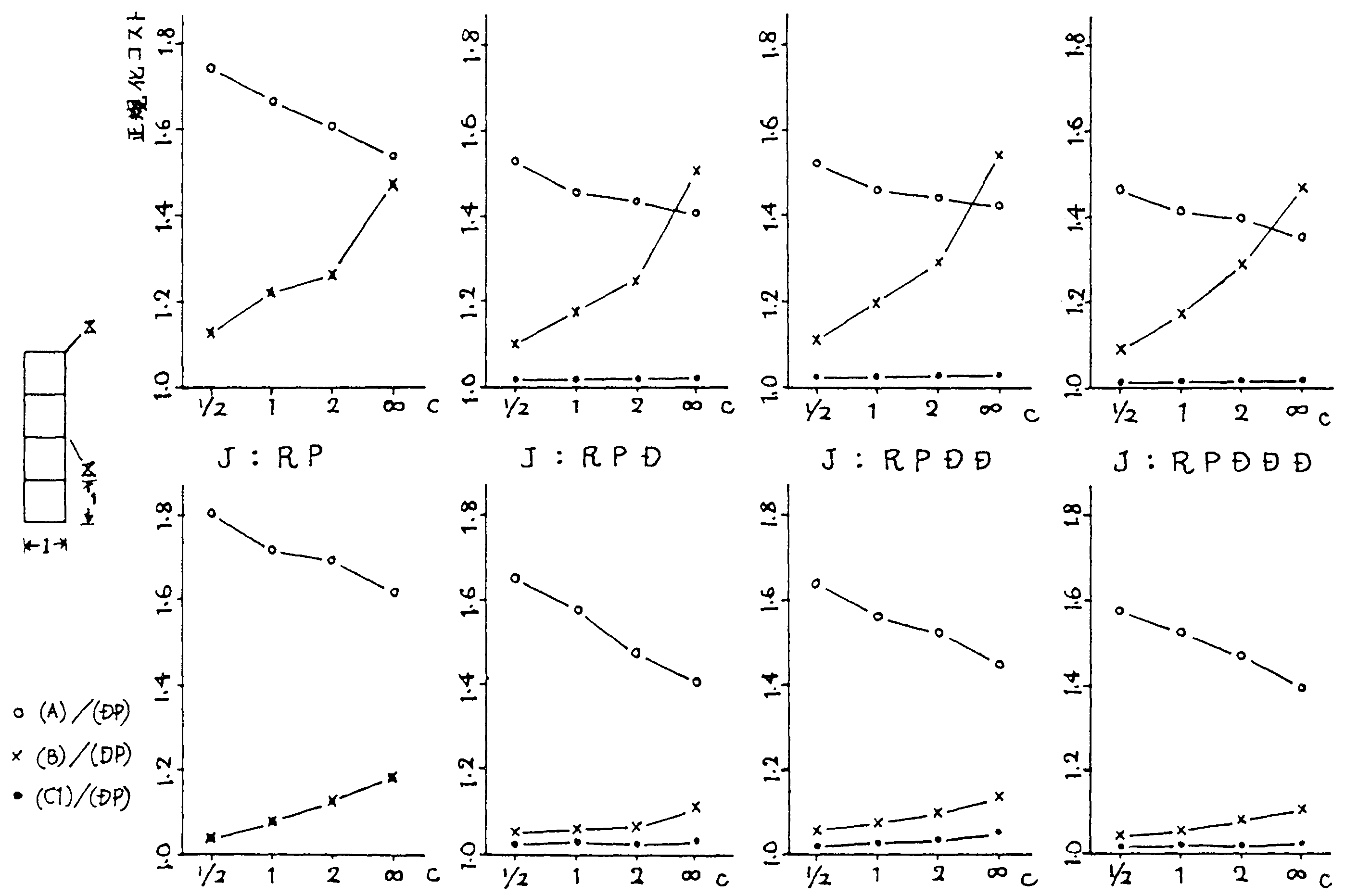
ジョブはサブジョブ(R,P各1個とD2個を必要とすると仮定)の10段で, | Ri | = | Dij | = 1, | Pi | = k (kはPの大きさの平均とDの大きさの平均との比)とし, 図2に示す4種類の8ノード・ネットワーク形態について (A)(B)(C1)の伝送コスト及び(DP)の最小伝送コストを求めた。 P,Dの存在地点はターミナルの位置に関係なく各ノードとも等確率とした。 計算結果は図3のとおりであるが,ここで(DP)は前述したようにシミュレーションによる値である。
|
(DP)を基準にした(C1)のコスト増は k=1 付近で最大となるが高々7%で, また(A)(B)のようにネットワーク形態,ターミナル位置にほとんど影響されない。
(A)と(B)をうまく使い分けてもある程度の成果があげられる。 即ち,k が閾値より小さければ(B)で,大きければ(A)で処理ホストを決定すればよい。 しかしながら,閾値はネットワーク形態, 端末位置などによって変わるのでその都度決定してやらねぱならない憾みがある。
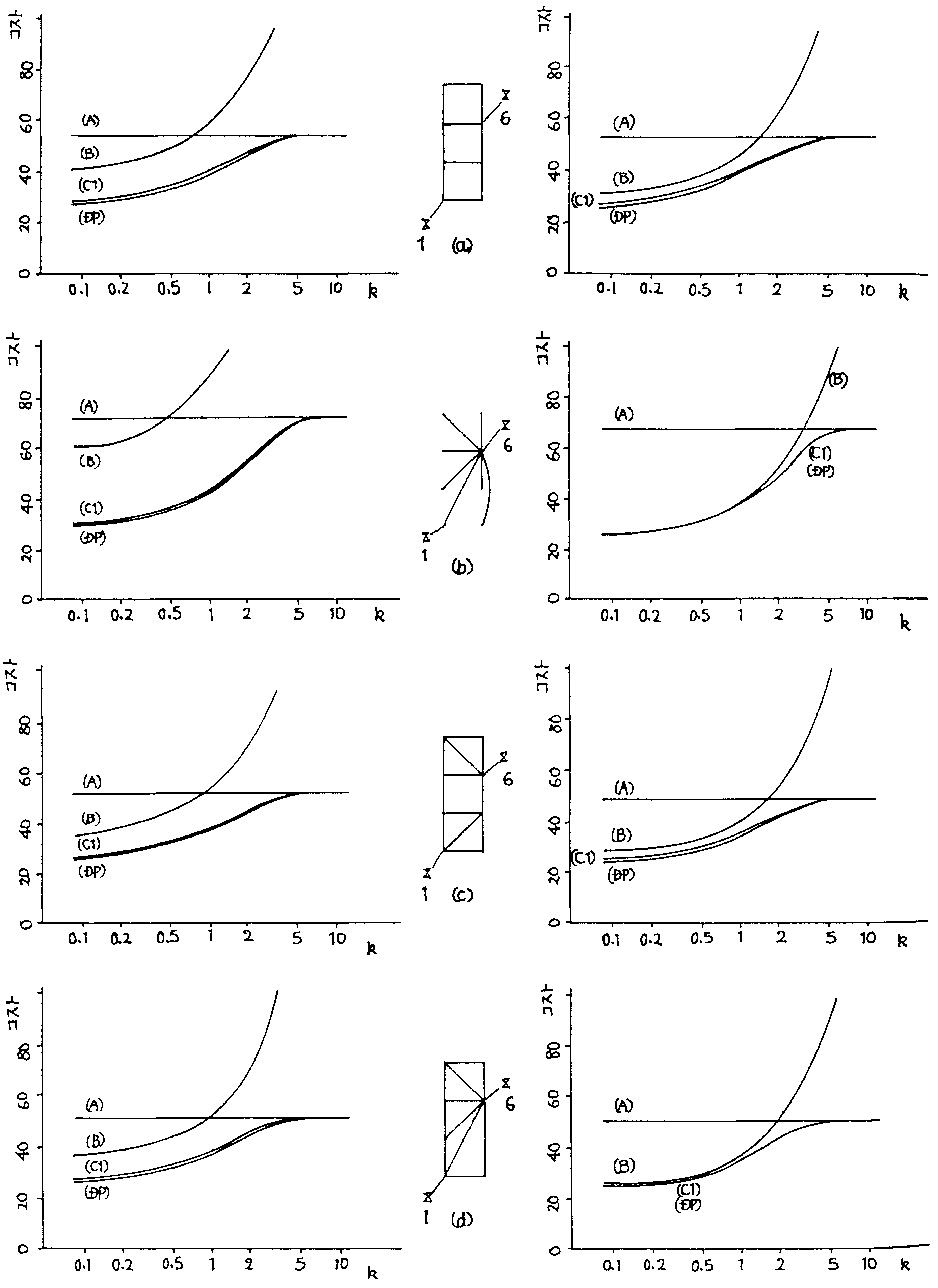
|
前節の検討で(C1)が優れていることがわかったので,その特性について検討を加える。 前節のようにPDは網内に一様分散していると仮定し, 各端末からのジョブ依頼の頻度が等しいとしたとき, サブジョブの処理負荷が網内にどのように分布するかを表1に示す。 中央付近のホストに処理が集中する傾向があるが, ネットワークの形態によりその度合はかなり異っていることがわかる。 必要とする情報が網内に分散している限りこの傾向が大きく変化するとは考えられないので, 負荷を分散しかつ伝送コストを小さく押えるためには ネットワークの形態が(b)或いは(d)では不利であるといえる。
| 網\ホスト | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| (a) | 5.24% | 19.76 | 19.76 | 5.25 | 5.25 | 19.76 | 19.76 | 5.25 |
| (b) | 2.65 | 2.65 | 2.65 | 2.65 | 2.65 | 81.45 | 2.65 | 2.65 |
| (c) | 7.20 | 11.76 | 11.76 | 7.20 | 2.93 | 28.11 | 28.11 | 2.93 |
| (d) | 8.66 | 12.30 | 9.30 | 6.00 | 3.30 | 45.11 | 10.24 | 5.09 |
これまでは全てのホストが正常に稼動している場合を想定して検討を行ってきたが, 故障が発生した際に特性がどのように変化するかも知っておく必要がある。 各ホストが故障した際,伝送コストがどのように変化するかを ターミナルがホスト1及びホスト6の場合について示したのが表2である。 1ホストが故障したために伝送コストがどれだけ増えたかをみると, (a)では4%,(b)では46%,(c)では6%,(d)では14%がそれぞれの最大値である。
| 網\端末\故障ホスト | 全稼動 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| (a) | 1 | 42.97 | 43.02 | 44.29 | 43.93 | 42.83 | 42.83 | 43.66 | 43.85 | 42.90 |
| 6 | 41.29 | 41.15 | 43.00 | 42.24 | 41.16 | 41.15 | 41.98 | 42.29 | 41.15 | |
| (b) | 1 | 41.05 | 43.60 | 43.81 | 43.88 | 43.81 | 43.88 | 61.61 | 43.88 | 43.71 |
| 6 | 43.57 | 39.12 | 39.27 | 39.34 | 39.27 | 39.34 | 57.92 | 39.34 | 39.16 | |
| (c) | 1 | 39.77 | 40.03 | 40.33 | 40.17 | 39.74 | 39.73 | 40.91 | 41.26 | 39.79 |
| 6 | 38.08 | 38.02 | 38.34 | 38.47 | 38.02 | 38.03 | 40.45 | 39.42 | 38.03 | |
| (d) | 1 | 40.06 | 40.32 | 40.80 | 40.42 | 40.06 | 40.01 | 43.59 | 40.18 | 40.14 |
| 6 | 37.66 | 37.57 | 38.10 | 37.92 | 37.63 | 37.61 | 42.96 | 37.69 | 37.69 | |
また,処理負荷がどのように変化したかをみると, ネットワークの端に位置するホストの故障はもともと負荷が小さいために影響も少いが, 中央付近のホストでは大きい。 表3にホスト6が故障した時の処理負荷の分散状況を示す。 表1との比較でわかるように,故障したホストの周辺ホストが処理を代行する模様である。 もしホストが平常時の処理負荷,即ち表1に示した数値に合わせて設計されているとすれば, (b)或いは(d)の網ではホスト6の故障により周辺部で致命的混乱状態に発生すると考えられる。 即ち(C1)の利点をうまく使うためには ネットワーワが集中網的なものより分散網的なものの方が有利であるといえる。
| 網\ホスト | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| (a) | 5.64% | 22.62 | 24.94 | 6.18 | 8.61 | 故障 | 26.58 | 5.42 |
| (b) | 5.88 | 6.39 | 24.59 | 6.39 | 24.59 | 故障 | 24.59 | 5.95 |
| (c) | 7.71 | 13.99 | 16.95 | 10.14 | 6.61 | 故障 | 41.47 | 3.14 |
| (d) | 10.71 | 20.64 | 19.99 | 9.36 | 10.97 | 故障 | 22.15 | 6.17 |
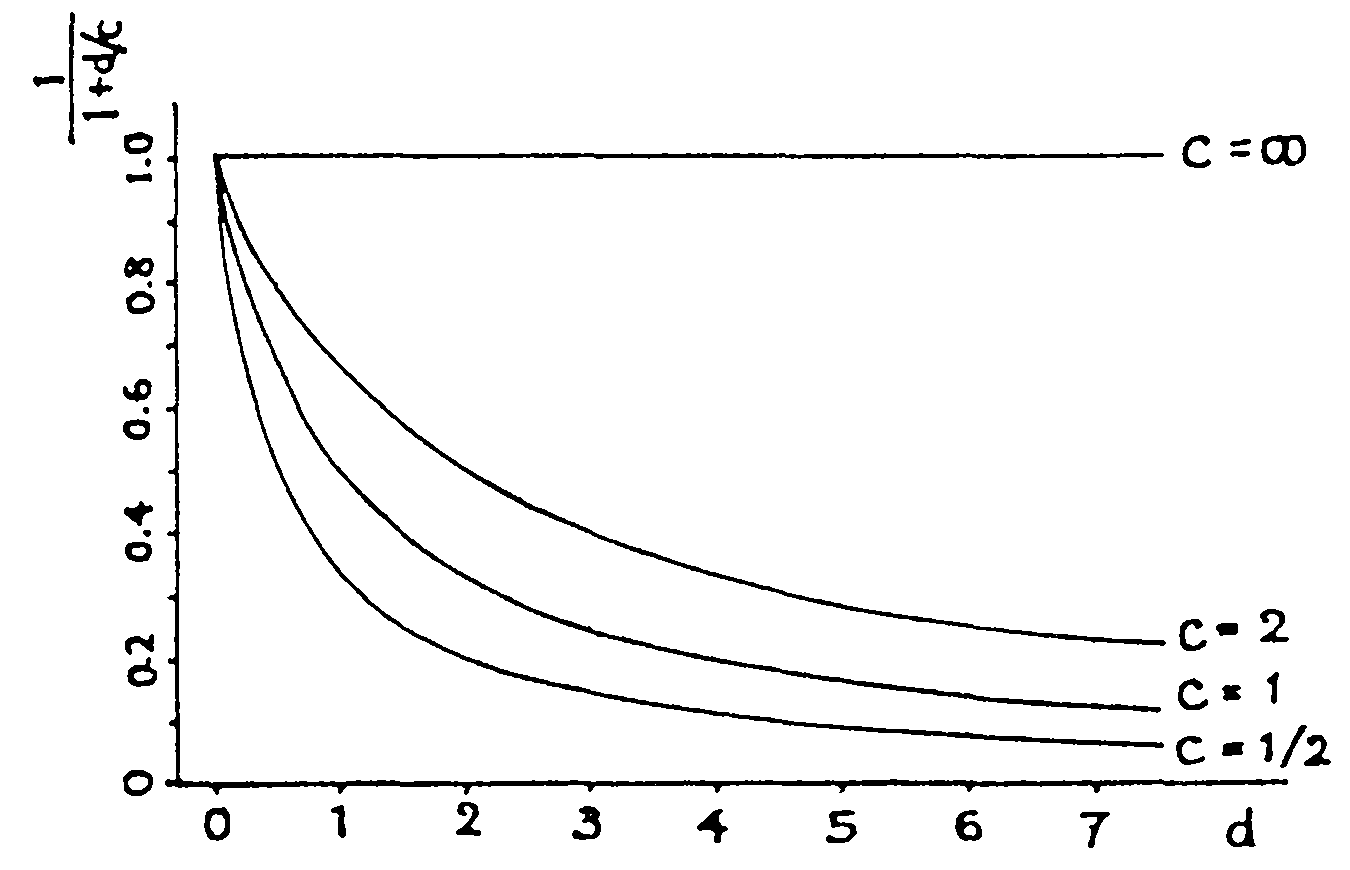
前節までの検討で分散網的トポロジを持つネットワークに1段推定法を適用すれば, 伝送コストを低く押えたまま処理負荷が分散することがわかった。 その際,ジョブの処理に必要な情報がネットワーク内に一様に分散していると仮定したが, 実際にはその使用頻度が高いノードの近くに情報が置かれていると考えるのが自然である。 そこでターミナル・ホストから距離dだけ離れたノードに P或いはDが存在する場合を表現する量として 1/(1+d/c) を用いた。 ここでcはターミナルとP,Dの存在地点の間の依存性を示す係数で, c=∞のときにネットワーク内一様分散を, c=0のときに1ノードに集中している状態を表現するものである。(図4)
|
図5にこの 1/(1+d/c) によってP,Dが分散している時の(A)(B)(C1)の伝送コストを (DP)による最小伝送コストで正規化した値で示す。 ネットワークは分散網的トポロジをした10ノードの梯子形で,|R|=|P|=|D|=1, またサブジョブは10段であるが各サブジョブに必要とされるDの数も0〜3に変化させてみた。 図からわかるように情報がターミナルに依存すれば (B)(C1)では(DP)による最小伝送コストに近づいていくのがわかる。 (A)は左上りの特性を示しているがこれも伝送コストの絶対値は減少している。
|
図6は14ノード梯子形のネットワークについての計算結果である。 10ノードの場合と比較すると,網が拡大したために伝送コストの絶対値は増加しているが, (DP)で正規化した結果をみると特性自体はよく似ている。
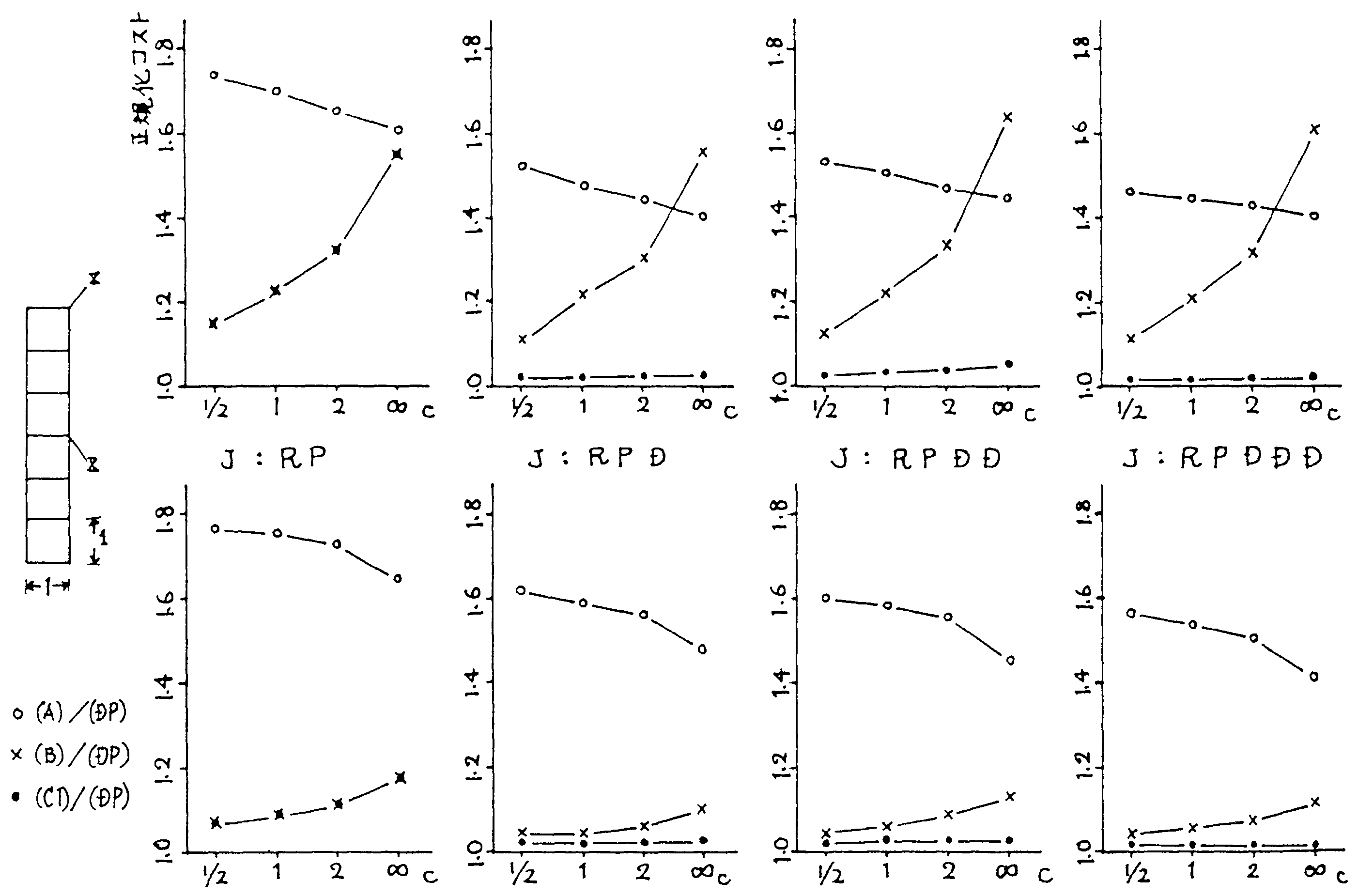
|
前節の検討によってネットワークが直線的に拡大しても ほとんど特性に変化のないことがわかったが, 本節では平面的な拡大に対してはどうか簡単に調べてみる。 図7は9ノードと16ノードの場合の(A)(B)(C1)の伝送コスト 並びに(DP)の最小伝送コストを示したものである。 いずれの場合も図3の場合と全く同じ傾向を示している。 従って,平面的に拡がったネットワークのような場合でも同じことがいえる。
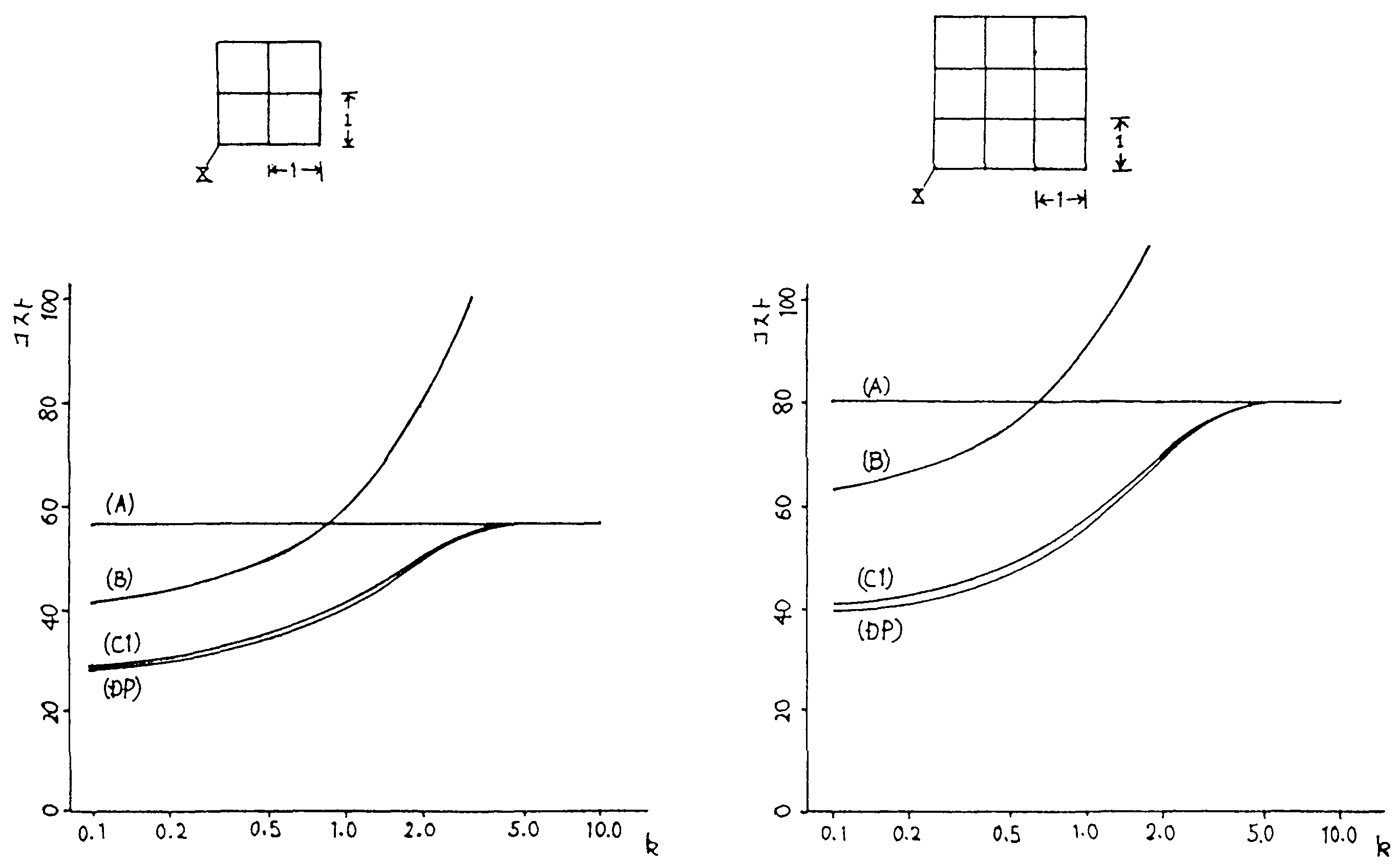
|
1ホストで完全に処理が行えないジョブが依頼されると 分散処理システムではその処理ホストを決定しなければならない。 ジョブが図1のように直列処理を必要とする場合, ダイナミック・プログラミングを用いれば最小伝送コストを達成できるが, 実際には処理を開始する前にどの情報が必要であるか知りうる保障はなく, また手続自体も煩雑である。 ところが1段推定法であれば逐次処理を行いながら処理ホストが決定でき, ネットワーク・トポロジ,端末位置,情報の分散状況,サブジョブの形に拘りなく 伝送コストを十分低く押えられるので実用的に可能な方法であるといえる。 このような観点と得られた結果のすべてに共通する特性からみて, 1段推定法はダイナミック・プログラミングによる最適解の近似解として 十分なものであると結論できる。 一方,1段推定法に対しては式(9)により計算式が得られ, 容易に基準となる最適値の近似値が計算できる。
さらに,渡り歩き方式および呼び寄せ方式を選択して適用する場合に 払わねばならない伝送コストの増加が, 端末がネットワークの中央付近にある場合では高々15%, 端に位置する場合には図2(b)のような極端なものを除けば高々50%に押えられている。 従って,この程度のコスト増が許容範囲であるなら, k=1 付近で両者を切り換えればより迅速に処理ホストを決定することができる。
また, 分散網的なトポロジを持ったシス〒ムは負荷がよく分散していて故障に強いことがわかった。
一般に, 分散処理システムでは情報の伝送が少なくて済むような配置に設計されていると思われるが, このような状態がいつまでも継続するとは期待できないため, ここで提案するような処理ホスト決定法が必要になると考えられる。